NGCF
NGCF stands for Neural Graph Collaborative Filtering. This GNN-based approach follows basic operations inherited from the standard GCN to explore the high-order connectivity information. More specifically, NGCF stacks embedding layers and concatenates embeddings obtained in all layers to constitute the final embeddings.
research paper
Learning vector representations (aka. embeddings) of users and items lies at the core of modern recommender systems. Ranging from early matrix factorization to recently emerged deep learning based methods, existing efforts typically obtain a user’s (or an item’s) embedding by mapping from pre-existing features that describe the user (or the item), such as ID and attributes. We argue that an inherent drawback of such methods is that, the collaborative signal, which is latent in user-item interactions, is not encoded in the embedding process. As such, the resultant embeddings may not be sufficient to capture the collaborative filtering effect. In this work, we propose to integrate the user-item interactions — more specifically the bipartite graph structure — into the embedding process. We develop a new recommendation framework Neural Graph Collaborative Filtering (NGCF), which exploits the user-item graph structure by propagating embeddings on it. This leads to the expressive modeling of high-order connectivity in user-item graph, effectively injecting the collaborative signal into the embedding process in an explicit manner. We conduct extensive experiments on three public benchmarks, demonstrating significant improvements over several state-of-the-art models like HOPRec and Collaborative Memory Network. Further analysis verifies the importance of embedding propagation for learning better user and item representations, justifying the rationality and effectiveness of NGCF. - Wang et. al.
Architecture
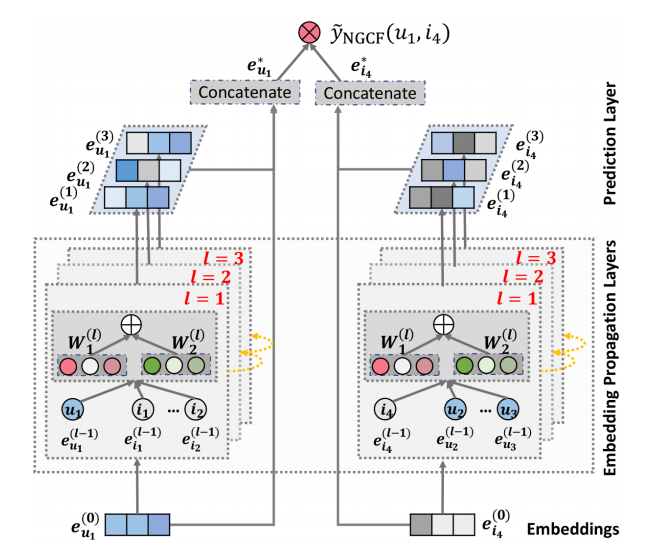
Implementation
PyTorch
'''
Created on October 1, 2020
@author: Tinglin Huang (huangtinglin@outlook.com)
'''
import torch
import torch.nn as nn
import torch.nn.functional as F
class NGCF(nn.Module):
def __init__(self, data_config, args_config, adj_mat):
super(NGCF, self).__init__()
self.n_users = data_config['n_users']
self.n_items = data_config['n_items']
self.adj_mat = adj_mat
self.decay = args_config.l2
self.emb_size = args_config.dim
self.context_hops = args_config.context_hops
self.mess_dropout = args_config.mess_dropout
self.mess_dropout_rate = args_config.mess_dropout_rate
self.edge_dropout = args_config.edge_dropout
self.edge_dropout_rate = args_config.edge_dropout_rate
self.pool = args_config.pool
self.n_negs = args_config.n_negs
self.ns = args_config.ns
self.device = torch.device("cuda:0") if args_config.cuda else torch.device("cpu")
self.K = args_config.K
"""
*********************************************************
Init the weight of user-item.
"""
self.embedding_dict, self.weight_dict = self.init_weight()
"""
*********************************************************
Get sparse adj.
