ASMG
ASMG stands for Adaptive Sequential Model Generation.
research paper
Recommender Systems (RSs) in real-world applications often deal with billions of user interactions daily. To capture the most recent trends effectively, it is common to update the model incrementally using only the newly arrived data. However, this may impede the model's ability to retain long-term information due to the potential overfitting and forgetting issues. To address this problem, we propose a novel Adaptive Sequential Model Generation (ASMG) framework, which generates a better serving model from a sequence of historical models via a meta generator. For the design of the meta generator, we propose to employ Gated Recurrent Units (GRUs) to leverage its ability to capture the long-term dependencies. We further introduce some novel strategies to apply together with the GRU meta generator, which not only improve its computational efficiency but also enable more accurate sequential modeling. By instantiating the model-agnostic framework on a general deep learning-based RS model, we demonstrate that our method achieves state-of-the-art performance on three public datasets and one industrial dataset.
The model updated from is obtained by minimizing loss on :
where is the loss on with as initialization (for recommendation tasks, the loss can be pointwise log loss or pairwise BPR loss). The initial model can be obtained by random initialization or pre-training with sufficient amount of historical data.
Now, we assume that mining the temporal trends exist in this sequence can have great potential in generating a better model for the next period’s serving. Let denote the meta generator that takes in a sequence of models until , the output model used for serving is obtained by:
where, is a sequence of models of length t from to . Note that is excluded from the input sequence, as it is obtained from random initialization or pre-training instead of regular incremental update.
To generate model that is particularly good at serving the next period, we need to ensure that past knowledge that is specially useful for the next period’s serving is extracted. To achieve this, we propose to update the meta generator by adaptively optimizing the output model towards the next period data. More specifically, let denote the parameters of , i.e., , the parameters are updated from by optimizing towards :
To ensure that the meta generator is sufficiently trained before it can be deployed for online model generation, we perform 𝜏 periods of meta generator warm-up training prior to the online deployment. During the online deployment phase, the meta generator will still need to be adaptively updated in order to keep up with the most recent sequential trends.
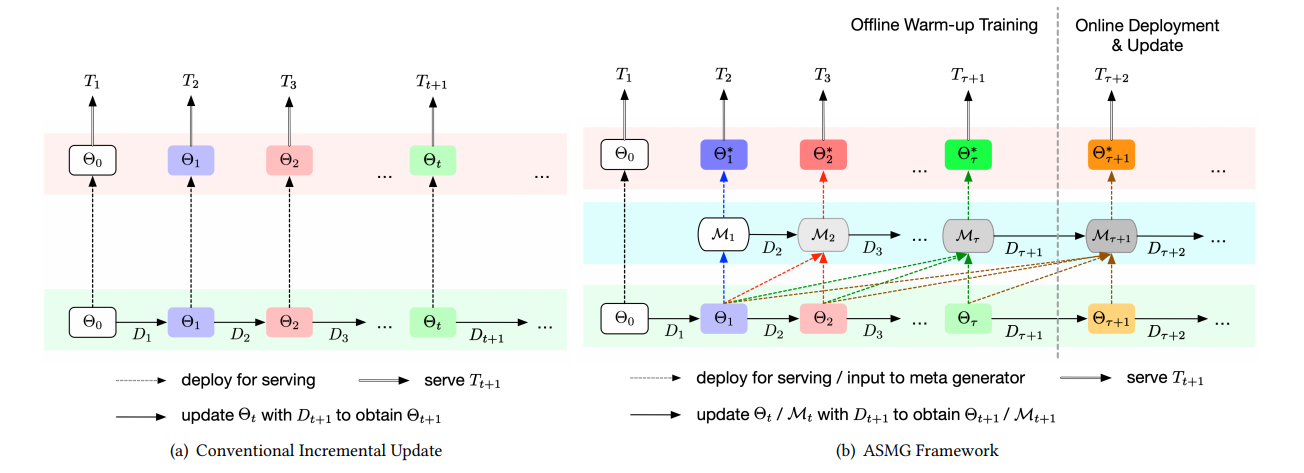
Comparison between conventional incremental update and after applying ASMG framework.
Algorithm

Variants
ASMG-GRUfull
This variant trains GRU meta generator on the full sequence of historical models.
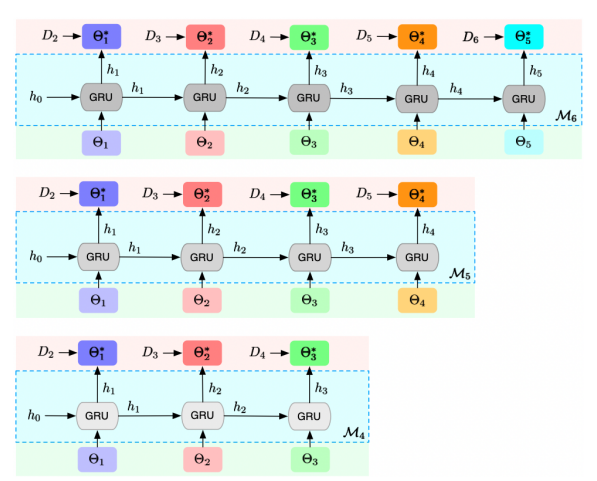
ASMG-GRUzero
This variant uses zero-initialized input hidden state for every period’s training instead of continuing on a previously learned hidden state.
