Contextual Recommender with Vowpal Wabbit¶
We will simulate the scenario of personalizing news content on a site, using CB, to users. The goal is to maximize user engagement quantified by measuring click through rate (CTR).
Let’s recall that in a CB setting, a data point has four components,
Context
Action
Probability of choosing action
Reward/cost for chosen action
We will need to generate a context, get an action/decision for the given context and also simulate generating a reward. We have two website visitors: ‘Tom’ and ‘Anna’ Each of them may visit the website either in the morning or in the afternoon. The context is therefore (user, time_of_day). We have the option of recommending a variety of articles to Tom and Anna. Therefore, actions are the different choices of articles: “politics”, “sports”, “music”, “food”, “finance”, “health”, “cheese”. The reward is whether they click on the article or not: ‘click’ or ‘no click’.
Setup¶
Installations¶
!pip install vowpalwabbit
Imports¶
from vowpalwabbit import pyvw
import random
import matplotlib.pyplot as plt
import pandas as pd
import itertools
from itertools import product
import numpy as np
import scipy
import scipy.stats as stats
Simulate reward¶
In the real world, we will have to learn Tom and Anna’s preferences for articles as we observe their interactions. Since this is a simulation, we will have to define Tom and Anna’s preference profile. The reward that we provide to the learner will follow this preference profile. Our hope is to see if the learner can take better and better decisions as we see more samples which in turn means we are maximizing the reward.
We will also modify the reward function in a few different ways and see if the CB learner picks up the changes. We will compare the CTR with and without learning.
VW optimizes to minimize cost which is negative of reward. Therefore, we will always pass negative of reward as cost to VW.
# VW tries to minimize loss/cost, therefore we will pass cost as -reward
USER_LIKED_ARTICLE = -1.0
USER_DISLIKED_ARTICLE = 0.0
The reward function below specifies that Tom likes politics in the morning and music in the afternoon whereas Anna likes sports in the morning and politics in the afternoon. It looks dense but we are just simulating our hypothetical world in the format of the feedback the learner understands: cost. If the learner recommends an article that aligns with the reward function, we give a positive reward. In our simulated world this is a click.
def get_cost(context,action):
if context['user'] == "Tom":
if context['time_of_day'] == "morning" and action == 'politics':
return USER_LIKED_ARTICLE
elif context['time_of_day'] == "afternoon" and action == 'music':
return USER_LIKED_ARTICLE
else:
return USER_DISLIKED_ARTICLE
elif context['user'] == "Anna":
if context['time_of_day'] == "morning" and action == 'sports':
return USER_LIKED_ARTICLE
elif context['time_of_day'] == "afternoon" and action == 'politics':
return USER_LIKED_ARTICLE
else:
return USER_DISLIKED_ARTICLE
Understanding VW format¶
There are some things we need to do to get our input into a format VW understands. This function handles converting from our context as a dictionary, list of articles and the cost if there is one into the text format VW understands.
# This function modifies (context, action, cost, probability) to VW friendly format
def to_vw_example_format(context, actions, cb_label = None):
if cb_label is not None:
chosen_action, cost, prob = cb_label
example_string = ""
example_string += "shared |User user={} time_of_day={}\n".format(context["user"], context["time_of_day"])
for action in actions:
if cb_label is not None and action == chosen_action:
example_string += "0:{}:{} ".format(cost, prob)
example_string += "|Action article={} \n".format(action)
#Strip the last newline
return example_string[:-1]
To understand what’s going on here let’s go through an example. Here, it’s the morning and the user is Tom. There are four possible articles. So in the VW format there is one line that starts with shared, this is the shared context, followed by four lines each corresponding to an article.
context = {"user":"Tom","time_of_day":"morning"}
actions = ["politics", "sports", "music", "food"]
print(to_vw_example_format(context,actions))
shared |User user=Tom time_of_day=morning
|Action article=politics
|Action article=sports
|Action article=music
|Action article=food
Getting a decision¶
When we call VW we get a pmf, probability mass function, as the output. Since we are incorporating exploration into our strategy, VW will give us a list of probabilities over the set of actions. This means that the probability at a given index in the list corresponds to the likelihood of picking that specific action. In order to arrive at a decision/action, we will have to sample from this list.
So, given a list [0.7, 0.1, 0.1, 0.1], we would choose the first item with a 70% chance. sample_custom_pmf takes such a list and gives us the index it chose and what the probability of choosing that index was.
def sample_custom_pmf(pmf):
total = sum(pmf)
scale = 1/total
pmf = [x * scale for x in pmf]
draw = random.random()
sum_prob = 0.0
for index, prob in enumerate(pmf):
sum_prob += prob
if(sum_prob > draw):
return index, prob
We have all of the information we need to choose an action for a specific user and context. To use VW to achieve this, we will do the following:
We convert our context and actions into the text format we need
We pass this example to vw and get the pmf out
Now, we sample this pmf to get what article we will end up showing
Finally we return the article chosen, and the probability of choosing it (we are going to need the probability when we learn form this example)
def get_action(vw, context, actions):
vw_text_example = to_vw_example_format(context,actions)
pmf = vw.predict(vw_text_example)
chosen_action_index, prob = sample_custom_pmf(pmf)
return actions[chosen_action_index], prob
Simulation set up¶
Now that we have done all of the setup work and know how to interface with VW, let’s simulate the world of Tom and Anna. The scenario is they go to a website and are shown an article. Remember that the reward function allows us to define the worlds reaction to what VW recommends.
We will choose between Tom and Anna uniformly at random and also choose their time of visit uniformly at random. You can think of this as us tossing a coin to choose between Tom and Anna (Anna if heads and Tom if tails) and another coin toss for choosing time of day.
users = ['Tom', 'Anna']
times_of_day = ['morning', 'afternoon']
actions = ["politics", "sports", "music", "food", "finance", "health", "camping"]
def choose_user(users):
return random.choice(users)
def choose_time_of_day(times_of_day):
return random.choice(times_of_day)
# display preference matrix
def get_preference_matrix(cost_fun):
def expand_grid(data_dict):
rows = itertools.product(*data_dict.values())
return pd.DataFrame.from_records(rows, columns=data_dict.keys())
df = expand_grid({'users':users, 'times_of_day': times_of_day, 'actions': actions})
df['cost'] = df.apply(lambda r: cost_fun({'user': r[0], 'time_of_day': r[1]}, r[2]), axis=1)
return df.pivot_table(index=['users', 'times_of_day'],
columns='actions',
values='cost')
get_preference_matrix(get_cost)
| actions | camping | finance | food | health | music | politics | sports | |
|---|---|---|---|---|---|---|---|---|
| users | times_of_day | |||||||
| Anna | afternoon | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | -1.0 | 0.0 |
| morning | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | -1.0 | |
| Tom | afternoon | 0.0 | 0.0 | 0.0 | 0.0 | -1.0 | 0.0 | 0.0 |
| morning | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | -1.0 | 0.0 |
We will instantiate a CB learner in VW and then simulate Tom and Anna’s website visits num_iterations number of times. In each visit, we:
Decide between Tom and Anna
Decide time of day
Pass context i.e. (user, time of day) to learner to get action i.e. article recommendation and probability of choosing action
Receive reward i.e. see if user clicked or not. Remember that cost is just negative reward.