"""
self.sparse_norm_adj = self._convert_sp_mat_to_sp_tensor(self.adj_mat).to(self.device)
def init_weight(self):
# xavier init
initializer = nn.init.xavier_uniform_
embedding_dict = nn.ParameterDict({
'user_emb': nn.Parameter(initializer(torch.empty(self.n_users,
self.emb_size))),
'item_emb': nn.Parameter(initializer(torch.empty(self.n_items,
self.emb_size)))
})
weight_dict = nn.ParameterDict()
layers = [self.emb_size] * (self.context_hops+1)
for k in range(self.context_hops):
weight_dict.update({'W_gc_%d'%k: nn.Parameter(initializer(torch.empty(layers[k],
layers[k+1])))})
weight_dict.update({'b_gc_%d'%k: nn.Parameter(initializer(torch.empty(1, layers[k+1])))})
weight_dict.update({'W_bi_%d'%k: nn.Parameter(initializer(torch.empty(layers[k],
layers[k+1])))})
weight_dict.update({'b_bi_%d'%k: nn.Parameter(initializer(torch.empty(1, layers[k+1])))})
return embedding_dict, weight_dict
def _convert_sp_mat_to_sp_tensor(self, X):
coo = X.tocoo()
i = torch.LongTensor([coo.row, coo.col])
v = torch.from_numpy(coo.data).float()
return torch.sparse.FloatTensor(i, v, coo.shape)
def sparse_dropout(self, x, rate, noise_shape):
random_tensor = 1 - rate
random_tensor += torch.rand(noise_shape).to(x.device)
dropout_mask = torch.floor(random_tensor).type(torch.bool)
i = x._indices()
v = x._values()
i = i[:, dropout_mask]
v = v[dropout_mask]
out = torch.sparse.FloatTensor(i, v, x.shape).to(x.device)
return out * (1. / (1 - rate))
def create_bpr_loss(self, user_gcn_emb, pos_gcn_embs, neg_gcn_embs):
batch_size = user_gcn_emb.shape[0]
u_e = self.pooling(user_gcn_emb)
pos_e = self.pooling(pos_gcn_embs)
neg_e = self.pooling(neg_gcn_embs.view(-1, neg_gcn_embs.shape[2], neg_gcn_embs.shape[3])).view(batch_size, self.K, -1)
pos_scores = torch.sum(torch.mul(u_e, pos_e), axis=1)
neg_scores = torch.sum(torch.mul(u_e.unsqueeze(dim=1), neg_e), axis=-1) # [batch_size, K]
# mf_loss = -1 * torch.mean(nn.LogSigmoid()(pos_scores - neg_scores))
# mf_loss = torch.mean(nn.functional.softplus((neg_scores - pos_scores.unsqueeze(dim=1)).view(-1)))
mf_loss = torch.mean(torch.log(1+torch.exp(neg_scores - pos_scores.unsqueeze(dim=1)).sum(dim=1)))
# cul regularizer
regularize = (torch.norm(user_gcn_emb[:, 0, :]) ** 2
+ torch.norm(pos_gcn_embs[:, 0, :]) ** 2
+ torch.norm(neg_gcn_embs[:, :, 0, :]) ** 2) / 2 # take hop=0
emb_loss = self.decay * regularize / batch_size
return mf_loss + emb_loss, mf_loss, emb_loss
def rating(self, u_g_embeddings, pos_i_g_embeddings):
return torch.matmul(u_g_embeddings, pos_i_g_embeddings.t())
def gcn(self, edge_dropout=True, mess_dropout=True):
A_hat = self.sparse_dropout(self.sparse_norm_adj,
self.edge_dropout_rate,
self.sparse_norm_adj._nnz()) if edge_dropout else self.sparse_norm_adj
ego_embeddings = torch.cat([self.embedding_dict['user_emb'],
self.embedding_dict['item_emb']], 0)
all_embeddings = [ego_embeddings]
for k in range(self.context_hops):
side_embeddings = torch.sparse.mm(A_hat, ego_embeddings)
# transformed sum messages of neighbors.
sum_embeddings = torch.matmul(side_embeddings, self.weight_dict['W_gc_%d' % k]) \
+ self.weight_dict['b_gc_%d' % k]
