Deep Reinforcement Learning in Large Discrete Action Spaces¶
Advanced AI systems will likely need to reason with a large number of possible actions at every step. Recommender systems used in large systems such as YouTube and Amazon must reason about hundreds of millions of items every second, and control systems for large industrial processes may have millions of possible actions that can be applied at every time step.
We deal with these large action spaces by leveraging prior information about the actions to embed them in a continuous space upon which the actor can generalize. The policy produces a continuous action within this space, and then uses an approximate nearest neighbor search to find the set of closest discrete actions in logarithmic time.
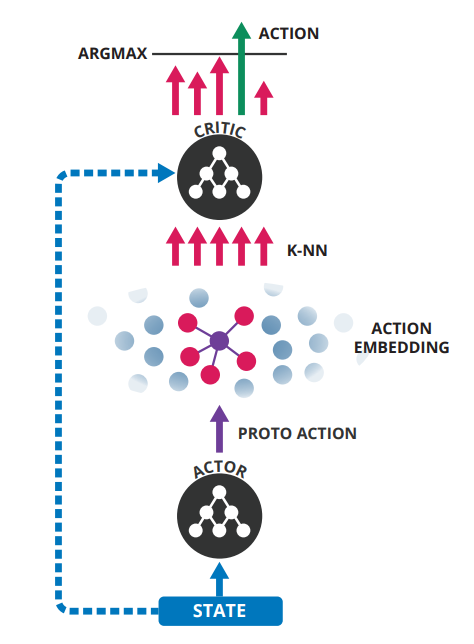
This architecture avoids the heavy cost of evaluating all actions while retaining generalization over actions. This policy builds upon the actor-critic (Sutton & Barto, 1998) framework. We define both an efficient action-generating actor, and utilize the critic to refine our actor’s choices for the full policy. We use multi-layer neural networks as function approximators for both our actor and critic functions. We train this policy using Deep Deterministic Policy Gradient (Lillicrap et al., 2015).
Wolpertinger¶
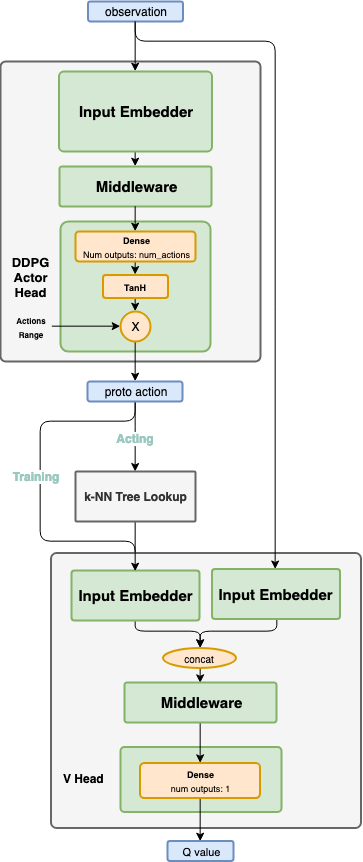
Pass the current states through the actor network, and get a proto action μ. While in training phase, use a continuous exploration policy, such as the a gaussian noise, to add exploration noise to the proto action. Then, pass the proto action to a k-NN tree to find actual valid action candidates, which are in the surrounding neighborhood of the proto action. Those actions are then passed to the critic to evaluate their goodness, and eventually the discrete index of the action with the highest Q value is chosen. When testing, the same flow is used, but no exploration noise is added.
Training procedure¶
Training the network is exactly the same as in DDPG. Unlike when choosing the action, the proto action is not passed through the k-NN tree. It is being passed directly to the critic.
Start by sampling a batch of transitions from the experience replay.
To train the critic network, use the following targets:
\[y_t=r(s_t,a_t )+\gamma \cdot Q(s_{t+1},\mu(s_{t+1} ))\]First run the actor target network, using the next states as the inputs, and get μ(st+1)μ(st+1). Next, run the critic target network using the next states and μ(st+1)μ(st+1), and use the output to calculate ytyt according to the equation above. To train the network, use the current states and actions as the inputs, and ytyt as the targets.
