BPR
BPR stands for Bayesian Personalized Ranking. In matrix factorization (MF), to compute the prediction we have to multiply the user factors to the item factors:
The usual approach for item recommenders is to predict a personalized score for an item that reflects the preference of the user for the item. Then the items are ranked by sorting them according to that score. Machine learning approaches are typically fit by using observed items as a positive sample and missing ones for the negative class. A perfect model would thus be useless, as it would classify as negative (non-interesting) all the items that were non-observed at training time. The only reason why such methods work is regularization.
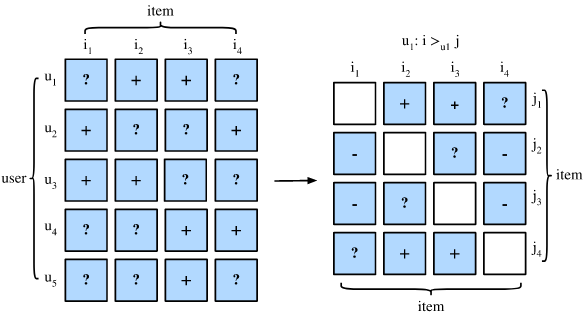
BPR use a different approach. The training dataset is composed by triplets representing that user is assumed to prefer over . For an implicit dataset this means that observed but not :
A machine learning model can be represented by a parameter vector which is found at fitting time. BPR wants to find the parameter vector that is most probable given the desired, but latent, preference structure :
The probability that a user really prefers item to item is defined as:
Where represent the logistic sigmoid and is an arbitrary real-valued function of (the output of your arbitrary model).
User has interacted with item but not item , so we assume that this user prefers item over . For items that the user have both interacted with, we cannot infer any preference. The same is true for two items that a user has not interacted yet (e.g. item and for user ).
To complete the Bayesian setting, we define a prior density for the parameters:
And we can now formulate the maximum posterior estimator:
Where are model specific regularization parameters.
Once obtained the log-likelihood, we need to maximize it in order to find our optimal . As the criterion is differentiable, gradient descent algorithms are an obvious choiche for maximization.
The basic version of gradient descent consists in evaluating the gradient using all the available samples and then perform a single update. The problem with this is, in our case, that our training dataset is very skewed. Suppose an item is very popular. Then we have many terms of the form in the loss because for many users the item is compared against all negative items . The other popular approach is stochastic gradient descent, where for each training sample an update is performed. This is a better approach, but the order in which the samples are traversed is crucial. To solve this issue BPR uses a stochastic gradient descent algorithm that chooses the triples randomly.
The gradient of BPR-OPT with respect to the model parameters is:
In order to practically apply this learning schema to an existing algorithm, we first split the real valued preference term: . And now we can apply any standard collaborative filtering model that predicts .
The problem of predicting can be seen as the task of estimating a matrix . With matrix factorization the target matrix is approximated by the matrix product of two low-rank matrices and :
The prediction formula can also be written as:
Besides the dot product ⟨⋅,⋅⟩, in general any kernel can be used.
We can now specify the derivatives:
Which basically means: user prefer over , let's do the following:
- Increase the relevance (according to ) of features belonging to but not to and vice-versa
- Increase the relevance of features assigned to
- Decrease the relevance of features assigned to
Links
- http://ethen8181.github.io/machine-learning/recsys/4_bpr.html
- https://nbviewer.jupyter.org/github/microsoft/recommenders/blob/master/examples/02_model_collaborative_filtering/cornac_bpr_deep_dive.ipynb
- https://youtu.be/Jfo9f345iMc
- https://www.coursera.org/lecture/matrix-factorization/personalized-ranking-with-daniel-kluver-s3XJo
- https://nbviewer.org/github/MaurizioFD/RecSys_Course_AT_PoliMi/blob/master/Practice 10 - MF.ipynb