# bi messages of neighbors.
# element-wise product
bi_embeddings = torch.mul(ego_embeddings, side_embeddings)
# transformed bi messages of neighbors.
bi_embeddings = torch.matmul(bi_embeddings, self.weight_dict['W_bi_%d' % k]) \
+ self.weight_dict['b_bi_%d' % k]
# non-linear activation.
ego_embeddings = nn.LeakyReLU(negative_slope=0.2)(sum_embeddings + bi_embeddings)
# message dropout.
if mess_dropout:
ego_embeddings = nn.Dropout(self.mess_dropout_rate)(ego_embeddings)
# normalize the distribution of embeddings.
norm_embeddings = F.normalize(ego_embeddings, p=2, dim=1)
all_embeddings += [norm_embeddings]
all_embeddings = torch.stack(all_embeddings, dim=1) # [n_entity, n_hops+1, emb_size]
return all_embeddings[:self.n_users, :], all_embeddings[self.n_users:, :]
def generate(self, split=True):
user_gcn_emb, item_gcn_emb = self.gcn(edge_dropout=False, mess_dropout=False)
user_gcn_emb, item_gcn_emb = self.pooling(user_gcn_emb), self.pooling(item_gcn_emb)
if split:
return user_gcn_emb, item_gcn_emb
else:
return torch.cat([user_gcn_emb, item_gcn_emb], dim=0)
def negative_sampling(self, user_gcn_emb, item_gcn_emb, user, neg_candidates, pos_item):
batch_size = user.shape[0]
s_e, p_e = user_gcn_emb[user], item_gcn_emb[pos_item] # [batch_size, n_hops+1, channel]
if self.pool != 'concat':
s_e = self.pooling(s_e).unsqueeze(dim=1)
"""positive mixing"""
seed = torch.rand(batch_size, 1, p_e.shape[1], 1).to(p_e.device) # (0, 1)
n_e = item_gcn_emb[neg_candidates] # [batch_size, n_negs, n_hops, channel]
n_e_ = seed * p_e.unsqueeze(dim=1) + (1 - seed) * n_e # mixing
"""hop mixing"""
scores = (s_e.unsqueeze(dim=1) * n_e_).sum(dim=-1) # [batch_size, n_negs, n_hops+1]
indices = torch.max(scores, dim=1)[1].detach()
neg_items_emb_ = n_e_.permute([0, 2, 1, 3]) # [batch_size, n_hops+1, n_negs, channel]
# [batch_size, n_hops+1, channel]
return neg_items_emb_[[[i] for i in range(batch_size)],
range(neg_items_emb_.shape[1]), indices, :]
def pooling(self, embeddings):
# [-1, n_hops, channel]
if self.pool == 'mean':
return embeddings.mean(dim=1)
elif self.pool == 'sum':
return embeddings.sum(dim=1)
elif self.pool == 'concat':
return embeddings.view(embeddings.shape[0], -1)
else: # final
return embeddings[:, -1, :]
def forward(self, batch):
user = batch['users']
pos_item = batch['pos_items']
neg_item = batch['neg_items']
user_gcn_emb, item_gcn_emb = self.gcn(edge_dropout=self.edge_dropout,
mess_dropout=self.mess_dropout)
pos_gcn_embs = item_gcn_emb[pos_item]
if self.ns == 'rns': # n_negs = 1
neg_gcn_embs = item_gcn_emb[neg_item[:, :self.K]]
else:
neg_gcn_embs = []
for k in range(self.K):
neg_gcn_embs.append(self.negative_sampling(user_gcn_emb, item_gcn_emb,
user, neg_item[:, k * self.n_negs: (k + 1) * self.n_negs],
pos_item))
neg_gcn_embs = torch.stack(neg_gcn_embs, dim=1)
return self.create_bpr_loss(user_gcn_emb[user], pos_gcn_embs, neg_gcn_embs)
Links
- https://github.com/xiangwang1223/neural_graph_collaborative_filtering
- https://arxiv.org/pdf/1905.08108.pdf
- https://github.com/huangtinglin/NGCF-PyTorch
code - https://arxiv.org/abs/2108.06208v1
paper - https://github.com/jeongwhanchoi/LT-OCF
code - https://github.com/newlei/LR-GCCF
code - https://arxiv.org/abs/2001.10167
paper - https://arxiv.org/abs/2006.15516
paper - https://github.com/Wenhui-Yu/LCFN
code - Graph Neural Networks in Recommender Systems: A Survey
paper - https://deeprs-tutorial.github.io/WWW_GNNs.pdf
ppt - https://github.com/yazdotai/graph-networks
site - https://github.com/Jhy1993/Awesome-GNN-Recommendation
site - LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation
paper - LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation
code - LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation
code