To train the actor network, use the following equation:
\[\nabla_{\theta^\mu } J \approx E_{s_t \tilde{} \rho^\beta } [\nabla_a Q(s,a)|_{s=s_t,a=\mu (s_t ) } \cdot \nabla_{\theta^\mu} \mu(s)|_{s=s_t} ]\]Use the actor’s online network to get the action mean values using the current states as the inputs. Then, use the critic online network in order to get the gradients of the critic output with respect to the action mean values \(\nabla _a Q(s,a)|_{s=s_t,a=\mu(s_t ) }\). Using the chain rule, calculate the gradients of the actor’s output, with respect to the actor weights, given \(\nabla_a Q(s,a)\). Finally, apply those gradients to the actor network.
After every training step, do a soft update of the critic and actor target networks’ weights from the online networks.
Setup¶
!pip install setproctitle
import os
# to know the python path in colab
os.path.abspath(os.__file__)
'/usr/lib/python3.7/os.py'
!git clone https://github.com/ChangyWen/wolpertinger_ddpg.git
%cd wolpertinger_ddpg
!cp -r pyflann /usr/lib/python3.7
Cloning into 'wolpertinger_ddpg'...
remote: Enumerating objects: 252, done.
remote: Counting objects: 100% (71/71), done.
remote: Compressing objects: 100% (46/46), done.
remote: Total 252 (delta 21), reused 67 (delta 19), pack-reused 181
Receiving objects: 100% (252/252), 8.44 MiB | 18.48 MiB/s, done.
Resolving deltas: 100% (116/116), done.
/content/wolpertinger_ddpg
Pendulum with 200K actions¶
In Pendulum-v0 (continuous control), discretize the continuous action space to a discrete action spaces with 200000 actions.
!cd src && python main.py --env 'Pendulum-v0' --max-actions 200000
CartPole¶
In CartPole-v1 (discrete control), –max-actions is not needed.
!cd src && python main.py --env 'CartPole-v1'
Analysis¶
!apt-get -qq install tree
Selecting previously unselected package tree.
(Reading database ... 155047 files and directories currently installed.)
Preparing to unpack .../tree_1.7.0-5_amd64.deb ...
Unpacking tree (1.7.0-5) ...
Setting up tree (1.7.0-5) ...
Processing triggers for man-db (2.8.3-2ubuntu0.1) ...
!tree --du -h -C .
.
├── [1.7M] output
│ ├── [572K] CartPole-v1-run10
│ │ ├── [270K] actor.pt
│ │ ├── [271K] critic.pt
│ │ └── [ 26K] RS_train_log
│ ├── [560K] CartPole-v1-run12
│ │ ├── [270K] actor.pt
│ │ ├── [271K] critic.pt
│ │ └── [ 16K] RS_train_log
│ ├── [5.4K] Pendulum-v0-run11
│ │ └── [1.4K] RS_train_log
│ └── [630K] Pendulum-v0-run8
│ ├── [267K] actor.pt
│ ├── [268K] critic.pt
│ └── [ 91K] RS_train_log
├── [ 31M] pyflann
│ ├── [ 32K] bindings
│ │ ├── [ 13K] flann_ctypes.py
│ │ ├── [ 13K] flann_ctypes.py.bak
│ │ ├── [1.5K] __init__.py
│ │ └── [1.5K] __init__.py.bak
│ ├── [1.7K] exceptions.py
│ ├── [ 14K] index.py
│ ├── [ 14K] index.py.bak
│ ├── [1.5K] __init__.py
│ ├── [1.5K] __init__.py.bak
│ ├── [ 32K] io
│ │ ├── [2.5K] binary_dataset.py
│ │ ├── [2.5K] binary_dataset.py.bak
│ │ ├── [2.3K] dataset.py
│ │ ├── [2.3K] dataset.py.bak
│ │ ├── [2.1K] dat_dataset.py
│ │ ├── [2.2K] dat_dataset.py.bak
│ │ ├── [3.3K] hdf5_dataset.py
│ │ ├── [3.3K] hdf5_dataset.py.bak
│ │ ├── [1.4K] __init__.py
│ │ ├── [1.4K] __init__.py.bak
│ │ ├── [2.1K] npy_dataset.py
│ │ └── [2.1K] npy_dataset.py.bak
│ ├── [ 31M] lib
│ │ ├── [2.6M] darwin
│ │ │ └── [2.6M] libflann.dylib
│ │ ├── [ 26M] linux
│ │ │ └── [ 26M] libflann.so
│ │ └── [2.6M] win32
│ │ ├── [1.1M] x64
│ │ │ └── [1.1M] flann.dll
│ │ └── [1.6M] x86
│ │ └── [1.6M] flann.dll
│ └── [ 18K] util
│ ├── [1.4K] __init__.py
│ ├── [6.2K] weave_tools.py
│ └── [6.2K] weave_tools.py.bak
├── [2.6K] README.md
└── [ 95K] src
├── [3.1K] action_space.py
├── [3.2K] arg_parser.py
├── [6.3K] ddpg.py
├── [ 11K] LICENSE
├── [3.6K] main.py
├── [ 11K] memory.py
├── [2.1K] model.py
├── [1.0K] normalized_env.py
