Off-Policy Learning in Two-stage Recommender Systems¶
Many real-world recommender systems need to be highly scalable: matching millions of items with billions of users, with milliseconds latency. The scalability requirement has led to widely used two-stage recommender systems, consisting of efficient candidate generation model(s) in the first stage and a more powerful ranking model in the second stage.
Logged user feedback, e.g., user clicks or dwell time, are often used to build both candidate generation and ranking models for recommender systems. While it’s easy to collect large amount of such data, they are inherently biased because the feedback can only be observed on items recommended by the previous systems. Recently, off-policy correction on such biases have attracted increasing interest in the field of recommender system research. However, most existing work either assumed that the recommender system is a single-stage system or only studied how to apply off-policy correction to the candidate generation stage of the system without explicitly considering the interactions between the two stages.
In this work, we propose a two-stage off-policy policy gradient method, and showcase that ignoring the interaction between the two stages leads to a sub-optimal policy in two-stage recommender systems. The proposed method explicitly takes into account the ranking model when training the candidate generation model, which helps improve the performance of the whole system. We conduct experiments on real-world datasets with large item space and demonstrate the effectiveness of our proposed method.
Pseudo code¶

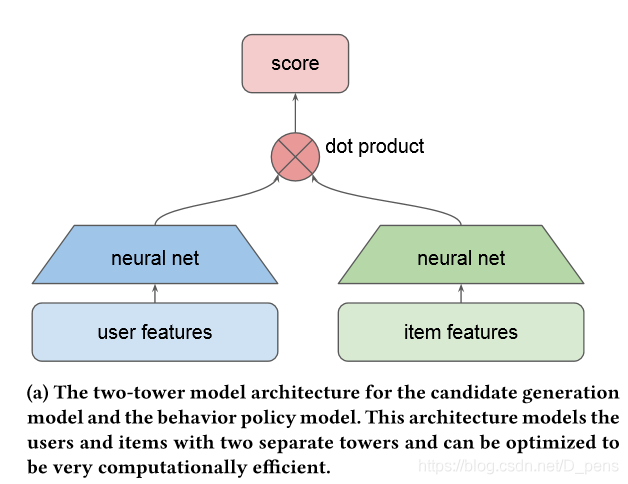
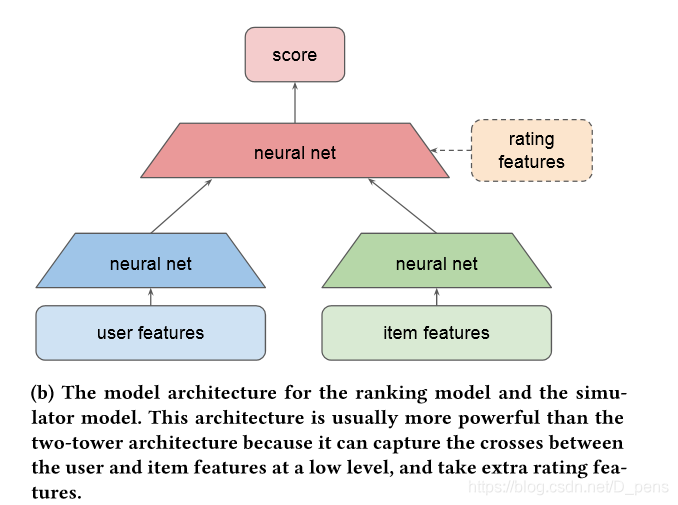
Training model¶
The simulation model - divides MovieLens-1M into training set, validation set and test set at 3:1:1.
Behavior strategy model and ranking model - Use 10,000 user-item pairs randomly generated by the simulation model to train the behavior strategy model, and then obtain a bandit data set by sampling the top-5 items of each user predicted by the behavior strategy model. Train the ranking model based on this data set, divide 2000 users as the verification set, and 4000 users as the test set.
Candidate generation model - Set the optimizer to AdaGrad, the initial learning rate is 0.05, and the weight limit parameters of 1-IPS and 2-IPS are set c1 = 10, c2 = 0.01 c_1 = 10, c_2=0.01. For each training method, we trained 20 candidate generation models initialized with different random seeds. The early stopping method is applied in both one-stage evaluation and two-stage evaluation.
Imports¶
import os
import numpy as np
import pandas as pd
import torch
from torch.utils.data import Dataset
from tqdm import tqdm
import torch.nn as nn
import torch.nn.functional as F
from collections import OrderedDict
Model¶
NUM_ITEMS = 3883
NUM_YEARS = 81
NUM_GENRES = 18
NUM_USERS = 6040
NUM_OCCUPS = 21
NUM_AGES = 7
NUM_ZIPS = 3439
class ItemRep(nn.Module):
"""Item representation layer."""
def __init__(self, item_emb_size=10, year_emb_size=5, genre_hidden=5):
super(ItemRep, self).__init__()
self.item_embedding = nn.Embedding(
NUM_ITEMS + 1, item_emb_size, padding_idx=0)
self.year_embedding = nn.Embedding(NUM_YEARS, year_emb_size)
self.genre_linear = nn.Linear(NUM_GENRES, genre_hidden)
self.rep_dim = item_emb_size + year_emb_size + genre_hidden
def forward(self, categorical_feats, real_feats):
out = torch.cat(
[
self.item_embedding(categorical_feats[:, 0]),
self.year_embedding(categorical_feats[:, 1]),
self.genre_linear(real_feats)
],
dim=1)
return out
class UserRep(nn.Module):
"""User representation layer."""