Format context, action, probability, reward in VW format
Learn from the example
VW reduces a CB problem to a cost sensitive multiclass classification problem.
This is the same for every one of our simulations, so we define the process in the run_simulation function. The cost function must be supplied as this is essentially us simulating how the world works.
def run_simulation(vw, num_iterations, users, times_of_day, actions, cost_function, do_learn = True):
cost_sum = 0.
ctr = []
for i in range(1, num_iterations+1):
# 1. In each simulation choose a user
user = choose_user(users)
# 2. Choose time of day for a given user
time_of_day = choose_time_of_day(times_of_day)
# 3. Pass context to vw to get an action
context = {'user': user, 'time_of_day': time_of_day}
action, prob = get_action(vw, context, actions)
# 4. Get cost of the action we chose
cost = cost_function(context, action)
cost_sum += cost
if do_learn:
# 5. Inform VW of what happened so we can learn from it
vw_format = vw.parse(to_vw_example_format(context, actions, (action, cost, prob)),pyvw.vw.lContextualBandit)
# 6. Learn
vw.learn(vw_format)
# We negate this so that on the plot instead of minimizing cost, we are maximizing reward
ctr.append(-1*cost_sum/i)
return ctr
We want to be able to visualize what is occurring, so we are going to plot the click through rate over each iteration of the simulation. If VW is showing actions the get rewards the ctr will be higher. Below is a little utility function to make showing the plot easier.
def plot_ctr(num_iterations, ctr):
plt.plot(range(1,num_iterations+1), ctr)
plt.xlabel('num_iterations', fontsize=14)
plt.ylabel('ctr', fontsize=14)
plt.ylim([0,1])
Scenario 1¶
We will use the first reward function get_cost and assume that Tom and Anna do not change their preferences over time and see what happens to user engagement as we learn. We will also see what happens when there is no learning. We will use the “no learning” case as our baseline to compare to.
With learning¶
# Instantiate learner in VW
vw = pyvw.vw("--cb_explore_adf -q UA --quiet --epsilon 0.2")
num_iterations = 5000
ctr = run_simulation(vw, num_iterations, users, times_of_day, actions, get_cost)
plot_ctr(num_iterations, ctr)
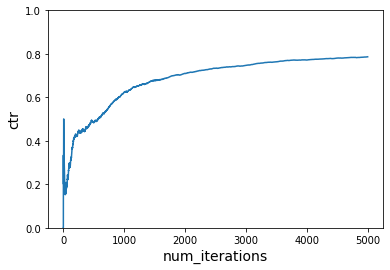
Aside: interactions
You’ll notice in the arguments we supply to VW, we include -q UA. This is telling VW to create additional features which are the features in the (U)ser namespace and (A)ction namespaces multiplied together. This allows us to learn the interaction between when certain actions are good in certain times of days and for particular users. If we didn’t do that, the learning wouldn’t really work. We can see that in action below.
# Instantiate learner in VW but without -q
vw = pyvw.vw("--cb_explore_adf --quiet --epsilon 0.2")
num_iterations = 5000
ctr = run_simulation(vw, num_iterations, users, times_of_day, actions, get_cost)
plot_ctr(num_iterations, ctr)
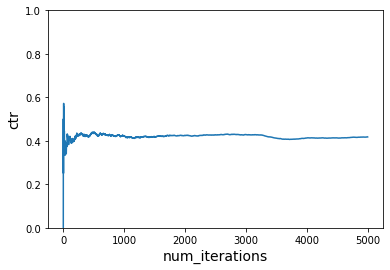
Without learning¶
Let’s do the same thing again (but with -q, but this time show the effect if we don’t learn from what happens. The ctr never improves are we just hover around 0.2.
# Instantiate learner in VW
vw = pyvw.vw("--cb_explore_adf -q UA --quiet --epsilon 0.2")
num_iterations = 5000
ctr = run_simulation(vw, num_iterations, users, times_of_day, actions, get_cost, do_learn=False)
plot_ctr(num_iterations, ctr)
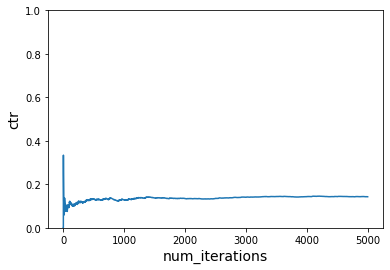
Scenario 2¶
In the real world people’s preferences change over time. So now in the simulation we are going to incorporate two different cost functions, and swap over to the second one halfway through. Below is a a table of the new reward function we are going to use, get_cost_1:
Tom¶
|
|
|
|---|---|---|
Morning |
Politics |
Politics |
Afternoon |
Music |
Sports |
Anna¶
|
|
|
|---|---|---|
Morning |
Sports |
Sports |
Afternoon |
Politics |
Sports |
This reward function is still working with actions that the learner has seen previously.
def get_cost_new1(context,action):
if context['user'] == "Tom":
if context['time_of_day'] == "morning" and action == 'politics':
return USER_LIKED_ARTICLE
elif context['time_of_day'] == "afternoon" and action == 'sports':
return USER_LIKED_ARTICLE
else:
return USER_DISLIKED_ARTICLE
elif context['user'] == "Anna":
if context['time_of_day'] == "morning" and action == 'sports':
return USER_LIKED_ARTICLE
elif context['time_of_day'] == "afternoon" and action == 'sports':
return USER_LIKED_ARTICLE
else:
return USER_DISLIKED_ARTICLE
get_preference_matrix(get_cost_new1)
| actions | camping | finance | food | health | music | politics | sports | |
|---|---|---|---|---|---|---|---|---|
| users | times_of_day | |||||||
| Anna | afternoon | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | -1.0 |
| morning | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | -1.0 | |
| Tom | afternoon | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | -1.0 |
| morning | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | -1.0 | 0.0 |
To make it easy to show the effect of the cost function changing we are going to modify the run_simulation function. It is a little less readable now, but it supports accepting a list of cost functions and it will operate over each cost function in turn. This is perfect for what we need.
def run_simulation_multiple_cost_functions(vw, num_iterations, users, times_of_day, actions, cost_functions, do_learn = True):
cost_sum = 0.
ctr = []
start_counter = 1
end_counter = start_counter + num_iterations
for cost_function in cost_functions:
for i in range(start_counter, end_counter):
# 1. in each simulation choose a user
user = choose_user(users)
# 2. choose time of day for a given user
time_of_day = choose_time_of_day(times_of_day)
# Construct context based on chosen user and time of day
context = {'user': user, 'time_of_day': time_of_day}
# 3. Use the get_action function we defined earlier
action, prob = get_action(vw, context, actions)
# 4. Get cost of the action we chose
cost = cost_function(context, action)
cost_sum += cost
if do_learn:
# 5. Inform VW of what happened so we can learn from it
vw_format = vw.parse(to_vw_example_format(context, actions, (action, cost, prob)),pyvw.vw.lContextualBandit)
# 6. Learn
vw.learn(vw_format)
# We negate this so that on the plot instead of minimizing cost, we are maximizing reward
ctr.append(-1*cost_sum/i)
start_counter = end_counter
end_counter = start_counter + num_iterations
def run_simulation_multiple_cost_functions(vw, num_iterations, users, times_of_day, actions, cost_functions, do_learn = True):
cost_sum = 0.