├── [ 36K] __pycache__
│ ├── [3.0K] action_space.cpython-37.pyc
│ ├── [2.4K] arg_parser.cpython-37.pyc
│ ├── [5.3K] ddpg.cpython-37.pyc
│ ├── [7.8K] memory.cpython-37.pyc
│ ├── [2.4K] model.cpython-37.pyc
│ ├── [ 798] normalized_env.cpython-37.pyc
│ ├── [2.1K] random_process.cpython-37.pyc
│ ├── [1.6K] train_test.cpython-37.pyc
│ ├── [2.5K] util.cpython-37.pyc
│ └── [4.0K] wolp_agent.cpython-37.pyc
├── [1.7K] random_process.py
├── [3.0K] train_test.py
├── [2.7K] util.py
└── [5.8K] wolp_agent.py
33M used in 17 directories, 61 files
As we can see, we get 2 PyTorch (.pt) models - actor.pt and critic.pt
Let’s analyze the implementation details of some essential components
!pip install -U Ipython
from IPython.display import Code
import inspect
import sys
sys.path.insert(0,'./src')
from src import *
Wolpertinger Agent¶
from src import wolp_agent
Code(inspect.getsource(wolp_agent), language='python')
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from ddpg import DDPG
import action_space
from util import *
import torch.nn as nn
import torch
criterion = nn.MSELoss()
class WolpertingerAgent(DDPG):
def __init__(self, continuous, max_actions, action_low, action_high, nb_states, nb_actions, args, k_ratio=0.1):
super().__init__(args, nb_states, nb_actions)
self.experiment = args.id
# according to the papers, it can be scaled to hundreds of millions
if continuous:
self.action_space = action_space.Space(action_low, action_high, args.max_actions)
self.k_nearest_neighbors = max(1, int(args.max_actions * k_ratio))
else:
self.action_space = action_space.Discrete_space(max_actions)
self.k_nearest_neighbors = max(1, int(max_actions * k_ratio))
def get_name(self):
return 'Wolp3_{}k{}_{}'.format(self.action_space.get_number_of_actions(),
self.k_nearest_neighbors, self.experiment)
def get_action_space(self):
return self.action_space
def wolp_action(self, s_t, proto_action):
# get the proto_action's k nearest neighbors
raw_actions, actions = self.action_space.search_point(proto_action, self.k_nearest_neighbors)
if not isinstance(s_t, np.ndarray):
s_t = to_numpy(s_t, gpu_used=self.gpu_used)
# make all the state, action pairs for the critic
s_t = np.tile(s_t, [raw_actions.shape[1], 1])
s_t = s_t.reshape(len(raw_actions), raw_actions.shape[1], s_t.shape[1]) if self.k_nearest_neighbors > 1 \
else s_t.reshape(raw_actions.shape[0], s_t.shape[1])
raw_actions = to_tensor(raw_actions, gpu_used=self.gpu_used, gpu_0=self.gpu_ids[0])
s_t = to_tensor(s_t, gpu_used=self.gpu_used, gpu_0=self.gpu_ids[0])
# evaluate each pair through the critic
actions_evaluation = self.critic([s_t, raw_actions])
# find the index of the pair with the maximum value
max_index = np.argmax(to_numpy(actions_evaluation, gpu_used=self.gpu_used), axis=1)
max_index = max_index.reshape(len(max_index),)
raw_actions = to_numpy(raw_actions, gpu_used=self.gpu_used)
# return the best action, i.e., wolpertinger action from the full wolpertinger policy
if self.k_nearest_neighbors > 1:
return raw_actions[[i for i in range(len(raw_actions))], max_index, [0]].reshape(len(raw_actions),1), \
actions[[i for i in range(len(actions))], max_index, [0]].reshape(len(actions),1)
else:
return raw_actions[max_index], actions[max_index]
def select_action(self, s_t, decay_epsilon=True):
# taking a continuous action from the actor
proto_action = super().select_action(s_t, decay_epsilon)
raw_wolp_action, wolp_action = self.wolp_action(s_t, proto_action)
assert isinstance(raw_wolp_action, np.ndarray)
self.a_t = raw_wolp_action
# return the best neighbor of the proto action, this is an action for env step
return wolp_action[0] # [i]
def random_action(self):
proto_action = super().random_action()
