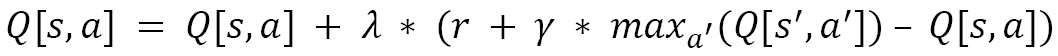Q-learning
Q-learning can be applied to model-free RL problems. It supports off-policy learning and therefore provides a practical solution to problems where available experiences were/are collected using some other policy or by some other agent (even humans).
The Q-learning algorithm involves the Q value update, which can be summarized by the following equation: