DQN
The Q-learning component of DQN was invented in 1989 by Christopher Watkins in his PhD thesis titled “Learning from Delayed Rewards”. Experience replay quickly followed, invented by Long-Ji Lin in 1992. This played a major role in improving the efficiency of Q-learning. In the years that followed, however, there were no major success stories involving deep Q-learning. This is perhaps not surprising given the combination of limited computational power in the 1990s and early 2000s, data-hungry deep learning architectures, and the sparse, noisy, and delayed feedback signals experienced in RL. Progress had to wait for the emergence of general-purpose GPU programming, for example with the launch of CUDA in 2006, and the reignition of interest in deep learning within the machine learning community that began in the mid-2000s and rapidly accelerated after 2012.
2013 saw a major breakthrough with the paper from DeepMind, “Playing Atari with Deep Reinforcement Learning”. The authors coined the term DQN or “Deep Q-Networks” and demonstrated the first example of learning a control policy directly from high-dimensional image data using RL. Improvements quickly followed; Double DQN and Prioritized Experience Replay were both developed in 2015. However, the fundamental breakthrough was the algorithm presented in this chapter combined with a simple convolutional neural network, state processing, and GPU training.
Architecture
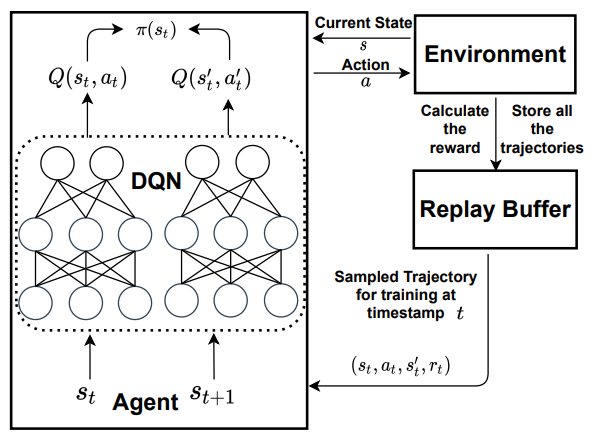
Algorithm