raw_action, action = self.action_space.search_point(proto_action, 1)
raw_action = raw_action[0]
action = action[0]
assert isinstance(raw_action, np.ndarray)
self.a_t = raw_action
return action[0] # [i]
def select_target_action(self, s_t):
proto_action = self.actor_target(s_t)
proto_action = to_numpy(torch.clamp(proto_action, -1.0, 1.0), gpu_used=self.gpu_used)
raw_wolp_action, wolp_action = self.wolp_action(s_t, proto_action)
return raw_wolp_action
def update_policy(self):
# Sample batch
state_batch, action_batch, reward_batch, \
next_state_batch, terminal_batch = self.memory.sample_and_split(self.batch_size)
# Prepare for the target q batch
# the operation below of critic_target does not require backward_P
next_state_batch = to_tensor(next_state_batch, volatile=True, gpu_used=self.gpu_used, gpu_0=self.gpu_ids[0])
next_wolp_action_batch = self.select_target_action(next_state_batch)
# print(next_state_batch.shape)
# print(next_wolp_action_batch.shape)
next_q_values = self.critic_target([
next_state_batch,
to_tensor(next_wolp_action_batch, volatile=True, gpu_used=self.gpu_used, gpu_0=self.gpu_ids[0]),
])
# but it requires bp in computing gradient of critic loss
next_q_values.volatile = False
# next_q_values = 0 if is terminal states
target_q_batch = to_tensor(reward_batch, gpu_used=self.gpu_used, gpu_0=self.gpu_ids[0]) + \
self.gamma * \
to_tensor(terminal_batch.astype(np.float64), gpu_used=self.gpu_used, gpu_0=self.gpu_ids[0]) * \
next_q_values
# Critic update
self.critic.zero_grad() # Clears the gradients of all optimized torch.Tensor s.
state_batch = to_tensor(state_batch, gpu_used=self.gpu_used, gpu_0=self.gpu_ids[0])
action_batch = to_tensor(action_batch, gpu_used=self.gpu_used, gpu_0=self.gpu_ids[0])
q_batch = self.critic([state_batch, action_batch])
value_loss = criterion(q_batch, target_q_batch)
value_loss.backward() # computes gradients
self.critic_optim.step() # updates the parameters
# Actor update
self.actor.zero_grad()
# self.actor(to_tensor(state_batch)): proto_action_batch
policy_loss = -self.critic([state_batch, self.actor(state_batch)])
policy_loss = policy_loss.mean()
policy_loss.backward()
self.actor_optim.step()
# Target update
soft_update(self.actor_target, self.actor, self.tau_update)
soft_update(self.critic_target, self.critic, self.tau_update)
Memory¶
from src import memory
Code(inspect.getsource(memory), language='python')
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from __future__ import absolute_import
from collections import deque, namedtuple
import warnings
import random
import numpy as np
# [reference] https://github.com/matthiasplappert/keras-rl/blob/master/rl/memory.py
# This is to be understood as a transition: Given `state0`, performing `action`
# yields `reward` and results in `state1`, which might be `terminal`.
Experience = namedtuple('Experience', 'state0, action, reward, state1, terminal1')
def sample_batch_indexes(low, high, size):
if high - low >= size:
# We have enough data. Draw without replacement, that is each index is unique in the
# batch. We cannot use `np.random.choice` here because it is horribly inefficient as
# the memory grows. See https://github.com/numpy/numpy/issues/2764 for a discussion.
# `random.sample` does the same thing (drawing without replacement) and is way faster.
try:
r = xrange(low, high)
except NameError:
r = range(low, high)
batch_idxs = random.sample(r, size)
else:
# Not enough data. Help ourselves with sampling from the range, but the same index
# can occur multiple times. This is not good and should be avoided by picking a
# large enough warm-up phase.
warnings.warn('Not enough entries to sample without replacement. Consider increasing your warm-up phase to avoid oversampling!')
