REINFORCE in PyTorch¶
!pip install -q watermark
%reload_ext watermark
%watermark -m -iv -u -t -d
Last updated: 2021-10-22 13:08:10
Compiler : GCC 7.5.0
OS : Linux
Release : 5.4.104+
Machine : x86_64
Processor : x86_64
CPU cores : 2
Architecture: 64bit
gym : 0.17.3
numpy : 1.19.5
torch : 1.9.0+cu111
matplotlib: 3.2.2
IPython : 5.5.0
!pip install gym pyvirtualdisplay > /dev/null 2>&1
!apt-get install -y xvfb python-opengl ffmpeg > /dev/null 2>&1
!apt-get update > /dev/null 2>&1
!apt-get install cmake > /dev/null 2>&1
!pip install --upgrade setuptools 2>&1
!pip install ez_setup > /dev/null 2>&1
!pip install gym[atari] > /dev/null 2>&1
!wget http://www.atarimania.com/roms/Roms.rar
!mkdir /content/ROM/
!unrar e /content/Roms.rar /content/ROM/
!python -m atari_py.import_roms /content/ROM/
import gym
from gym.wrappers import Monitor
import glob
import io
import base64
from IPython.display import HTML
from pyvirtualdisplay import Display
from IPython import display as ipythondisplay
display = Display(visible=0, size=(1400, 900))
display.start()
"""
Utility functions to enable video recording of gym environment
and displaying it.
To enable video, just do "env = wrap_env(env)""
"""
def show_video():
mp4list = glob.glob('video/*.mp4')
if len(mp4list) > 0:
mp4 = mp4list[0]
video = io.open(mp4, 'r+b').read()
encoded = base64.b64encode(video)
ipythondisplay.display(HTML(data='''<video alt="test" autoplay
loop controls style="height: 400px;">
<source src="data:video/mp4;base64,{0}" type="video/mp4" />
</video>'''.format(encoded.decode('ascii'))))
else:
print("Could not find video")
def wrap_env(env):
env = Monitor(env, './video', force=True)
return env
import gym
import numpy as np
from collections import deque
import matplotlib.pyplot as plt
%matplotlib inline
import torch
torch.manual_seed(0) # set random seed
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Categorical
env = gym.make('CartPole-v0')
env.seed(0)
print('observation space:', env.observation_space)
print('action space:', env.action_space)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
class Policy(nn.Module):
def __init__(self, s_size=4, h_size=16, a_size=2):
super(Policy, self).__init__()
self.fc1 = nn.Linear(s_size, h_size)
self.fc2 = nn.Linear(h_size, a_size)
def forward(self, x):
x = F.relu(self.fc1(x))
x = self.fc2(x)
return F.softmax(x, dim=1)
def act(self, state):
state = torch.from_numpy(state).float().unsqueeze(0).to(device)
probs = self.forward(state).cpu()
m = Categorical(probs)
action = m.sample()
return action.item(), m.log_prob(action)
observation space: Box(-3.4028234663852886e+38, 3.4028234663852886e+38, (4,), float32)
action space: Discrete(2)
policy = Policy().to(device)
optimizer = optim.Adam(policy.parameters(), lr=1e-2)
def reinforce(n_episodes=1000, max_t=1000, gamma=1.0, print_every=100):
scores_deque = deque(maxlen=100)
scores = []
for i_episode in range(1, n_episodes+1):
saved_log_probs = []
rewards = []
state = env.reset()
for t in range(max_t):
action, log_prob = policy.act(state)
saved_log_probs.append(log_prob)
state, reward, done, _ = env.step(action)
rewards.append(reward)
if done:
break
scores_deque.append(sum(rewards))
scores.append(sum(rewards))
discounts = [gamma**i for i in range(len(rewards)+1)]
R = sum([a*b for a,b in zip(discounts, rewards)])
policy_loss = []
for log_prob in saved_log_probs:
policy_loss.append(-log_prob * R)
policy_loss = torch.cat(policy_loss).sum()
optimizer.zero_grad()
policy_loss.backward()
optimizer.step()
if i_episode % print_every == 0:
print('Episode {}\tAverage Score: {:.2f}'.format(i_episode, np.mean(scores_deque)))
if np.mean(scores_deque)>=195.0:
print('Environment solved in {:d} episodes!\tAverage Score: {:.2f}'.format(i_episode-100, np.mean(scores_deque)))
break
return scores
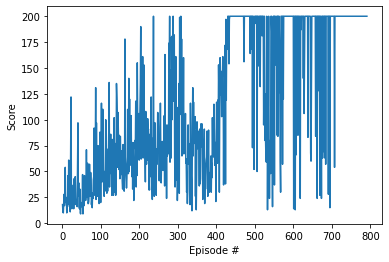
scores = reinforce()
Episode 100 Average Score: 34.47
Episode 200 Average Score: 66.26
Episode 300 Average Score: 87.82
Episode 400 Average Score: 72.83
Episode 500 Average Score: 172.00
Episode 600 Average Score: 160.65
Episode 700 Average Score: 167.15
Environment solved in 691 episodes! Average Score: 196.69
fig = plt.figure()
ax = fig.add_subplot(111)
plt.plot(np.arange(1, len(scores)+1), scores)
plt.ylabel('Score')
plt.xlabel('Episode #')
plt.show()
env = wrap_env(gym.make('CartPole-v0'))
state = env.reset()
for t in range(1000):
action, _ = policy.act(state)
env.render()
state, reward, done, _ = env.step(action)
if done:
break
env.close()
show_video()