STAMP
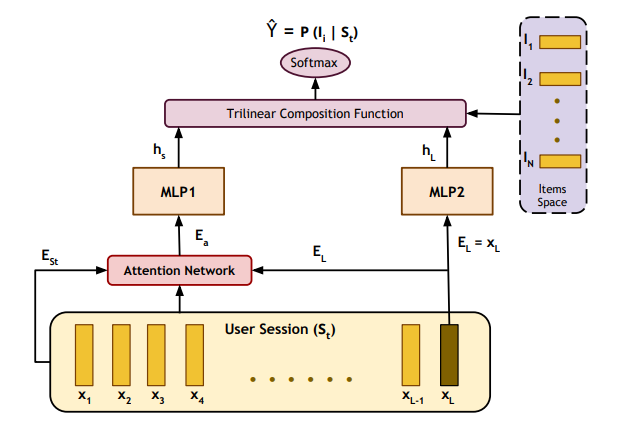
STAMP is one of the approaches that replaces complex recurrent computations in RNNs with self-attention layers (Liu, Zeng, Mokhosi, and Zhang, 2018). The model presents a novel attention mechanism in which the attention scores are computed from the user’s current session context and enhanced by the sessions’ history. Thus, the model can capture the user interest drifts, especially during long sessions and outperform other approaches like GRU4Rec (Hidasi, Karatzoglou, Baltrunas, and Tikk, 2015) that uses long term memory but still not efficient in capturing user drifts. Figure 4 shows the model architecture where the input is two embedding vectors (EL, ESt ). The former denotes the embedding of the last item xL clicked by the user in the current session, which represents the short term memory of the user’s interest. The later represents his overall interest through the full session clicked items. ESt vector is computed by averaging the items embedding vectors throughout the whole session memory (x1, x2, ..., xL). An attention layer is used to produce a real-valued vector Ea, where this layer is responsible for computing the attention weights corresponding to each item in the current session. In this way, we avoid treating each item in the session equally important and paying more attention to only related items, which improves the capturing of the drifts in the user interest. Both Ea and EL flow into two multi-layer perceptron networks identical in shape but have separate independent parameters for feature abstraction. Finally, a trilinear composition function, followed by a softmax function, is used for the likelihood calculation of the available items to be clicked next by the user and to be used in the recommendation process.