ctr = []
start_counter = 1
end_counter = start_counter + num_iterations
for cost_function in cost_functions:
for i in range(start_counter, end_counter):
# 1. in each simulation choose a user
user = choose_user(users)
# 2. choose time of day for a given user
time_of_day = choose_time_of_day(times_of_day)
# Construct context based on chosen user and time of day
context = {'user': user, 'time_of_day': time_of_day}
# 3. Use the get_action function we defined earlier
action, prob = get_action(vw, context, actions)
# 4. Get cost of the action we chose
cost = cost_function(context, action)
cost_sum += cost
if do_learn:
# 5. Inform VW of what happened so we can learn from it
vw_format = vw.parse(to_vw_example_format(context, actions, (action, cost, prob)),pyvw.vw.lContextualBandit)
# 6. Learn
vw.learn(vw_format)
# We negate this so that on the plot instead of minimizing cost, we are maximizing reward
ctr.append(-1*cost_sum/i)
start_counter = end_counter
end_counter = start_counter + num_iterations
return ctr
With learning¶
Let us now switch to the second reward function after a few samples (running the first reward function). Recall that this reward function changes the preferences of the web users but it is still working with the same action space as before. We should see the learner pick up these changes and optimize towards the new preferences.
# use first reward function initially and then switch to second reward function
# Instantiate learner in VW
vw = pyvw.vw("--cb_explore_adf -q UA --quiet --epsilon 0.2")
num_iterations_per_cost_func = 5000
cost_functions = [get_cost, get_cost_new1]
total_iterations = num_iterations_per_cost_func * len(cost_functions)
ctr = run_simulation_multiple_cost_functions(vw, num_iterations_per_cost_func, users, times_of_day, actions, cost_functions)
plot_ctr(total_iterations, ctr)
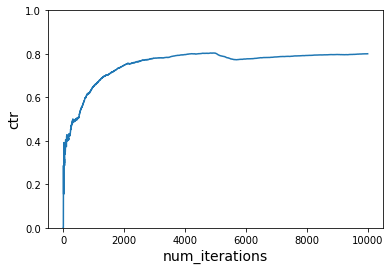
Note: The initial spike in CTR depends on the rewards received for the first few examples. When you run on your own, you may see something different initially because our simulator is designed to have randomness.
Without learning¶
# Do not learn
# use first reward function initially and then switch to second reward function
# Instantiate learner in VW
vw = pyvw.vw("--cb_explore_adf -q UA --quiet --epsilon 0.2")
num_iterations_per_cost_func = 5000
cost_functions = [get_cost, get_cost_new1]
total_iterations = num_iterations_per_cost_func * len(cost_functions)
ctr = run_simulation_multiple_cost_functions(vw, num_iterations_per_cost_func, users, times_of_day, actions, cost_functions, do_learn=False)
plot_ctr(total_iterations, ctr)
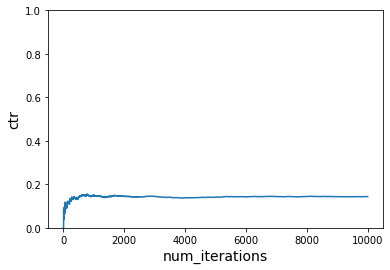
Scenario 3¶
In this scenario we are going to start rewarding actions that have never seen a reward previously when we change the cost function.
Tom¶
|
|
|
|---|---|---|
Morning |
Politics |
Politics |
Afternoon |
Music |
Food |
Anna¶
|
|
|
|---|---|---|
Morning |
Sports |
Food |
Afternoon |
Politics |
Food |
def get_cost_new2(context,action):
if context['user'] == "Tom":
if context['time_of_day'] == "morning" and action == 'politics':
return USER_LIKED_ARTICLE
elif context['time_of_day'] == "afternoon" and action == 'food':
return USER_LIKED_ARTICLE
else:
return USER_DISLIKED_ARTICLE
elif context['user'] == "Anna":
if context['time_of_day'] == "morning" and action == 'food':
return USER_LIKED_ARTICLE
elif context['time_of_day'] == "afternoon" and action == 'food':
return USER_LIKED_ARTICLE
else:
return USER_DISLIKED_ARTICLE
With learning¶
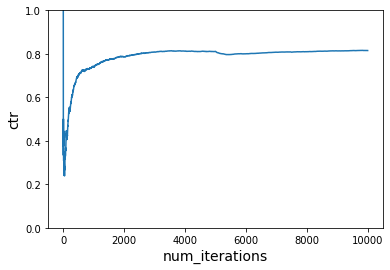
Let us now switch to the third reward function after a few samples (running the first reward function). Recall that this reward function changes the preferences of the users and is working with a different action space than before. We should see the learner pick up these changes and optimize towards the new preferences
# use first reward function initially and then switch to third reward function
# Instantiate learner in VW
vw = pyvw.vw("--cb_explore_adf -q UA --quiet --epsilon 0.2")
num_iterations_per_cost_func = 5000
cost_functions = [get_cost, get_cost_new2]
total_iterations = num_iterations_per_cost_func * len(cost_functions)
ctr = run_simulation_multiple_cost_functions(vw, num_iterations_per_cost_func, users, times_of_day, actions, cost_functions)
plot_ctr(total_iterations, ctr)
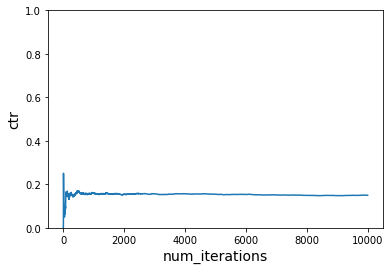
Without Learning¶
# Do not learn
# use first reward function initially and then switch to third reward function
# Instantiate learner in VW
vw = pyvw.vw("--cb_explore_adf -q UA --quiet --epsilon 0.2")
num_iterations_per_cost_func = 5000
cost_functions = [get_cost, get_cost_new2]
total_iterations = num_iterations_per_cost_func * len(cost_functions)
ctr = run_simulation_multiple_cost_functions(vw, num_iterations_per_cost_func, users, times_of_day, actions, cost_functions, do_learn=False)
plot_ctr(total_iterations, ctr)
This section aimed at showcasing a real world scenario where contextual bandit algorithms can be used. We were able to take a context and set of actions and learn what actions worked best for a given context. We saw that the learner was able to respond rapidly to changes in the world. We showed that allowing the learner to interact with the world resulted in higher rewards than the no learning baseline. We worked with simplistic features. VW supports high dimensional sparse features, different exploration algorithms and policy evaluation approaches.
Contextual bandit with changing context¶
Customizing the context and changing it midway to see how fast the agent can adapt to the new context and start recommending better products as per the context
Setting the context¶
We have 3 users and 6 items. Context 1 is time of day - morning and evening. Context 2 is season - summer and winter.
