MIAN
MIAN stands for Multi-Interactive Attention Network. It aggregate multiple information, and gain latent representations through interactions between candidate items and other fine-grained features.
research paper
In the Click-Through Rate (CTR) prediction scenario, user's sequential behaviors are well utilized to capture the user interest in the recent literature. However, despite being extensively studied, these sequential methods still suffer from three limitations. First, existing methods mostly utilize attention on the behavior of users, which is not always suitable for CTR prediction, because users often click on new products that are irrelevant to any historical behaviors. Second, in the real scenario, there exist numerous users that have operations a long time ago, but turn relatively inactive in recent times. Thus, it is hard to precisely capture user's current preferences through early behaviors. Third, multiple representations of user's historical behaviors in different feature subspaces are largely ignored. To remedy these issues, we propose a Multi-Interactive Attention Network (MIAN) to comprehensively extract the latent relationship among all kinds of fine-grained features (e.g., gender, age and occupation in user-profile). Specifically, MIAN contains a Multi-Interactive Layer (MIL) that integrates three local interaction modules to capture multiple representations of user preference through sequential behaviors and simultaneously utilize the fine-grained user-specific as well as context information. In addition, we design a Global Interaction Module (GIM) to learn the high-order interactions and balance the different impacts of multiple features. Finally, Offline experiment results from three datasets, together with an Online A/B test in a large-scale recommendation system, demonstrate the effectiveness of our proposed approach.
Architecture
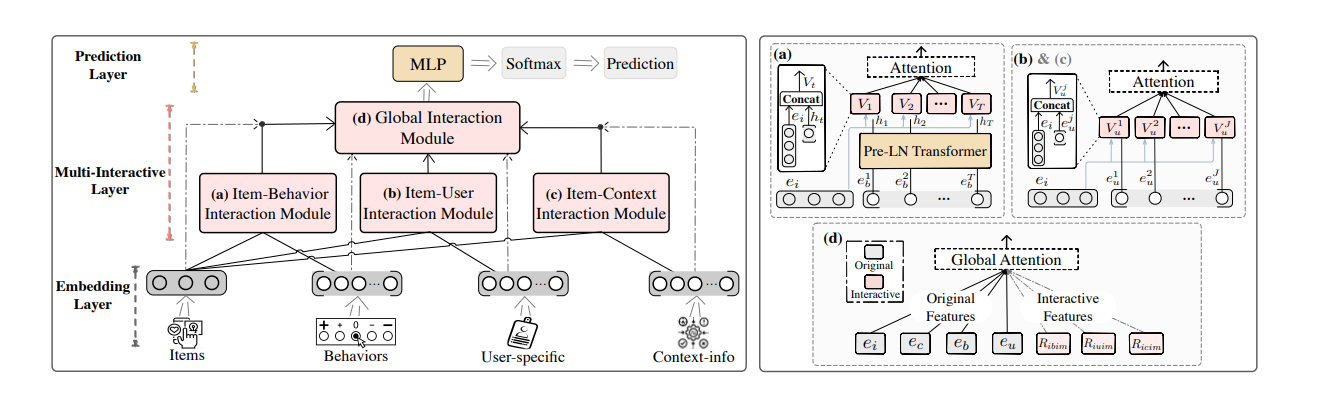
The architecture of MIAN. Overall, from the bottom up, it can be divided into three layers: 1. Embedding Layer, which projects sparse heterogeneous features into low-dimensional vectors. 2. Multi-Interactive Layer, which contains three local modules, i.e., (a), (b), (c), and a global module, i.e., (d), to learn multiple fine-grained feature interactions. 3. Prediction Layer, which contains DNN to do CTR prediction.
The network consists of a Multi-Interactive Layer (MIL) which includes three local interaction modules and a global interaction module. The first local module is Item-Behaviors Interaction Module (IBIM) that uses Pre-LN Transformer to adaptively explore the user preferences of sequential behaviors at different subspaces. The second is Item-User Interaction Module (IUIM) which aims to capture the knowledge between candidate items and the fine-grained user-specific information. Similarly, the third named Item-Context Interaction Module (ICIM) is devised to mine relations between candidate items and context-aware information. Besides, the Global Interaction Module (GIM) is designed to study and weigh the influence between the loworder features after the embedding layer and high-order features generated from three local interaction modules.
Loss Function
To estimate parameters of a model, we need to specify an objective function to optimize. For better comparison, we specify a traditional loss function for model training. The goal of the objective function is to minimize the cross-entropy of the predicted values and the real labels, which is defined as:
where ∈ {0, 1} is the ground truth and ∈ (0, 1) is the predicted probability of . Additionally, all the parameters are optimized by the standard back-propagation algorithm.