def __init__(self, user_emb_size=10, feature_emb_size=5):
super(UserRep, self).__init__()
self.user_embedding = nn.Embedding(
NUM_USERS + 1, user_emb_size, padding_idx=0)
self.gender_embedding = nn.Embedding(2, feature_emb_size)
self.age_embedding = nn.Embedding(NUM_AGES, feature_emb_size)
self.occup_embedding = nn.Embedding(NUM_OCCUPS, feature_emb_size)
self.zip_embedding = nn.Embedding(NUM_ZIPS, feature_emb_size)
self.rep_dim = user_emb_size + feature_emb_size * 4
def forward(self, categorical_feats, real_feats=None):
reps = [
self.user_embedding(categorical_feats[:, 0]),
self.gender_embedding(categorical_feats[:, 1]),
self.age_embedding(categorical_feats[:, 2]),
self.occup_embedding(categorical_feats[:, 3]),
self.zip_embedding(categorical_feats[:, 4])
]
out = torch.cat(reps, dim=1)
return out
class ImpressionSimulator(nn.Module):
"""Simulator model that predicts the outcome of impression."""
def __init__(self, hidden=100, use_impression_feats=False):
super(ImpressionSimulator, self).__init__()
self.user_rep = UserRep()
self.item_rep = ItemRep()
self.use_impression_feats = use_impression_feats
input_dim = self.user_rep.rep_dim + self.item_rep.rep_dim
if use_impression_feats:
input_dim += 1
self.linear = nn.Sequential(
nn.Linear(input_dim, hidden),
nn.ReLU(), nn.Linear(hidden, 50), nn.ReLU(), nn.Linear(50, 1))
def forward(self, user_feats, item_feats, impression_feats=None):
users = self.user_rep(**user_feats)
items = self.item_rep(**item_feats)
inputs = torch.cat([users, items], dim=1)
if self.use_impression_feats:
inputs = torch.cat([inputs, impression_feats["real_feats"]], dim=1)
return self.linear(inputs).squeeze()
class Nominator(nn.Module):
"""Two tower nominator model."""
def __init__(self):
super(Nominator, self).__init__()
self.item_rep = ItemRep()
self.user_rep = UserRep()
self.linear = nn.Linear(self.user_rep.rep_dim, self.item_rep.rep_dim)
self.binary = True
def forward(self, user_feats, item_feats):
users = self.linear(F.relu(self.user_rep(**user_feats)))
users = torch.unsqueeze(users, 2) # (b, h) -> (b, h, 1)
items = self.item_rep(**item_feats)
if self.binary:
items = torch.unsqueeze(items, 1) # (b, h) -> (b, 1, h)
else:
items = torch.unsqueeze(items, 0).expand(users.size(0), -1,
-1) # (c, h) -> (b, c, h)
logits = torch.bmm(items, users).squeeze()
return logits
def set_binary(self, binary=True):
self.binary = binary
class Ranker(nn.Module):
"""Ranker model."""
def __init__(self):
super(Ranker, self).__init__()
self.item_rep = ItemRep()
self.user_rep = UserRep()
self.linear = nn.Linear(self.user_rep.rep_dim + 1,
self.item_rep.rep_dim)
self.binary = True
def forward(self, user_feats, item_feats, impression_feats):
users = self.user_rep(**user_feats)
context_users = torch.cat(
[users, impression_feats["real_feats"]], dim=1)
context_users = self.linear(context_users)
context_users = torch.unsqueeze(context_users,
2) # (b, h) -> (b, h, 1)
items = self.item_rep(**item_feats)
if self.binary:
items = torch.unsqueeze(items, 1) # (b, h) -> (b, 1, h)
else:
items = torch.unsqueeze(items, 0).expand(
users.size(0), -1, -1) # (c, h) -> (b, c, h), c=#items
logits = torch.bmm(items, context_users).squeeze()
return logits
def set_binary(self, binary=True):
self.binary = binary
Download data¶
!wget -q --show-progress https://files.grouplens.org/datasets/movielens/ml-1m.zip
!unzip ml-1m.zip
ml-1m.zip 100%[===================>] 5.64M 32.7MB/s in 0.2s
Archive: ml-1m.zip
creating: ml-1m/
inflating: ml-1m/movies.dat
inflating: ml-1m/ratings.dat
inflating: ml-1m/README
inflating: ml-1m/users.dat
Dataset¶
Create a torch dataset class for ML-1M; convert the label into binary labels (positive if rating > 3).