Ground truth rules:
User 1 likes Item 1 in morning, and Item 6 in summer
User 2 likes Item 2 in winter, and Item 5 in summer morning
User 3 likes Item 2 in morning, Item 3 in evening, and item 4 in winter morning
USER_LIKED_ARTICLE = -1.0
USER_DISLIKED_ARTICLE = 0.0
users = ['A','B','C']
items = ['Item1','Item2','Item3','Item4','Item5','Item6']
context1 = ['morning','evening']
context2 = ['summer','winter']
context = pd.DataFrame(list(product(users, context1, context2, items)), columns=['users', 'context1', 'context2', 'items'])
context['reward'] = 0
#user 1 likes Item 1 in morning, and Item 6 in summer
context.loc[(context.users=='A') & \
(context.context1=='morning') & \
(context['items']=='Item1'), \
'reward'] = 1
context.loc[(context.users=='A') & \
(context.context2=='summer') & \
(context['items']=='Item6'), \
'reward'] = 1
#user 2 likes Item 2 in winter, and Item 5 in summer morning
context.loc[(context.users=='B') & \
(context.context2=='winter') & \
(context['items']=='Item2'), \
'reward'] = 1
context.loc[(context.users=='B') & \
(context.context1=='morning') & \
(context.context2=='summer') & \
(context['items']=='Item5'), \
'reward'] = 1
#user 3 likes Item 2 in morning, Item 3 in evening, and item 4 in winter morning
context.loc[(context.users=='C') & \
(context.context1=='morning') & \
(context['items']=='Item2'), \
'reward'] = 1
context.loc[(context.users=='C') & \
(context.context1=='evening') & \
(context['items']=='Item3'), \
'reward'] = 1
context.loc[(context.users=='C') & \
(context.context1=='morning') & \
(context.context2=='winter') & \
(context['items']=='Item4'), \
'reward'] = 1
context['cost'] = context['reward']*-1
contextdf = context.copy()
contextdf.cost.value_counts()
0 60
-1 12
Name: cost, dtype: int64
Cost function util¶
def get_cost(context,action):
return contextdf.loc[(contextdf['users']==context['user']) & \
(contextdf.context1==context['context1']) & \
(contextdf.context2==context['context2']) & \
(contextdf['items']==action), \
'cost'].values[0]
get_cost({'user':'A','context1':'morning','context2':'summer'},'Item2')
0
Vowpalwabbit format util¶
# This function modifies (context, action, cost, probability) to VW friendly format
def to_vw_example_format(context, actions, cb_label = None):
if cb_label is not None:
chosen_action, cost, prob = cb_label
example_string = ""
example_string += "shared |User users={} context1={} context2={}\n".format(context["user"], context["context1"], context["context2"])
for action in actions:
if cb_label is not None and action == chosen_action:
example_string += "0:{}:{} ".format(cost, prob)
example_string += "|Action items={} \n".format(action)
#Strip the last newline
return example_string[:-1]
context = {"user":"A","context1":"morning","context2":"summer"}
print(to_vw_example_format(context,items))
shared |User users=A context1=morning context2=summer
|Action items=Item1
|Action items=Item2
|Action items=Item3
|Action items=Item4
|Action items=Item5
|Action items=Item6
def sample_custom_pmf(pmf):
total = sum(pmf)
scale = 1 / total
pmf = [x * scale for x in pmf]
draw = random.random()
sum_prob = 0.0
for index, prob in enumerate(pmf):
sum_prob += prob
if(sum_prob > draw):
return index, prob
def get_action(vw, context, actions):
vw_text_example = to_vw_example_format(context,actions)
pmf = vw.predict(vw_text_example)
chosen_action_index, prob = sample_custom_pmf(pmf)
return actions[chosen_action_index], prob
def choose_user(users):
return random.choice(users)
def choose_context1(context1):
return random.choice(context1)
def choose_context2(context2):
return random.choice(context2)
def run_simulation(vw, num_iterations, users, contexts1, contexts2, actions, cost_function, do_learn = True):
cost_sum = 0.
ctr = []
for i in range(1, num_iterations+1):
user = choose_user(users)
context1 = choose_context1(contexts1)
context2 = choose_context2(contexts2)
context = {'user': user, 'context1': context1, 'context2': context2}
# print(context)
action, prob = get_action(vw, context, actions)
# print(action, prob)
cost = cost_function(context, action)
# print(cost)
cost_sum += cost
if do_learn:
# 5. Inform VW of what happened so we can learn from it
vw_format = vw.parse(to_vw_example_format(context, actions, (action, cost, prob)),pyvw.vw.lContextualBandit)
# 6. Learn
vw.learn(vw_format)
# 7. Let VW know you're done with these objects
vw.finish_example(vw_format)
# We negate this so that on the plot instead of minimizing cost, we are maximizing reward
ctr.append(-1*cost_sum/i)
return ctr
def plot_ctr(num_iterations, ctr):
plt.plot(range(1,num_iterations+1), ctr)
plt.xlabel('num_iterations', fontsize=14)
plt.ylabel('ctr', fontsize=14)
plt.ylim([0,1])
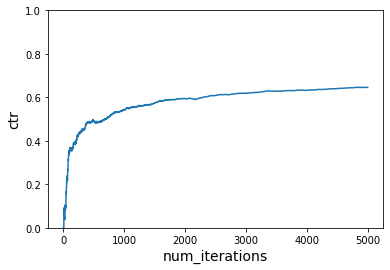
# Instantiate learner in VW
vw = pyvw.vw("--cb_explore_adf -q UA --quiet --epsilon 0.2")
num_iterations = 5000
ctr = run_simulation(vw, num_iterations, users, context1, context2, items, get_cost)
plot_ctr(num_iterations, ctr)
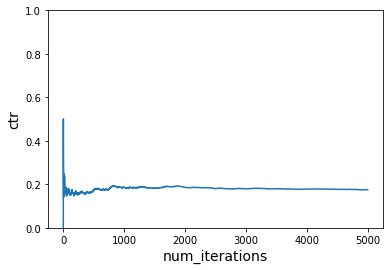
# Instantiate learner in VW but without -q
vw = pyvw.vw("--cb_explore_adf --quiet --epsilon 0.2")
num_iterations = 5000
ctr = run_simulation(vw, num_iterations, users, context1, context2, items, get_cost)
plot_ctr(num_iterations, ctr)
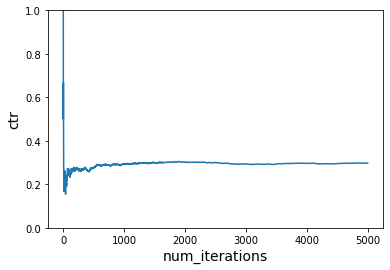
# Instantiate learner in VW
vw = pyvw.vw("--cb_explore_adf -q UA --quiet --epsilon 0.2")
num_iterations = 5000
ctr = run_simulation(vw, num_iterations, users, context1, context2, items, get_cost, do_learn=False)
plot_ctr(num_iterations, ctr)
Changing the context¶
Updated ground truth rules:
User 1 likes Item 2 in morning, and Item 5 in summer
User 2 likes Item 2 in summer, and Item 5 in morning
User 3 likes Item 4 in morning, Item 3 in evening, and item 4 in winter evening
users = ['A','B','C']
items = ['Item1','Item2','Item3','Item4','Item5','Item6']
context1 = ['morning','evening']
context2 = ['summer','winter']
context = pd.DataFrame(list(product(users, context1, context2, items)), columns=['users', 'context1', 'context2', 'items'])
context['reward'] = 0
#user 1 likes Item 2 in morning, and Item 5 in summer
context.loc[(context.users=='A') & \
(context.context1=='morning') & \
(context['items']=='Item2'), \
'reward'] = 1
context.loc[(context.users=='A') & \
(context.context2=='summer') & \
(context['items']=='Item5'), \
'reward'] = 1
#user 2 likes Item 2 in summer, and Item 5 in morning
context.loc[(context.users=='B') & \
(context.context2=='summer') & \
(context['items']=='Item2'), \
'reward'] = 1
context.loc[(context.users=='B') & \
(context.context1=='morning') & \
(context['items']=='Item5'), \
'reward'] = 1
#user 3 likes Item 4 in morning, Item 3 in evening, and item 4 in winter evening
context.loc[(context.users=='C') & \
(context.context1=='morning') & \
(context['items']=='Item4'), \
'reward'] = 1
context.loc[(context.users=='C') & \
(context.context1=='evening') & \
(context['items']=='Item3'), \
'reward'] = 1
context.loc[(context.users=='C') & \
(context.context1=='evening') & \
(context.context2=='winter') & \
(context['items']=='Item4'), \
'reward'] = 1
context['cost'] = context['reward']*-1
contextdf_new = context.copy()
def get_cost_new1(context,action):
return contextdf_new.loc[(contextdf_new['users']==context['user']) & \
(contextdf_new.context1==context['context1']) & \
(contextdf_new.context2==context['context2']) & \
(contextdf_new['items']==action), \
'cost'].values[0]
def run_simulation_multiple_cost_functions(vw, num_iterations, users, contexts1, contexts2, actions, cost_functions, do_learn = True):
cost_sum = 0.
