DCN
DCN stands for Deep and Cross Network. Manual explicit feature crossing process is very laborious and inefficient. On the other hand, automatic implicit feature crossing methods like MLPs cannot efficiently approximate even 2nd or 3rd-order feature crosses. Deep-cross networks provides a solution to this problem. DCN was designed to learn explicit and bounded-degree cross features more effectively. It starts with an input layer (typically an embedding layer), followed by a cross network containing multiple cross layers that models explicit feature interactions, and then combines with a deep network that models implicit feature interactions.
research paper
Feature engineering has been the key to the success of many prediction models. However, the process is non-trivial and often requires manual feature engineering or exhaustive searching. DNNs are able to automatically learn feature interactions; however, they generate all the interactions implicitly, and are not necessarily efficient in learning all types of cross features. In this paper, we propose the Deep & Cross Network (DCN) which keeps the benefits of a DNN model, and beyond that, it introduces a novel cross network that is more efficient in learning certain bounded-degree feature interactions. In particular, DCN explicitly applies feature crossing at each layer, requires no manual feature engineering, and adds negligible extra complexity to the DNN model. Our experimental results have demonstrated its superiority over the state-of-art algorithms on the CTR prediction dataset and dense classification dataset, in terms of both model accuracy and memory usage.
Deep and cross network, short for DCN, came out of Google Research, and is designed to learn explicit and bounded-degree cross features effectively:
- large and sparse feature space is extremely hard to train.
- Oftentimes, we needed to do a lot of manual feature engineering, including designing cross features, which is very challenging and less effective.
- Whilst possible to use additional neural networks under such circumstances, it's not the most efficient approach.
Deep and cross network (DCN) is specifically designed to tackle all above challenges.
Architecture
Feature Cross
Let's say we're building a recommender system to sell a blender to customers. Then our customers' past purchase history, such as purchased bananas and purchased cooking books, or geographic features are single features. If one has purchased both bananas and cooking books, then this customer will be more likely to click on the recommended blender. The combination of purchased bananas and the purchased cooking books is referred to as feature cross, which provides additional interaction information beyond the individual features. You can keep adding more cross features to even higher degrees:
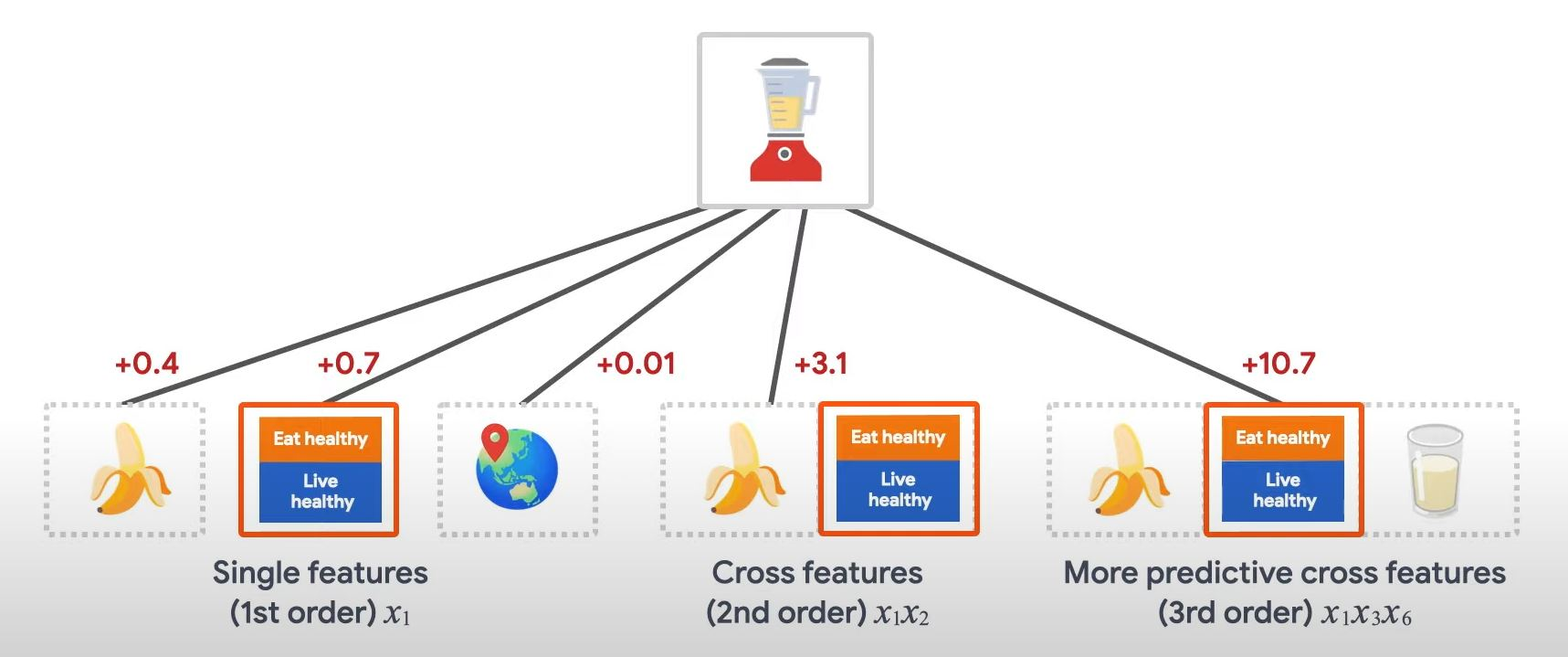
Cross Network
In real world recommendation systems, we often have large and sparse feature space. So identifying effective feature processes in this setting would often require manual feature engineering or exhaustive search, which is highly inefficient. To tackle this issue, Google Research team has proposed Deep and Cross Network, DCN.