class MovieLensDataset(Dataset):
def __init__(self, filepath, device="cuda:0"):
self.device = device
ratings, users, items = self.load_data(filepath)
self.user_feats = {}
self.item_feats = {}
self.impression_feats = {}
self.user_feats["categorical_feats"] = torch.LongTensor(
users.values).to(device)
self.item_feats["categorical_feats"] = torch.LongTensor(
items.values[:, :2]).to(device)
self.item_feats["real_feats"] = torch.FloatTensor(
items.values[:, 2:]).to(device)
self.impression_feats["user_ids"] = torch.LongTensor(
ratings.values[:, 0]).to(device)
self.impression_feats["item_ids"] = torch.LongTensor(
ratings.values[:, 1]).to(device)
self.impression_feats["real_feats"] = torch.FloatTensor(
ratings.values[:, 3]).view(-1, 1).to(device)
self.impression_feats["labels"] = torch.FloatTensor(
ratings.values[:, 2]).to(device)
def __len__(self):
return len(self.impression_feats["user_ids"])
def __getitem__(self, idx):
labels = self.impression_feats["labels"][idx]
feats = {}
feats["impression_feats"] = {}
feats["impression_feats"]["real_feats"] = self.impression_feats[
"real_feats"][idx]
user_id = self.impression_feats["user_ids"][idx]
item_id = self.impression_feats["item_ids"][idx]
feats["user_feats"] = {
key: value[user_id - 1]
for key, value in self.user_feats.items()
}
feats["item_feats"] = {
key: value[item_id - 1]
for key, value in self.item_feats.items()
}
return feats, labels
def load_data(self, filepath):
names = "UserID::MovieID::Rating::Timestamp".split("::")
ratings = pd.read_csv(
os.path.join(filepath, "ratings.dat"),
sep="::",
names=names,
engine="python")
ratings["Rating"] = (ratings["Rating"] > 3).astype(int)
ratings["Timestamp"] = (
ratings["Timestamp"] - ratings["Timestamp"].min()
) / float(ratings["Timestamp"].max() - ratings["Timestamp"].min())
names = "UserID::Gender::Age::Occupation::Zip-code".split("::")
users = pd.read_csv(
os.path.join(filepath, "users.dat"),
sep="::",
names=names,
engine="python")
for i in range(1, users.shape[1]):
users.iloc[:, i] = pd.factorize(users.iloc[:, i])[0]
names = "MovieID::Title::Genres".split("::")
Genres = [
"Action", "Adventure", "Animation", "Children's", "Comedy",
"Crime", "Documentary", "Drama", "Fantasy", "Film-Noir", "Horror",
"Musical", "Mystery", "Romance", "Sci-Fi", "Thriller", "War",
"Western"
]
movies = pd.read_csv(
os.path.join(filepath, "movies.dat"),
sep="::",
names=names,
engine="python")
movies["Year"] = movies["Title"].apply(lambda x: x[-5:-1])
for genre in Genres:
movies[genre] = movies["Genres"].apply(lambda x: genre in x)
movies.iloc[:, 3] = pd.factorize(movies.iloc[:, 3])[0]
movies.iloc[:, 4:] = movies.iloc[:, 4:].astype(float)
movies = movies.loc[:, ["MovieID", "Year"] + Genres]
movies.iloc[:, 2:] = movies.iloc[:, 2:].div(
movies.iloc[:, 2:].sum(axis=1), axis=0)
movie_id_map = {}
for i in range(movies.shape[0]):
movie_id_map[movies.loc[i, "MovieID"]] = i + 1
movies["MovieID"] = movies["MovieID"].apply(lambda x: movie_id_map[x])
ratings["MovieID"] = ratings["MovieID"].apply(
lambda x: movie_id_map[x])
self.NUM_ITEMS = len(movies.MovieID.unique())
self.NUM_YEARS = len(movies.Year.unique())
self.NUM_GENRES = movies.shape[1] - 2
self.NUM_USERS = len(users.UserID.unique())
self.NUM_OCCUPS = len(users.Occupation.unique())
self.NUM_AGES = len(users.Age.unique())
self.NUM_ZIPS = len(users["Zip-code"].unique())
return ratings, users, movies
class SyntheticMovieLensDataset(Dataset):
def __init__(self, filepath, simulator_path, synthetic_data_path, cut=0.764506,
device="cuda:0"):
self.device = device
self.cut = cut
self.simulator = None
ratings, users, items = self.load_data(filepath)
self.user_feats = {}
self.item_feats = {}
self.impression_feats = {}
self.user_feats["categorical_feats"] = torch.LongTensor(users.values)
self.item_feats["categorical_feats"] = torch.LongTensor(
items.values[:, :2])
self.item_feats["real_feats"] = torch.FloatTensor(items.values[:, 2:])
if os.path.exists(synthetic_data_path):
self.impression_feats = torch.load(synthetic_data_path)
self.impression_feats["labels"] = (
self.impression_feats["label_probs"] >= cut).to(
dtype=torch.float32)
print("loaded full_impression_feats.pt")
else:
print("generating impression_feats")
self.simulator = ImpressionSimulator(use_impression_feats=True)
self.simulator.load_state_dict(torch.load(simulator_path))
self.simulator = self.simulator.to(device)
impressions = self.get_full_impressions(ratings)
self.impression_feats["user_ids"] = torch.LongTensor(
impressions[:, 0])