ctr = []
start_counter = 1
end_counter = start_counter + num_iterations
for cost_function in cost_functions:
for i in range(start_counter, end_counter):
user = choose_user(users)
context1 = choose_context1(contexts1)
context2 = choose_context2(contexts2)
context = {'user': user, 'context1': context1, 'context2': context2}
action, prob = get_action(vw, context, actions)
cost = cost_function(context, action)
cost_sum += cost
if do_learn:
vw_format = vw.parse(to_vw_example_format(context, actions, (action, cost, prob)),pyvw.vw.lContextualBandit)
vw.learn(vw_format)
ctr.append(-1*cost_sum/i)
start_counter = end_counter
end_counter = start_counter + num_iterations
return ctr
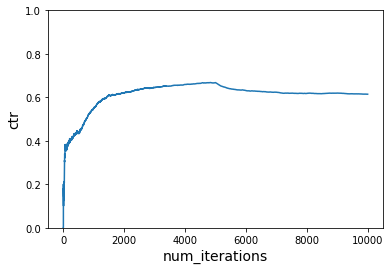
# use first reward function initially and then switch to second reward function
# Instantiate learner in VW
vw = pyvw.vw("--cb_explore_adf -q UA --quiet --epsilon 0.2")
num_iterations_per_cost_func = 5000
cost_functions = [get_cost, get_cost_new1]
total_iterations = num_iterations_per_cost_func * len(cost_functions)
ctr = run_simulation_multiple_cost_functions(vw, num_iterations_per_cost_func, users, context1, context2, items, cost_functions)
plot_ctr(total_iterations, ctr)
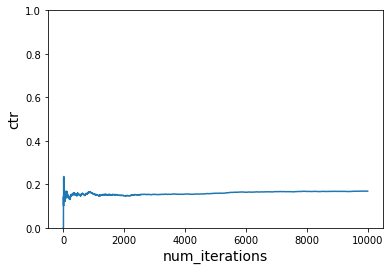
# Do not learn
# use first reward function initially and then switch to second reward function
# Instantiate learner in VW
vw = pyvw.vw("--cb_explore_adf -q UA --quiet --epsilon 0.2")
num_iterations_per_cost_func = 5000
cost_functions = [get_cost, get_cost_new1]
total_iterations = num_iterations_per_cost_func * len(cost_functions)
ctr = run_simulation_multiple_cost_functions(vw, num_iterations_per_cost_func, users, context1, context2, items, cost_functions, do_learn=False)
plot_ctr(total_iterations, ctr)
mapping_users = {
'Alex':'usera',
'Ben':'userb',
'Cindy': 'userc'
}
mapping_context1 = {
'Morning':'ctx11',
'Evening':'ctx12',
}
mapping_context2 = {
'Summer':'ctx21',
'Winter':'ctx22'
}
mapping_items = {
'Politics':'item1',
'Economics':'item2',
'Technology':'item3',
'Movies':'item4',
'Business':'item5',
'History':'item6'
}
users = list(mapping_users.values())
items = list(mapping_items.values())
context1 = list(mapping_context1.values())
context2 = list(mapping_context2.values())
context = pd.DataFrame(list(product(users, context1, context2, items)), columns=['users', 'context1', 'context2', 'items'])
context['reward'] = np.random.choice([0,1],len(context))
context['cost'] = context['reward']*-1
contextdf = context.copy()
contextdf
| users | context1 | context2 | items | reward | cost | |
|---|---|---|---|---|---|---|
| 0 | usera | ctx11 | ctx21 | item1 | 1 | -1 |
| 1 | usera | ctx11 | ctx21 | item2 | 1 | -1 |
| 2 | usera | ctx11 | ctx21 | item3 | 1 | -1 |
| 3 | usera | ctx11 | ctx21 | item4 | 0 | 0 |
| 4 | usera | ctx11 | ctx21 | item5 | 1 | -1 |
| ... | ... | ... | ... | ... | ... | ... |
| 67 | userc | ctx12 | ctx22 | item2 | 1 | -1 |
| 68 | userc | ctx12 | ctx22 | item3 | 0 | 0 |
| 69 | userc | ctx12 | ctx22 | item4 | 1 | -1 |
| 70 | userc | ctx12 | ctx22 | item5 | 1 | -1 |
| 71 | userc | ctx12 | ctx22 | item6 | 0 | 0 |
72 rows × 6 columns
# This function modifies (context, action, cost, probability) to VW friendly format
def to_vw_example_format(context, actions, cb_label=None):
if cb_label is not None:
chosen_action, cost, prob = cb_label
example_string = ""
example_string += "shared |User users={} context1={} context2={}\n".format(context["user"], context["context1"], context["context2"])
for action in actions:
if cb_label is not None and action == chosen_action:
example_string += "0:{}:{} ".format(cost, prob)
example_string += "|Action items={} \n".format(action)
#Strip the last newline
return example_string[:-1]
def sample_custom_pmf(pmf):
total = sum(pmf)
scale = 1 / total
pmf = [x * scale for x in pmf]
draw = random.random()
sum_prob = 0.0
for index, prob in enumerate(pmf):
sum_prob += prob
if(sum_prob > draw):
return index, prob
def get_action(vw, context, actions):
vw_text_example = to_vw_example_format(context, actions)
pmf = vw.predict(vw_text_example)
chosen_action_index, prob = sample_custom_pmf(pmf)
return actions[chosen_action_index], prob
def choose_user(users):
return random.choice(users)
def choose_context1(context1):
return random.choice(context1)
def choose_context2(context2):
return random.choice(context2)
class VWCSimulation():
def __init__(self, vw, ictxt, n=100000):
self.vw = vw
self.users = ictxt['users'].unique().tolist()
self.contexts1 = ictxt['context1'].unique().tolist()
self.contexts2 = ictxt['context2'].unique().tolist()
self.actions = ictxt['items'].unique().tolist()
self.contextdf = ictxt.copy()
self.contextdf['cost'] = self.contextdf['reward']*-1
def get_cost(self, context, action):
return self.contextdf.loc[(self.contextdf['users']==context['user']) & \
(self.contextdf.context1==context['context1']) & \
(self.contextdf.context2==context['context2']) & \
(self.contextdf['items']==action), \
'cost'].values[0]
def update_context(self, new_ctxt):
self.contextdf = new_ctxt.copy()
self.contextdf['cost'] = self.contextdf['reward']*-1
def step(self):
user = choose_user(self.users)
context1 = choose_context1(self.contexts1)
context2 = choose_context2(self.contexts2)
context = {'user': user, 'context1': context1, 'context2': context2}
action, prob = get_action(self.vw, context, self.actions)
cost = self.get_cost(context, action)