# batch_idxs = np.random.random_integers(low, high - 1, size=size)
batch_idxs = np.random.randint(low, high, size=size)
assert len(batch_idxs) == size
return batch_idxs
class RingBuffer(object):
def __init__(self, maxlen):
self.maxlen = maxlen
self.start = 0
self.length = 0
self.data = [None for _ in range(maxlen)]
def __len__(self):
return self.length
def __getitem__(self, idx):
if idx < 0 or idx >= self.length:
raise KeyError()
return self.data[(self.start + idx) % self.maxlen]
def append(self, v):
assert isinstance(v, np.ndarray) or isinstance(v, float) or isinstance(v, bool), "v_type:{}".format(type(v))
if self.length < self.maxlen:
# We have space, simply increase the length.
self.length += 1
elif self.length == self.maxlen:
# No space, "remove" the first item.
self.start = (self.start + 1) % self.maxlen
else:
# This should never happen.
raise RuntimeError()
self.data[(self.start + self.length - 1) % self.maxlen] = v
def zeroed_observation(observation):
if hasattr(observation, 'shape'):
return np.zeros(observation.shape)
elif hasattr(observation, '__iter__'):
out = []
for x in observation:
out.append(zeroed_observation(x))
return out
else:
return 0.
class Memory(object):
def __init__(self, window_length, ignore_episode_boundaries=False):
self.window_length = window_length
self.ignore_episode_boundaries = ignore_episode_boundaries
self.recent_observations = deque(maxlen=window_length)
self.recent_terminals = deque(maxlen=window_length)
def sample(self, batch_size, batch_idxs=None):
raise NotImplementedError()
def append(self, observation, action, reward, terminal, training=True):
self.recent_observations.append(observation)
self.recent_terminals.append(terminal)
def get_recent_state(self, current_observation):
# This code is slightly complicated by the fact that subsequent observations might be
# from different episodes. We ensure that an experience never spans multiple episodes.
# This is probably not that important in practice but it seems cleaner.
state = [current_observation]
idx = len(self.recent_observations) - 1
for offset in range(0, self.window_length - 1):
current_idx = idx - offset
current_terminal = self.recent_terminals[current_idx - 1] if current_idx - 1 >= 0 else False
if current_idx < 0 or (not self.ignore_episode_boundaries and current_terminal):
# The previously handled observation was terminal, don't add the current one.
# Otherwise we would leak into a different episode.
break
state.insert(0, self.recent_observations[current_idx])
while len(state) < self.window_length:
state.insert(0, zeroed_observation(state[0]))
return state
def get_config(self):
config = {
'window_length': self.window_length,
'ignore_episode_boundaries': self.ignore_episode_boundaries,
}
return config
class SequentialMemory(Memory):
def __init__(self, limit, **kwargs):
super(SequentialMemory, self).__init__(**kwargs)
self.limit = limit
# Do not use deque to implement the memory. This data structure may seem convenient but
# it is way too slow on random access. Instead, we use our own ring buffer implementation.
self.actions = RingBuffer(limit)
self.rewards = RingBuffer(limit)
self.terminals = RingBuffer(limit)
self.observations = RingBuffer(limit)
def sample(self, batch_size, batch_idxs=None):
if batch_idxs is None:
# Draw random indexes such that we have at least a single entry before each
# index.
assert self.nb_entries >= 2
batch_idxs = sample_batch_indexes(0, self.nb_entries - 1, size=batch_size)
batch_idxs = np.array(batch_idxs) + 1
assert np.min(batch_idxs) >= 1
assert np.max(batch_idxs) < self.nb_entries
assert len(batch_idxs) == batch_size
# Create experiences
experiences = []
for idx in batch_idxs:
terminal0 = self.terminals[idx - 2] if idx >= 2 else False
while terminal0:
# Skip this transition because the environment was reset here. Select a new, random
# transition and use this instead. This may cause the batch to contain the same
# transition twice.
idx = sample_batch_indexes(1, self.nb_entries, size=1)[0]
terminal0 = self.terminals[idx - 2] if idx >= 2 else False
assert 1 <= idx < self.nb_entries
# This code is slightly complicated by the fact that subsequent observations might be
# from different episodes. We ensure that an experience never spans multiple episodes.
# This is probably not that important in practice but it seems cleaner.
state0 = [self.observations[idx - 1]]
for offset in range(0, self.window_length - 1):
current_idx = idx - 2 - offset
current_terminal = self.terminals[current_idx - 1] if current_idx - 1 > 0 else False
if current_idx < 0 or (not self.ignore_episode_boundaries and current_terminal):