self.impression_feats["item_ids"] = torch.LongTensor(
impressions[:, 1])
self.impression_feats["real_feats"] = torch.FloatTensor(
impressions[:, 2]).view(-1, 1)
self.impression_feats["labels"] = torch.zeros_like(
self.impression_feats["real_feats"])
self.impression_feats["label_probs"] = self.generate_labels()
self.impression_feats["labels"] = (
self.impression_feats["label_probs"] >= cut).to(
dtype=torch.float32)
torch.save(self.impression_feats, synthetic_data_path)
print("saved impression_feats")
def __len__(self):
return len(self.impression_feats["user_ids"])
def __getitem__(self, idx):
labels = self.impression_feats["labels"][idx]
feats = {}
feats["impression_feats"] = {}
feats["impression_feats"]["real_feats"] = self.impression_feats[
"real_feats"][idx]
user_id = self.impression_feats["user_ids"][idx]
item_id = self.impression_feats["item_ids"][idx]
feats["user_feats"] = {
key: value[user_id - 1]
for key, value in self.user_feats.items()
}
feats["item_feats"] = {
key: value[item_id - 1]
for key, value in self.item_feats.items()
}
return feats, labels
def load_data(self, filepath):
names = "UserID::MovieID::Rating::Timestamp".split("::")
ratings = pd.read_csv(
os.path.join(filepath, "ratings.dat"),
sep="::",
names=names,
engine="python")
ratings["Rating"] = (ratings["Rating"] > 3).astype(int)
ratings["Timestamp"] = (
ratings["Timestamp"] - ratings["Timestamp"].min()
) / float(ratings["Timestamp"].max() - ratings["Timestamp"].min())
names = "UserID::Gender::Age::Occupation::Zip-code".split("::")
users = pd.read_csv(
os.path.join(filepath, "users.dat"),
sep="::",
names=names,
engine="python")
for i in range(1, users.shape[1]):
users.iloc[:, i] = pd.factorize(users.iloc[:, i])[0]
names = "MovieID::Title::Genres".split("::")
Genres = [
"Action", "Adventure", "Animation", "Children's", "Comedy",
"Crime", "Documentary", "Drama", "Fantasy", "Film-Noir", "Horror",
"Musical", "Mystery", "Romance", "Sci-Fi", "Thriller", "War",
"Western"
]
movies = pd.read_csv(
os.path.join(filepath, "movies.dat"),
sep="::",
names=names,
engine="python")
movies["Year"] = movies["Title"].apply(lambda x: x[-5:-1])
for genre in Genres:
movies[genre] = movies["Genres"].apply(lambda x: genre in x)
movies.iloc[:, 3] = pd.factorize(movies.iloc[:, 3])[0]
movies.iloc[:, 4:] = movies.iloc[:, 4:].astype(float)
movies = movies.loc[:, ["MovieID", "Year"] + Genres]
movies.iloc[:, 2:] = movies.iloc[:, 2:].div(
movies.iloc[:, 2:].sum(axis=1), axis=0)
movie_id_map = {}
for i in range(movies.shape[0]):
movie_id_map[movies.loc[i, "MovieID"]] = i + 1
movies["MovieID"] = movies["MovieID"].apply(lambda x: movie_id_map[x])
ratings["MovieID"] = ratings["MovieID"].apply(
lambda x: movie_id_map[x])
self.NUM_ITEMS = len(movies.MovieID.unique())
self.NUM_YEARS = len(movies.Year.unique())
self.NUM_GENRES = movies.shape[1] - 2
self.NUM_USERS = len(users.UserID.unique())
self.NUM_OCCUPS = len(users.Occupation.unique())
self.NUM_AGES = len(users.Age.unique())
self.NUM_ZIPS = len(users["Zip-code"].unique())
return ratings, users, movies
def get_full_impressions(self, ratings):
"""Gets NUM_USERS x NUM_ITEMS impression features by iterating the user and item ids.
The impression-level feature, i.e. the timestamp, is sampled from a normal distribution with
mean and std as the empirical mean and std of each user's recorded timestamps in the real data.
"""
timestamps = {}
for i in range(len(ratings)):
u_id = ratings.loc[i, "UserID"]
timestamps[u_id] = timestamps.get(u_id, [])
timestamps[u_id].append(ratings.loc[i, "Timestamp"])
rs = np.random.RandomState(0)
t_samples = []
for i in range(self.NUM_USERS):
u_id = i + 1
t_samples.append(
rs.normal(
loc=np.mean(timestamps[u_id]),
scale=np.std(timestamps[u_id]),
size=(self.NUM_ITEMS, )))
t_samples = np.array(t_samples)
impressions = []
for i in range(self.NUM_USERS):
for j in range(self.NUM_ITEMS):
impressions.append([i + 1, j + 1, t_samples[i, j]])
impressions = np.array(impressions)
return impressions
def to_device(self, data):
if isinstance(data, torch.Tensor):
return data.to(self.device)
if isinstance(data, dict):
transformed_data = {}
for key in data:
transformed_data[key] = self.to_device(data[key])
elif type(data) == list:
transformed_data = []
for x in data:
transformed_data.append(self.to_device(x))
else:
raise NotImplementedError(
"Type {} not supported.".format(type(data)))
return transformed_data
def generate_labels(self):
"""Generates the binary labels using the simulator on every user-item pair."""