vw_format = self.vw.parse(to_vw_example_format(context, self.actions, (action, cost, prob)), pyvw.vw.lContextualBandit)
self.vw.learn(vw_format)
self.vw.finish_example(vw_format)
return (context['user'], context['context1'], context['context2'], action, cost, prob)
context = pd.DataFrame(list(product(users, context1, context2, items)), columns=['users', 'context1', 'context2', 'items'])
context['reward'] = np.random.choice([0,1],len(context),p=[0.8,0.2])
contextdf = context.copy()
contextdf.reward.value_counts()
0 56
1 16
Name: reward, dtype: int64
vw = pyvw.vw("--cb_explore_adf -q UA --quiet --epsilon 0.2")
vws = VWCSimulation(vw, contextdf)
vws.step()
('usera', 'ctx12', 'ctx22', 'item2', 0, 0.16666666666666666)
_temp = []
for i in range(5000):
_temp.append(vws.step())
x = pd.DataFrame.from_records(_temp, columns=['user','context1','context2','item','cost','prob'])
xx = x.copy()
xx['ccost'] = xx['cost'].cumsum()
xx = xx.fillna(0)
xx = xx.rename_axis('iter').reset_index()
xx['ctr'] = -1*xx['ccost']/xx['iter']
xx.sample(10)
| iter | user | context1 | context2 | item | cost | prob | ccost | ctr | |
|---|---|---|---|---|---|---|---|---|---|
| 1352 | 1352 | usera | ctx11 | ctx21 | item6 | 0 | 0.033333 | -772 | 0.571006 |
| 2530 | 2530 | usera | ctx12 | ctx22 | item1 | -1 | 0.833333 | -1507 | 0.595652 |
| 581 | 581 | userc | ctx11 | ctx22 | item3 | -1 | 0.833333 | -283 | 0.487091 |
| 4116 | 4116 | userb | ctx12 | ctx22 | item5 | -1 | 0.833333 | -2585 | 0.628037 |
| 2425 | 2425 | userb | ctx11 | ctx21 | item6 | -1 | 0.833333 | -1432 | 0.590515 |
| 3175 | 3175 | usera | ctx12 | ctx21 | item3 | -1 | 0.833333 | -1950 | 0.614173 |
| 1654 | 1654 | usera | ctx11 | ctx22 | item3 | 0 | 0.833333 | -968 | 0.585248 |
| 4755 | 4755 | userc | ctx11 | ctx21 | item6 | 0 | 0.033333 | -3018 | 0.634700 |
| 1857 | 1857 | userb | ctx11 | ctx21 | item6 | -1 | 0.833333 | -1093 | 0.588584 |
| 3771 | 3771 | userb | ctx12 | ctx22 | item1 | -1 | 0.833333 | -2367 | 0.627685 |
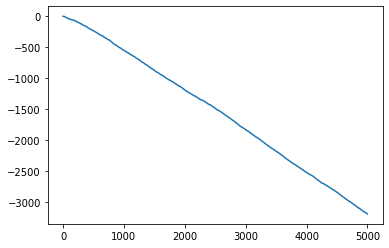
xx['ccost'].plot()
<matplotlib.axes._subplots.AxesSubplot at 0x7f31db251f50>
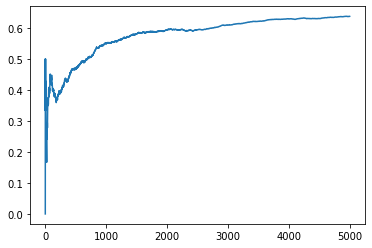
xx['ctr'].plot()
<matplotlib.axes._subplots.AxesSubplot at 0x7f31db1cfb90>
tempdf1 = xx.copy()
context = pd.DataFrame(list(product(users, context1, context2, items)), columns=['users', 'context1', 'context2', 'items'])
context['reward'] = 0
X = context.copy()
X.loc[(X['users']=='usera')&(X['items']=='item1'),'reward']=1
X.loc[(X['users']=='userb')&(X['items']=='item2'),'reward']=1
X.loc[(X['users']=='userc')&(X['items']=='item3'),'reward']=1
X.reward.value_counts()
vws.update_context(X)
_temp = []
for i in range(5000):
_temp.append(vws.step())
x = pd.DataFrame.from_records(_temp, columns=['user','context1','context2','item','cost','prob'])
xx = x.copy()
xx['ccost'] = xx['cost'].cumsum()
xx = xx.fillna(0)
xx = xx.rename_axis('iter').reset_index()
xx['ctr'] = -1*xx['ccost']/xx['iter']
xx.sample(10)
| iter | user | context1 | context2 | item | cost | prob | ccost | ctr | |
|---|---|---|---|---|---|---|---|---|---|
| 4316 | 4316 | userc | ctx11 | ctx21 | item2 | 0 | 0.033333 | -3412 | 0.790547 |
| 4798 | 4798 | userc | ctx12 | ctx22 | item3 | -1 | 0.833333 | -3827 | 0.797624 |
| 4154 | 4154 | userb | ctx11 | ctx22 | item2 | -1 | 0.833333 | -3284 | 0.790563 |
| 4720 | 4720 | userc | ctx11 | ctx22 | item3 | -1 | 0.833333 | -3757 | 0.795975 |
| 4362 | 4362 | userc | ctx12 | ctx21 | item3 | -1 | 0.833333 | -3448 | 0.790463 |
| 3520 | 3520 | usera | ctx12 | ctx21 | item1 | -1 | 0.833333 | -2759 | 0.783807 |
| 2614 | 2614 | userc | ctx11 | ctx21 | item3 | -1 | 0.833333 | -2025 | 0.774675 |
| 4840 | 4840 | userb | ctx12 | ctx21 | item2 | -1 | 0.833333 | -3863 | 0.798140 |
| 3084 | 3084 | userc | ctx12 | ctx21 | item3 | -1 | 0.833333 | -2414 | 0.782750 |
| 4921 | 4921 | usera | ctx11 | ctx22 | item4 | 0 | 0.033333 | -3932 | 0.799025 |
tempdf2 = tempdf1.append(xx, ignore_index=True)
tempdf2.sample(10)
| iter | user | context1 | context2 | item | cost | prob | ccost | ctr | |
|---|---|---|---|---|---|---|---|---|---|
| 974 | 974 | usera | ctx11 | ctx21 | item1 | 0 | 0.033333 | -534 | 0.548255 |
| 5527 | 527 | userc | ctx11 | ctx22 | item3 | -1 | 0.833333 | -292 | 0.554080 |
| 9055 | 4055 | userb | ctx11 | ctx21 | item2 | -1 | 0.833333 | -3199 | 0.788903 |
| 3984 | 3984 | usera | ctx11 | ctx21 | item3 | -1 | 0.833333 | -2508 | 0.629518 |
| 2327 | 2327 | userc | ctx11 | ctx21 | item3 | 0 | 0.833333 | -1375 | 0.590890 |
| 6606 | 1606 | usera | ctx12 | ctx22 | item5 | 0 | 0.033333 | -1182 | 0.735990 |
| 7398 | 2398 | userb | ctx11 | ctx22 | item2 | -1 | 0.833333 | -1852 | 0.772310 |
| 9051 | 4051 | userb | ctx12 | ctx22 | item2 | -1 | 0.833333 | -3195 | 0.788694 |
| 7105 | 2105 | userb | ctx11 | ctx21 | item2 | -1 | 0.833333 | -1603 | 0.761520 |
| 1866 | 1866 | usera | ctx12 | ctx22 | item1 | -1 | 0.833333 | -1099 | 0.588960 |
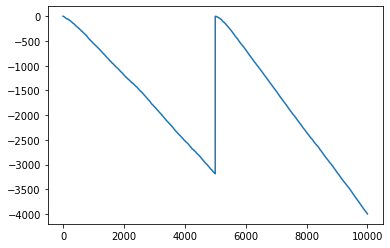
tempdf2['ccost'].plot()
<matplotlib.axes._subplots.AxesSubplot at 0x7f31db191050>
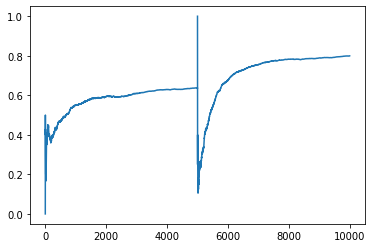
tempdf2['ctr'].plot()
<matplotlib.axes._subplots.AxesSubplot at 0x7f31e9365790>
Contextual bandit dash app¶
Building a dash app of contextual bandit based recommender system
The objective of this app is to apply the contextual bandit algorithms to recommendation problem under a simulated environment. The recommender agent is able to quickly adapt the changing behavior of users and change the recommendation strategy accordingly.