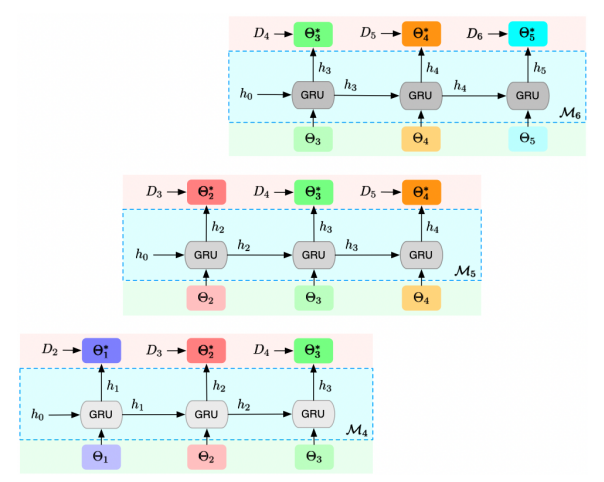
ASMG-GRUmulti
The intuition behind is to enforce that the hidden states generated at different steps are on the right track and able to produce model that serves well for the respective next period. More specifically, when training , instead of optimizing the last model towards only, we optimize all concurrently. To take into account that the later data is less seen before and hence more informative, we assign greater weight 𝜆 to loss of the more recent data.
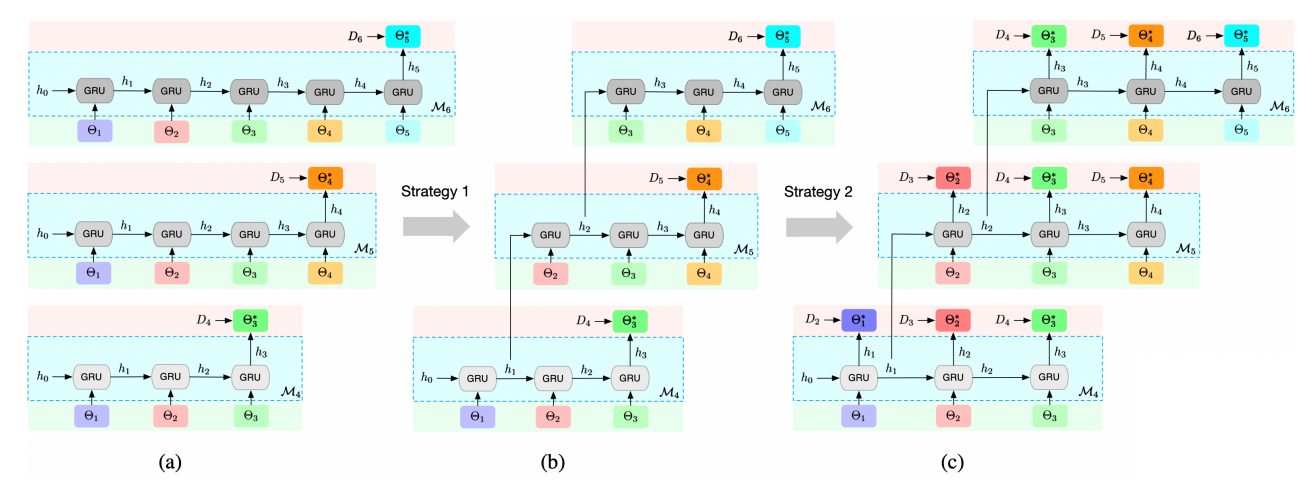
Training of GRU meta generator under the ASMG framework for three consecutive periods (i.e., training of M4, M5 and M6). Transition from (a) to (b) illustrates the first strategy, which trains the GRU meta generator on truncated sequence (here we use sequence length 𝑘 = 3) by continuing on a previously learned hidden state. Transition from (b) to (c) illustrates the second strategy, which performs concurrent training by optimizing data at multiple steps, with greater weights assigned to the more recent data. ASMG-GRUsingle and ASMG-GRUmulti are depicted by (b) and (c) respectively.
ASMG-GRUunif
This variant assigns uniform weights to the loss at different time steps. Illustration of this variant is the same as ASMG-GRUmulti, as the weights assigned are not explicitly shown in the diagram.
ASMG-GRUsingle
This variant performs single-step training at the last output model towards the newly collected data only.