with torch.no_grad():
self.simulator.eval()
preds = []
for i in tqdm(range(len(self.impression_feats["labels"]) // 500)):
feats, _ = self.__getitem__(
list(range(i * 500, (i + 1) * 500)))
feats = self.to_device(feats)
outputs = torch.sigmoid(self.simulator(**feats))
preds += list(outputs.squeeze().cpu().numpy())
if (i + 1) * 500 < len(self.impression_feats["labels"]):
feats, _ = self.__getitem__(
list(
range((i + 1) * 500,
len(self.impression_feats["labels"]))))
feats = self.to_device(feats)
outputs = torch.sigmoid(self.simulator(**feats))
preds += list(outputs.squeeze().cpu().numpy())
return torch.FloatTensor(np.array(preds))
Metrics¶
class BaseMetric(object):
def __init__(self, rel_threshold, k):
self.rel_threshold = rel_threshold
if np.isscalar(k):
k = np.array([k])
self.k = k
def __len__(self):
return len(self.k)
def __call__(self, *args, **kwargs):
raise NotImplementedError
def _compute(self, *args, **kwargs):
raise NotImplementedError
class PrecisionRecall(BaseMetric):
def __init__(self, rel_threshold=0, k=10):
super(PrecisionRecall, self).__init__(rel_threshold, k)
def __len__(self):
return 2 * len(self.k)
def __str__(self):
str_precision = [('Precision@%1.f' % x) for x in self.k]
str_recall = [('Recall@%1.f' % x) for x in self.k]
return (','.join(str_precision)) + ',' + (','.join(str_recall))
def __call__(self, targets, predictions):
precision, recall = zip(
*[self._compute(targets, predictions, x) for x in self.k])
result = np.concatenate((precision, recall), axis=0)
return result
def _compute(self, targets, predictions, k):
predictions = predictions[:k]
num_hit = len(set(predictions).intersection(set(targets)))
return float(num_hit) / len(predictions), float(num_hit) / len(targets)
class MeanAP(BaseMetric):
def __init__(self, rel_threshold=0, k=np.inf):
super(MeanAP, self).__init__(rel_threshold, k)
def __call__(self, targets, predictions):
result = [self._compute(targets, predictions, x) for x in self.k]
return np.array(result)
def __str__(self):
return ','.join([('MeanAP@%1.f' % x) for x in self.k])
def _compute(self, targets, predictions, k):
if len(predictions) > k:
predictions = predictions[:k]
score = 0.0
num_hits = 0.0
for i, p in enumerate(predictions):
if p in targets and p not in predictions[:i]:
num_hits += 1.0
score += num_hits / (i + 1.0)
if not list(targets):
return 0.0
return score / min(len(targets), k)
class NormalizedDCG(BaseMetric):
def __init__(self, rel_threshold=0, k=10):
super(NormalizedDCG, self).__init__(rel_threshold, k)
def __call__(self, targets, predictions):
result = [self._compute(targets, predictions, x) for x in self.k]
return np.array(result)
def __str__(self):
return ','.join([('NDCG@%1.f' % x) for x in self.k])
def _compute(self, targets, predictions, k):
k = min(len(targets), k)
if len(predictions) > k:
predictions = predictions[:k]
# compute idcg
idcg = np.sum(1 / np.log2(np.arange(2, k + 2)))
dcg = 0.0
for i, p in enumerate(predictions):
if p in targets:
dcg += 1 / np.log2(i + 2)
ndcg = dcg / idcg
return ndcg
all_metrics = [PrecisionRecall(k=[1, 5, 10]), NormalizedDCG(k=[5, 10, 20])]
class Evaluator(object):
"""Evaluator for both one-stage and two-stage evaluations."""
def __init__(self, u, a, simulator, syn):
self.u = u
self.a = a
self.simulator = simulator
self.syn = syn
self.target_rankings = self.get_target_rankings()
self.metrics = all_metrics
def get_target_rankings(self):
target_rankings = []
with torch.no_grad():
self.simulator.eval()
for i in range(NUM_USERS):
impression_ids = range(i * NUM_ITEMS, (i + 1) * NUM_ITEMS)
feats, _ = self.syn[impression_ids]
feats["impression_feats"]["real_feats"] = torch.mean(
feats["impression_feats"]["real_feats"],
dim=0,
keepdim=True).repeat([NUM_ITEMS, 1])
feats = self.syn.to_device(feats)
outputs = torch.sigmoid(self.simulator(**feats))
user_target_ranking = (outputs >
self.syn.cut).nonzero().view(-1)
target_rankings.append(user_target_ranking.cpu().numpy())
return target_rankings
def one_stage_ranking_eval(self, logits, user_list):
for i, user in enumerate(user_list):
user_rated_items = self.a[self.u == user]
logits[i, user_rated_items] = -np.inf
sort_idx = torch.argsort(logits, dim=1, descending=True).cpu().numpy()
# Init evaluation results.
total_metrics_len = 0
for metric in self.metrics:
total_metrics_len += len(metric)
total_val_metrics = np.zeros(
[len(user_list), total_metrics_len], dtype=np.float32)
valid_rows = []
for i, user in enumerate(user_list):
pred_ranking = sort_idx[i].tolist()
target_ranking = self.target_rankings[user]
if len(target_ranking) <= 0:
continue
metric_results = list()
for j, metric in enumerate(self.metrics):
result = metric(
targets=target_ranking, predictions=pred_ranking)
metric_results.append(result)
total_val_metrics[i, :] = np.concatenate(metric_results)
valid_rows.append(i)
# Average evaluation results by user.
total_val_metrics = total_val_metrics[valid_rows]
avg_val_metrics = (total_val_metrics.mean(axis=0)).tolist()