There are 3 users: Alex, Ben and Cindy. There are 6 news topics and 2 types of context. That means, Alex, Ben, and Cindy might prefer to read news reated to any of the 6 topics on morning/evening and weekday/weekends. Eg. Alex might prefer business related news on weekday mornings and entertainment related news on weekend evenings. And it is also possible that in future, Alex starts reading politics on weekday mornings. These situations reflect the real-world scenarios and the job of our contextual agent is to automatically detect these preferences and changes and recommend the items accordingly to maximize the reward like user satisfaction.
https://www.youtube.com/watch?v=9t0-FZIWMRQ
In the example, agent initialized with random preferences and starts recommending news to the users. We added 2 context: “Cindy prefers economy news on weekday mornings” and “Ben prefers weather news on weekday mornings” and starts rewarding agent for correctly recommending as per these preferences. At the moment, agent knows that Ben prefers business news and Cindy prefers history news. With time, agent started recommending weather news to Ben. Similar case we will see for Cindy and in fact, for all users.
Note: Interval is 1 sec but we are not seeing updates every second because we are looking at a particular context only: Weekday mornings but agent is recommending globally.
It is important to note that agent do not know the ground truth. It just taking action and receiving reward and the objective is to estimate this ground truth preferences.
!pip install -q dash dash-html-components dash-core-components dash_bootstrap_components jupyter-dash
!mkdir -p assets
!wget -q --show-progress -O assets/image.jpg https://moodle.com/wp-content/uploads/2020/04/Moodle_General_news.png
assets/image.jpg 0%[ ] 0 --.-KB/s
assets/image.jpg 100%[===================>] 26.00K --.-KB/s in 0s
import dash
from dash import dcc
import dash_html_components as html
import dash_bootstrap_components as dbc
from dash.dependencies import Input, Output, State
from jupyter_dash import JupyterDash
import plotly.graph_objs as go
import plotly.express as px
from vowpalwabbit import pyvw
import numpy as np
import pandas as pd
import itertools
import pathlib
from copy import deepcopy
from itertools import product
import scipy
import scipy.stats as stats
import random
# This function modifies (context, action, cost, probability) to VW friendly format
def to_vw_example_format(context, actions, cb_label=None):
if cb_label is not None:
chosen_action, cost, prob = cb_label
example_string = ""
example_string += "shared |User users={} context1={} context2={}\n".format(context["user"], context["context1"], context["context2"])
for action in actions:
if cb_label is not None and action == chosen_action:
example_string += "0:{}:{} ".format(cost, prob)
example_string += "|Action items={} \n".format(action)
#Strip the last newline
return example_string[:-1]
def sample_custom_pmf(pmf):
total = sum(pmf)
scale = 1 / total
pmf = [x * scale for x in pmf]
draw = random.random()
sum_prob = 0.0
for index, prob in enumerate(pmf):
sum_prob += prob
if(sum_prob > draw):
return index, prob
def get_action(vw, context, actions):
vw_text_example = to_vw_example_format(context, actions)
pmf = vw.predict(vw_text_example)
chosen_action_index, prob = sample_custom_pmf(pmf)
return actions[chosen_action_index], prob
def choose_user(users):
return random.choice(users)
def choose_context1(context1):
return random.choice(context1)
def choose_context2(context2):
return random.choice(context2)
class VWCSimulation():
def __init__(self, vw, ictxt):
self.vw = vw
self.users = ictxt['users'].unique().tolist()
self.contexts1 = ictxt['context1'].unique().tolist()
self.contexts2 = ictxt['context2'].unique().tolist()
self.actions = ictxt['items'].unique().tolist()
self.contextdf = ictxt.copy()
self.contextdf['cost'] = self.contextdf['reward']*-1
def get_cost(self, context, action):
return self.contextdf.loc[(self.contextdf['users']==context['user']) & \
(self.contextdf.context1==context['context1']) & \
(self.contextdf.context2==context['context2']) & \
(self.contextdf['items']==action), \
'cost'].values[0]
def update_context(self, new_ctxt):
self.contextdf = new_ctxt.copy()
self.contextdf['cost'] = self.contextdf['reward']*-1
def step(self):
user = choose_user(self.users)
context1 = choose_context1(self.contexts1)
context2 = choose_context2(self.contexts2)
context = {'user': user, 'context1': context1, 'context2': context2}
action, prob = get_action(self.vw, context, self.actions)
cost = self.get_cost(context, action)
vw_format = self.vw.parse(to_vw_example_format(context, self.actions, (action, cost, prob)), pyvw.vw.lContextualBandit)
self.vw.learn(vw_format)
self.vw.finish_example(vw_format)
return (context['user'], context['context1'], context['context2'], action, cost, prob)
app = JupyterDash(__name__, external_stylesheets = [dbc.themes.BOOTSTRAP])
def generate_input_cards(preference='Random'):
card_content = [
dbc.CardImg(src="assets/image.jpg", top=True),
dbc.CardBody([html.P(preference, className="card-title")])
]
card = dbc.Card(card_content, color="primary", outline=True)
return dbc.Col([card], width={"size": 2})
pref_grid = []
mapping_users = {
'Alex':'usera',
'Ben':'userb',
'Cindy': 'userc'
}
mapping_context1 = {
'Morning':'ctx11',
'Evening':'ctx12',
}