# The previously handled observation was terminal, don't add the current one.
# Otherwise we would leak into a different episode.
break
state0.insert(0, self.observations[current_idx])
while len(state0) < self.window_length:
state0.insert(0, zeroed_observation(state0[0]))
action = self.actions[idx - 1]
reward = self.rewards[idx - 1]
terminal1 = self.terminals[idx - 1]
# Okay, now we need to create the follow-up state. This is state0 shifted on timestep
# to the right. Again, we need to be careful to not include an observation from the next
# episode if the last state is terminal.
state1 = [np.copy(x) for x in state0[1:]]
state1.append(self.observations[idx])
assert len(state0) == self.window_length
assert len(state1) == len(state0)
experiences.append(Experience(state0=state0, action=action, reward=reward,
state1=state1, terminal1=terminal1))
assert len(experiences) == batch_size
return experiences
def sample_and_split(self, batch_size, batch_idxs=None):
experiences = self.sample(batch_size, batch_idxs)
state0_batch = []
reward_batch = []
action_batch = []
terminal1_batch = []
state1_batch = []
for e in experiences:
state0_batch.append(e.state0)
state1_batch.append(e.state1)
reward_batch.append(e.reward)
action_batch.append(e.action)
terminal1_batch.append(0. if e.terminal1 else 1.)
# Prepare and validate parameters.
state0_batch = np.array(state0_batch).reshape(batch_size,-1).astype(np.float64)
state1_batch = np.array(state1_batch).reshape(batch_size,-1).astype(np.float64)
terminal1_batch = np.array(terminal1_batch).reshape(batch_size,-1).astype(np.float64)
reward_batch = np.array(reward_batch).reshape(batch_size,-1).astype(np.float64)
action_batch = np.array(action_batch).reshape(batch_size,-1).astype(np.float64)
return state0_batch, action_batch, reward_batch, state1_batch, terminal1_batch
def append(self, observation, action, reward, terminal, training=True):
super(SequentialMemory, self).append(observation, action, reward, terminal, training=training)
# This needs to be understood as follows: in `observation`, take `action`, obtain `reward`
# and weather the next state is `terminal` or not.
if training:
self.observations.append(observation)
self.actions.append(action)
self.rewards.append(reward)
self.terminals.append(terminal)
@property
def nb_entries(self):
return len(self.observations)
def get_config(self):
config = super(SequentialMemory, self).get_config()
config['limit'] = self.limit
return config
class EpisodeParameterMemory(Memory):
def __init__(self, limit, **kwargs):
super(EpisodeParameterMemory, self).__init__(**kwargs)
self.limit = limit
self.params = RingBuffer(limit)
self.intermediate_rewards = []
self.total_rewards = RingBuffer(limit)
def sample(self, batch_size, batch_idxs=None):
if batch_idxs is None:
batch_idxs = sample_batch_indexes(0, self.nb_entries, size=batch_size)
assert len(batch_idxs) == batch_size
batch_params = []
batch_total_rewards = []
for idx in batch_idxs:
batch_params.append(self.params[idx])
batch_total_rewards.append(self.total_rewards[idx])
return batch_params, batch_total_rewards
def append(self, observation, action, reward, terminal, training=True):
super(EpisodeParameterMemory, self).append(observation, action, reward, terminal, training=training)
if training:
self.intermediate_rewards.append(reward)
def finalize_episode(self, params):
total_reward = sum(self.intermediate_rewards)
self.total_rewards.append(total_reward)
self.params.append(params)
self.intermediate_rewards = []
@property
def nb_entries(self):
return len(self.total_rewards)
def get_config(self):
config = super(SequentialMemory, self).get_config()
config['limit'] = self.limit
return config
There are two types of memory - Sequential and Episodic.