# Summary evaluation results into a dict.
ind, result = 0, OrderedDict()
for metric in self.metrics:
values = avg_val_metrics[ind:ind + len(metric)]
if len(values) <= 1:
result[str(metric)] = values
else:
for name, value in zip(str(metric).split(','), values):
result[name] = value
ind += len(metric)
return result
def two_stage_ranking_eval(self, logits, ranker, user_list, k=30):
sort_idx = torch.argsort(logits, dim=1, descending=True).cpu().numpy()
topk_item_ids = []
for i, user in enumerate(user_list):
topk_item_ids.append([])
for j in sort_idx[i]:
if j not in self.a[self.u == user]:
topk_item_ids[-1].append(j)
if len(topk_item_ids[-1]) == k:
break
time_feats = self.syn.to_device(
torch.mean(
self.syn.impression_feats["real_feats"].view(
NUM_USERS, NUM_ITEMS),
dim=1).view(-1, 1))
# Init evaluation results.
total_metrics_len = 0
for metric in self.metrics:
total_metrics_len += len(metric)
total_val_metrics = np.zeros(
[len(user_list), total_metrics_len], dtype=np.float32)
valid_rows = []
for i, user in enumerate(user_list):
user_feats = {
key: value[user].view(1, -1)
for key, value in self.syn.user_feats.items()
}
item_feats = {
key: value[topk_item_ids[i]]
for key, value in self.syn.item_feats.items()
}
user_feats = self.syn.to_device(user_feats)
item_feats = self.syn.to_device(item_feats)
impression_feats = {"real_feats": time_feats[user].view(1, -1)}
ranker_logits = ranker(user_feats, item_feats,
impression_feats).view(1, -1)
_, pred = ranker_logits.topk(k=k)
pred = pred[0].cpu().numpy()
pred_ranking = sort_idx[i][pred].tolist()
target_ranking = self.target_rankings[user]
if len(target_ranking) <= 0:
continue
metric_results = list()
for j, metric in enumerate(self.metrics):
result = metric(
targets=target_ranking, predictions=pred_ranking)
metric_results.append(result)
total_val_metrics[i, :] = np.concatenate(metric_results)
valid_rows.append(i)
# Average evaluation results by user.
total_val_metrics = total_val_metrics[valid_rows]
avg_val_metrics = (total_val_metrics.mean(axis=0)).tolist()
# Summary evaluation results into a dict.
ind, result = 0, OrderedDict()
for metric in self.metrics:
values = avg_val_metrics[ind:ind + len(metric)]
if len(values) <= 1:
result[str(metric)] = values
else:
for name, value in zip(str(metric).split(','), values):
result[name] = value
ind += len(metric)
return result
def one_stage_eval(self, logits):
sort_idx = torch.argsort(logits, dim=1, descending=True).cpu().numpy()
impression_ids = []
for i in range(NUM_USERS):
for j in sort_idx[i]:
if j not in self.a[self.u == i]:
break
impression_ids.append(i * NUM_ITEMS + j)
feats, labels = self.syn[impression_ids]
feats["impression_feats"]["real_feats"] = torch.mean(
self.syn.impression_feats["real_feats"].view(NUM_USERS, NUM_ITEMS),
dim=1).view(-1, 1)
with torch.no_grad():
self.simulator.eval()
feats = self.syn.to_device(feats)
outputs = torch.sigmoid(self.simulator(**feats))
return torch.mean(
(outputs > self.syn.cut).to(dtype=torch.float32)).item()
def two_stage_eval(self, logits, ranker, k=30):
sort_idx = torch.argsort(logits, dim=1, descending=True).cpu().numpy()
topk_item_ids = []
for i in range(NUM_USERS):
topk_item_ids.append([])
for j in sort_idx[i]:
if j not in self.a[self.u == i]:
topk_item_ids[-1].append(j)
if len(topk_item_ids[-1]) == k:
break
time_feats = self.syn.to_device(
torch.mean(
self.syn.impression_feats["real_feats"].view(
NUM_USERS, NUM_ITEMS),
dim=1).view(-1, 1))
recommneded = []
for i in range(NUM_USERS):
user_feats = {
key: value[i].view(1, -1)
for key, value in self.syn.user_feats.items()
}
item_feats = {
key: value[topk_item_ids[i]]
for key, value in self.syn.item_feats.items()
}
user_feats = self.syn.to_device(user_feats)
item_feats = self.syn.to_device(item_feats)
impression_feats = {"real_feats": time_feats[i].view(1, -1)}
ranker_logits = ranker(user_feats, item_feats,
impression_feats).view(1, -1)
_, pred = torch.max(ranker_logits, 1)
pred = pred.squeeze().item()
recommneded.append(topk_item_ids[i][pred])
impression_ids = []
for i in range(NUM_USERS):
impression_ids.append(i * NUM_ITEMS + recommneded[i])
feats, labels = self.syn[impression_ids]
feats["impression_feats"]["real_feats"] = torch.mean(
self.syn.impression_feats["real_feats"].view(NUM_USERS, NUM_ITEMS),
dim=1).view(-1, 1)
with torch.no_grad():
self.simulator.eval()
feats = self.syn.to_device(feats)
outputs = torch.sigmoid(self.simulator(**feats))
return torch.mean(
(outputs > self.syn.cut).to(dtype=torch.float32)).item()
Losses¶
def batch_select(mat, idx):
mask = torch.arange(mat.size(1)).expand_as(mat).to(
mat.device, dtype=torch.long)
mask = (mask == idx.view(-1, 1))
return torch.masked_select(mat, mask)
def unique_and_padding(mat, padding_idx, dim=-1):
"""Conducts unique operation along dim and pads to the same length."""