It starts with an input layer, typically an embedding layer, followed by a cross network containing multiple cross layers that models explicitly feature interactions, and then combines with a deep network that models implicit feature interactions. The deep network is just a traditional multilayer construction. But the core of DCN is really the cross network. It explicitly applies feature crossing at each layer. And the highest polynomial degree increases with layer depth. The figure here shows the deep and cross layer in the mathematical form.
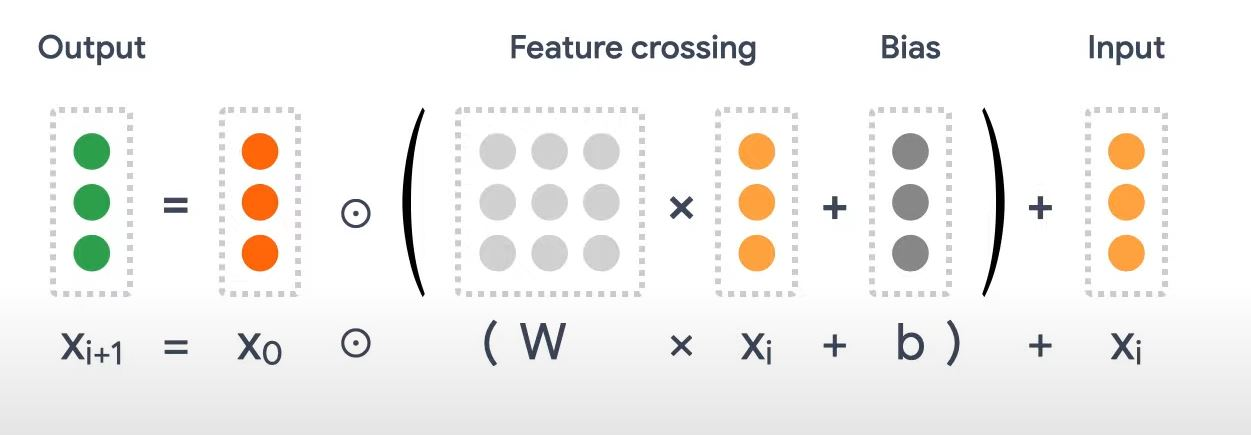
Deep & Cross Network Architecture
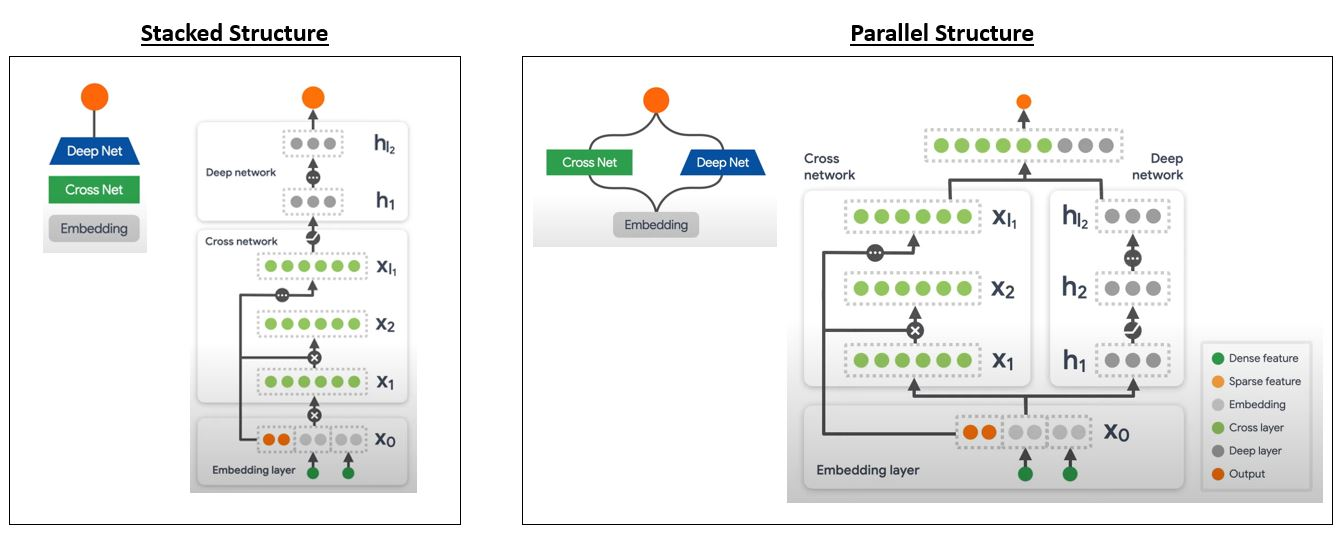
There are a couple of ways to combine the cross network and the deep network:
- Stack the deep network on top of the cross network.
- Place deep & cross networks in parallel.
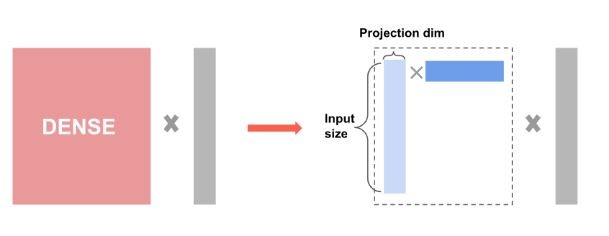
Low-rank DCN
To reduce the training and serving cost, we leverage low-rank techniques to approximate the DCN weight matrices. The rank is passed in through argument projection_dim; a smaller projection_dim results in a lower cost. Note that projection_dim needs to be smaller than (input size)/2 to reduce the cost. In practice, we've observed using low-rank DCN with rank (input size)/4 consistently preserved the accuracy of a full-rank DCN.
List of experiments
- TFRS | Notebook
- Blog
- Keras Blog | Notebook
- Paper | Code
- Paper
- Code
- Code | Keras
- Blog | Nvidia
- Official Video
- RapidsAI Notebook
Links
- https://www.tensorflow.org/recommenders/examples/dcn
- https://github.com/shenweichen/DeepCTR-Torch
- https://recbole.io/docs/recbole/recbole.model.context_aware_recommender.dcn.html
- https://deepctr-doc.readthedocs.io/en/latest/deepctr.models.dcn.html
- https://deepctr-torch.readthedocs.io/en/latest/deepctr_torch.models.dcn.html
- https://medium.com/@SeoJaeDuk/deep-cross-network-for-ad-click-predictions-1714321f739a