Model¶
from src import model
Code(inspect.getsource(model), language='python')
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
# from ipdb import set_trace as debug
def fanin_init(size, fanin=None):
fanin = fanin or size[0]
v = 1. / np.sqrt(fanin)
return torch.Tensor(size).uniform_(-v, v)
class Actor(nn.Module):
def __init__(self, nb_states, nb_actions, hidden1=256, hidden2=128, init_w=3e-3):
super(Actor, self).__init__()
self.fc1 = nn.Linear(nb_states, hidden1)
self.fc2 = nn.Linear(hidden1, hidden2)
self.fc3 = nn.Linear(hidden2, nb_actions)
self.relu = nn.ReLU()
# self.tanh = nn.Tanh()
self.softsign = nn.Softsign()
self.init_weights(init_w)
def init_weights(self, init_w):
self.fc1.weight.data = fanin_init(self.fc1.weight.data.size())
self.fc2.weight.data = fanin_init(self.fc2.weight.data.size())
self.fc3.weight.data.uniform_(-init_w, init_w)
def forward(self, x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
out = self.relu(out)
out = self.fc3(out)
# out = self.tanh(out)
out = self.softsign(out)
return out
class Critic(nn.Module):
def __init__(self, nb_states, nb_actions, hidden1=256, hidden2=128, init_w=3e-3):
super(Critic, self).__init__()
self.fc1 = nn.Linear(nb_states, hidden1)
self.fc2 = nn.Linear(hidden1+nb_actions, hidden2)
self.fc3 = nn.Linear(hidden2, 1)
self.relu = nn.ReLU()
self.init_weights(init_w)
def init_weights(self, init_w):
self.fc1.weight.data = fanin_init(self.fc1.weight.data.size())
self.fc2.weight.data = fanin_init(self.fc2.weight.data.size())
self.fc3.weight.data.uniform_(-init_w, init_w)
def forward(self, xs):
x, a = xs
out = self.fc1(x)
out = self.relu(out)
# concatenate along columns
c_in = torch.cat([out,a],len(a.shape)-1)
out = self.fc2(c_in)
out = self.relu(out)
out = self.fc3(out)
return out
We have 2 NN models - Actor and Critic.
Action space¶
from src import action_space
Code(inspect.getsource(action_space), language='python')
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# [reference] Use and modified code in https://github.com/jimkon/Deep-Reinforcement-Learning-in-Large-Discrete-Action-Spaces
import numpy as np
import itertools
import pyflann
"""
This class represents a n-dimensional unit cube with a specific number of points embeded.
Points are distributed uniformly in the initialization. A search can be made using the
search_point function that returns the k (given) nearest neighbors of the input point.
"""
class Space:
def __init__(self, low, high, points):
self._low = np.array(low)
self._high = np.array(high)
self._range = self._high - self._low
self._dimensions = len(low)
self._space_low = -1
self._space_high = 1
self._k = (self._space_high - self._space_low) / self._range
self.__space = init_uniform_space([self._space_low] * self._dimensions,
[self._space_high] * self._dimensions,
points)
self._flann = pyflann.FLANN()
self.rebuild_flann()
def rebuild_flann(self):
self._index = self._flann.build_index(self.__space, algorithm='kdtree')
def search_point(self, point, k):
p_in = point
if not isinstance(point, np.ndarray):
p_in = np.array([p_in]).astype(np.float64)
# p_in = self.import_point(point)
search_res, _ = self._flann.nn_index(p_in, k)
knns = self.__space[search_res]
p_out = []
for p in knns:
p_out.append(self.export_point(p))
if k == 1:
p_out = [p_out]
return knns, np.array(p_out)
def import_point(self, point):
return self._space_low + self._k * (point - self._low)
def export_point(self, point):
return self._low + (point - self._space_low) / self._k
def get_space(self):
return self.__space
def shape(self):
return self.__space.shape
def get_number_of_actions(self):
return self.shape()[0]
class Discrete_space(Space):
"""
Discrete action space with n actions (the integers in the range [0, n))
1, 2, ..., n-1, n
In gym: 'Discrete' object has no attribute 'high'
"""
def __init__(self, n): # n: the number of the discrete actions
super().__init__([0], [n-1], n)
def export_point(self, point):
return np.round(super().export_point(point)).astype(int)
def init_uniform_space(low, high, points):
dims = len(low)
# In Discrete situation, the action space is an one dimensional space, i.e., one row
points_in_each_axis = round(points**(1 / dims))
axis = []
for i in range(dims):
axis.append(list(np.linspace(low[i], high[i], points_in_each_axis)))
space = []
for _ in itertools.product(*axis):
space.append(list(_))
# space: e.g., [[1], [2], ... ,[n-1]]
return np.array(space)
'''
test
'''
#
# ds = Space([-2], [2], 200000)
# output, output_2 = ds.search_point(1.4123456765373, 4)
# print(output_2)
# print(output_2.shape)