samples, _ = torch.sort(mat, dim=dim)
samples_roll = torch.roll(samples, -1, dims=dim)
samples_diff = samples - samples_roll
samples_diff[:,
-1] = 1 # deal with the edge case that there is only one unique sample in a row
samples_mask = torch.bitwise_not(samples_diff == 0) # unique mask
samples *= samples_mask.to(dtype=samples.dtype)
samples += (1 - samples_mask.to(dtype=samples.dtype)) * padding_idx
samples, _ = torch.sort(samples, dim=dim)
# shrink size to max unique length
samples = torch.unique(samples, dim=dim)
return samples
def loss_ce(logits, a, unused_p=None, unused_ranker_logits=None):
"""Cross entropy."""
return -torch.mean(batch_select(F.log_softmax(logits, dim=1), a))
def loss_ips(logits,
a,
p,
unused_ranker_logits=None,
upper_limit=100,
lower_limit=0.01):
"""IPS loss (one-stage)."""
importance_weight = batch_select(F.softmax(logits.detach(), dim=1), a) / p
importance_weight = torch.where(
importance_weight > lower_limit, importance_weight,
lower_limit * torch.ones_like(importance_weight))
importance_weight = torch.where(
importance_weight < upper_limit, importance_weight,
upper_limit * torch.ones_like(importance_weight))
importance_weight /= torch.mean(importance_weight)
return -torch.mean(
batch_select(F.log_softmax(logits, dim=1), a) * importance_weight)
def loss_2s(logits,
a,
p,
ranker_logits,
slate_sample_size=100,
slate_size=30,
temperature=np.e,
alpha=1e-5,
upper_limit=100,
lower_limit=0.01):
"""Two stage loss."""
num_logits = logits.size(1)
rls = ranker_logits.detach()
probs = F.softmax(logits.detach() / temperature, dim=1)
log_probs = F.log_softmax(logits, dim=1)
rls = torch.cat(
[
rls,
torch.Tensor([float("-inf")]).to(rls.device).view(1, 1).expand(
rls.size(0), 1)
],
dim=1)
log_probs = torch.cat(
[log_probs,
torch.zeros(log_probs.size(0), 1).to(log_probs.device)],
dim=1)
importance_weight = batch_select(F.softmax(logits.detach(), dim=1), a) / p
importance_weight = torch.where(
importance_weight > lower_limit, importance_weight,
lower_limit * torch.ones_like(importance_weight))
importance_weight = torch.where(
importance_weight < upper_limit, importance_weight,
upper_limit * torch.ones_like(importance_weight))
importance_weight /= torch.mean(importance_weight)
log_action_res = []
sampled_slate_res = []
for i in range(probs.size(0)):
samples = torch.multinomial(
probs[i], slate_sample_size * slate_size, replacement=True).view(
slate_sample_size, slate_size)
samples = torch.cat(
[samples, a[i].view(1, 1).expand(samples.size(0), 1)], dim=1)
samples = unique_and_padding(samples, num_logits)
rp = F.softmax(
F.embedding(samples, rls[i].view(-1, 1)).squeeze(-1), dim=1)
lp = torch.sum(
F.embedding(samples, log_probs[i].view(-1, 1)).squeeze(-1),
dim=1) - log_probs[i, a[i]]
sampled_slate_res.append(
torch.mean(importance_weight[i] * rp[samples == a[i]] * lp))
log_action_res.append(
torch.mean(importance_weight[i] * rp[samples == a[i]]))
loss = -torch.mean(
torch.stack(log_action_res) * batch_select(log_probs, a))
loss += -torch.mean(torch.stack(sampled_slate_res)) * alpha
return loss
Main¶
!pip install -q torchnet
import argparse
import os
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from six.moves import cPickle as pickle
from torch.utils.data import DataLoader, Subset
from torchnet.meter import AUCMeter
parser = argparse.ArgumentParser()
parser.add_argument("--verbose", type=int, default=1, help="Verbose.")
parser.add_argument("--seed", type=int, default=0, help="Random seed.")
parser.add_argument("--loss_type", default="loss_ce")
parser.add_argument("--device", default="cuda:0")
parser.add_argument("--alpha", type=float, default=1e-3, help="Loss ratio.")
parser.add_argument("--lr", type=float, default=0.05, help="Learning rate.")