mapping_context2 = {
'Weekday':'ctx21',
'Weekend':'ctx22'
}
mapping_items = {
'Politics':'item1',
'Economics':'item2',
'Technology':'item3',
'Weather':'item4',
'Business':'item5',
'History':'item6'
}
mapping_users_reverse = {v:k for k,v in mapping_users.items()}
mapping_context1_reverse = {v:k for k,v in mapping_context1.items()}
mapping_context2_reverse = {v:k for k,v in mapping_context2.items()}
mapping_items_reverse = {v:k for k,v in mapping_items.items()}
users = list(mapping_users.values())
items = list(mapping_items.values())
context1 = list(mapping_context1.values())
context2 = list(mapping_context2.values())
context = pd.DataFrame(list(product(users, context1, context2, items)),
columns=['users', 'context1', 'context2', 'items'])
context['reward'] = np.random.choice([0,1],len(context),p=[0.8,0.2])
vw = pyvw.vw("--cb_explore_adf -q UA --quiet --epsilon 0.2")
vws = VWCSimulation(vw, context)
last_update = vws.step()
contextdf = context.copy()
countDF = contextdf.copy()
countDF['prob'] = 0
def generate_input_boxes():
dropdown_users = dcc.Dropdown(
id='ddown_users',
options=[{"label":k, "value":v} for k,v in mapping_users.items()],
clearable=False,
value="usera",
className="m-1",
)
dropdown_context1 = dcc.Dropdown(
id='ddown_ctx1',
options=[{"label":k, "value":v} for k,v in mapping_context1.items()],
clearable=False,
value="ctx11",
className="m-1",
)
dropdown_context2 = dcc.Dropdown(
id='ddown_ctx2',
options=[{"label":k, "value":v} for k,v in mapping_context2.items()],
clearable=False,
value="ctx21",
className="m-1",
)
dropdown_items = dcc.Dropdown(
id='ddown_items',
options=[{"label":k, "value":v} for k,v in mapping_items.items()],
clearable=False,
value="item1",
className="m-1",
)
return html.Div(
[
dropdown_users,
dropdown_context1,
dropdown_context2,
dropdown_items,
],
style={"display": "flex", "flex-direction": "column"},
)
def generate_context_boxes():
dropdown_outcontext1 = dcc.Dropdown(
id='ddown_outctx1',
options=[{"label":k, "value":v} for k,v in mapping_context1.items()],
clearable=False,
value="ctx11",
className="m-1",
)
dropdown_outcontext2 = dcc.Dropdown(
id='ddown_outctx2',
options=[{"label":k, "value":v} for k,v in mapping_context2.items()],
clearable=False,
value="ctx21",
className="m-1",
)
return html.Div(
[
dropdown_outcontext1,
dropdown_outcontext2
],
style={"display": "flex", "flex-direction": "column"},
)
app.layout = html.Div([
generate_input_boxes(),
dbc.Button("Register your Preference", color="primary", className="m-1",
id='pref-button'),
html.Div(id='pref-grid'),
dbc.Button("Clear the context", color="secondary",
className="m-1", id='clr-button'),
dbc.Button("Start rewarding Agent for these Preferences", color="success",
className="m-1", id='updt-button'),
generate_context_boxes(),
dcc.Interval(
id='interval-component',
interval=100, # in milliseconds
n_intervals=0),
html.Div(id='placeholder'),
html.Div(id='placeholder2'),
])
@app.callback(
Output("pref-grid", "children"),
Input("pref-button", "n_clicks"),
Input("clr-button", "n_clicks"),
State('ddown_users', 'value'),
State('ddown_items', 'value'),
State('ddown_ctx1', 'value'),
State('ddown_ctx2', 'value'),
)
def update_pref_grid(nclick_pref, nclick_clr, pref_user, pref_item, pref_ctx1, pref_ctx2):
global pref_grid
changed_id = [p['prop_id'] for p in dash.callback_context.triggered][0]
if "pref-button" in changed_id:
global contextdf
card_text = '{} prefers {} related news in {} {}s'.format(mapping_users_reverse[pref_user],
mapping_items_reverse[pref_item],
mapping_context2_reverse[pref_ctx2],
mapping_context1_reverse[pref_ctx1])
contextdf.loc[(contextdf.users==pref_user) & \
(contextdf.context1==pref_ctx1) & \
(contextdf.context2==pref_ctx2), \
'reward'] = 0
contextdf.loc[(contextdf.users==pref_user) & \
(contextdf.context1==pref_ctx1) & \
(contextdf.context2==pref_ctx2) & \
(contextdf['items']==pref_item), \
'reward'] = 1
pref_grid.append(generate_input_cards(card_text))
return dbc.Row(children=pref_grid,
style={'max-width': '100%',
'display': 'flex',
'align-items': 'center',
'padding': '2rem 5rem',
'overflow': 'auto',
'height': 'fit-content',
'flex-direction': 'row',
})
elif "clr-button" in changed_id:
pref_grid = []
return dbc.Row(children=pref_grid)
@app.callback(
Output("placeholder2", "children"),
Input("updt-button", "n_clicks")
)
def update_context(nclick):
if nclick:
global vws
global contextdf
vws.update_context(contextdf)
return ''
@app.callback(
Output("placeholder", "children"),
Input('interval-component', 'n_intervals'),
Input('ddown_outctx1', 'value'),
Input('ddown_outctx2', 'value'),
)
def update_metrics(n, octx1, octx2):
global countDF
countDF = countDF.append(pd.Series(vws.step(),countDF.columns),ignore_index=True)
_x = countDF.copy()
_x = _x[(_x.context1==octx1) & (_x.context2==octx2)]
_x['reward']*=-1
pv = pd.pivot_table(_x, index=['users'], columns=["items"], values=['reward'], aggfunc=sum, fill_value=0)
pv.index = [mapping_users_reverse[x] for x in pv.index]
pv.columns = pv.columns.droplevel(0)
pv = pv.rename_axis('User').reset_index().rename_axis(None, axis=1).set_index('User').T.reset_index()
pv['index'] = pv['index'].map(mapping_items_reverse)
pv = pv.rename(columns={"index": "Preferences"})
out = html.Div([
dbc.Table.from_dataframe(pv, striped=True, bordered=True, hover=True, responsive=True)
])
return out
app.run_server(mode='inline', port=8081)
# !kill -9 $(lsof -t -i:8081) # command to kill the dash once done