args = parser.parse_args(args={})
torch.manual_seed(0)
torch.cuda.manual_seed(0)
filepath = "./ml-1m"
device = args.device
dataset = MovieLensDataset(filepath, device=device)
NUM_ITEMS = dataset.NUM_ITEMS
NUM_YEARS = dataset.NUM_YEARS
NUM_GENRES = dataset.NUM_GENRES
NUM_USERS = dataset.NUM_USERS
NUM_OCCUPS = dataset.NUM_OCCUPS
NUM_AGES = dataset.NUM_AGES
NUM_ZIPS = dataset.NUM_ZIPS
simulator_path = os.path.join(filepath, "simulator.pt")
if os.path.exists(simulator_path):
simulator = ImpressionSimulator(use_impression_feats=True)
simulator.load_state_dict(torch.load(simulator_path))
simulator.to(device)
simulator.eval()
else:
# train a simulator model on the original ML-1M dataset
# the simulator will be used to generate synthetic labels later
torch.manual_seed(0)
torch.cuda.manual_seed(0)
num_samples = len(dataset)
train_loader = DataLoader(
Subset(dataset, list(range(num_samples * 3 // 5))),
batch_size=128,
shuffle=True)
val_loader = DataLoader(
Subset(dataset,
list(range(num_samples * 3 // 5, num_samples * 4 // 5))),
batch_size=128)
test_loader = DataLoader(
Subset(dataset, list(range(num_samples * 4 // 5, num_samples))),
batch_size=128)
simulator = ImpressionSimulator(use_impression_feats=True).to(device)
opt = torch.optim.Adagrad(
simulator.parameters(), lr=0.05, weight_decay=1e-4)
criterion = nn.BCEWithLogitsLoss()
simulator.train()
for epoch in range(4):
print("---epoch {}---".format(epoch))
for step, batch in enumerate(train_loader):
feats, labels = batch
logits = simulator(**feats)
loss = criterion(logits, labels)
opt.zero_grad()
loss.backward()
opt.step()
if (step + 1) % 500 == 0:
with torch.no_grad():
simulator.eval()
auc = AUCMeter()
for feats, labels in val_loader:
outputs = torch.sigmoid(simulator(**feats))
auc.add(outputs, labels)
print(step, auc.value()[0])
if auc.value()[0] > 0.735:
break
simulator.train()
simulator.to("cpu")
torch.save(simulator.state_dict(), simulator_path)
---epoch 0---
499 0.6932387523620361
999 0.7135402368767171
1499 0.7215369956250887
1999 0.7251487885185414
2499 0.7250320801426405
2999 0.7272670074151073
3499 0.7281266442311184
3999 0.7294850286875231
4499 0.7296389614963857
---epoch 1---
499 0.7283547770191316
999 0.7295152100721607
1499 0.7300909216769196
1999 0.7302949709078976
2499 0.7307115513456678
2999 0.7303182560548731
3499 0.729832712732132
3999 0.7313203021611654
4499 0.7318606932964403
---epoch 2---
499 0.7313658487455917
999 0.731270933721071
1499 0.7307394064320014
1999 0.7323340285603053
2499 0.7322074757365146
2999 0.7321213073333425
3499 0.7330514084885155
3999 0.7328071902744475
4499 0.7332603719115534
---epoch 3---
499 0.7324623727995114
999 0.7323136933519381
1499 0.7327187807719571
1999 0.7329365712368654
2499 0.7318917432430467
2999 0.733582752772605
3499 0.7342934273983486
3999 0.7341365564445322
4499 0.7340031962421637
# create a torch dataset class that adopt the simulator and generate the synthetic dataset
synthetic_data_path = os.path.join(filepath, "full_impression_feats.pt")
syn = SyntheticMovieLensDataset(
filepath, simulator_path, synthetic_data_path, device=device)
logging_policy_path = os.path.join(filepath, "logging_policy.pt")
if os.path.exists(logging_policy_path):
logging_policy = Nominator()
logging_policy.load_state_dict(torch.load(logging_policy_path))
logging_policy.to(device)
logging_policy.eval()
else:
# train a logging policy using the synthetic dataset
num_samples = len(syn)
idx_list = list(range(num_samples))
rs = np.random.RandomState(0)
rs.shuffle(idx_list)
train_idx = idx_list[:10000]
val_idx = idx_list[10000:20000]
test_idx = idx_list[-100000:]
train_loader = DataLoader(
Subset(syn, train_idx), batch_size=128, shuffle=True)
val_loader = DataLoader(Subset(syn, val_idx), batch_size=128)
test_loader = DataLoader(Subset(syn, test_idx), batch_size=128)
logging_policy = Nominator().to(device)
opt = torch.optim.Adagrad(
logging_policy.parameters(), lr=0.05, weight_decay=1e-4)
criterion = nn.BCEWithLogitsLoss()
logging_policy.train()
for epoch in range(40):
print("---epoch {}---".format(epoch))
for step, batch in enumerate(train_loader):
feats, labels = batch
feats = syn.to_device(feats)
labels = syn.to_device(labels)
logits = logging_policy(feats["user_feats"], feats["item_feats"])
loss = criterion(logits, labels)
opt.zero_grad()
loss.backward()
opt.step()
with torch.no_grad():
logging_policy.eval()
auc = AUCMeter()
for feats, labels in val_loader:
feats = syn.to_device(feats)
labels = syn.to_device(labels)
outputs = torch.sigmoid(
logging_policy(feats["user_feats"], feats["item_feats"]))
auc.add(outputs, labels)
print(step, auc.value()[0])
logging_policy.train()
logging_policy.eval()
logging_policy.to("cpu")
torch.save(logging_policy.state_dict(), logging_policy_path)
logging_policy.to(device)
generating impression_feats
100%|██████████| 46906/46906 [01:04<00:00, 726.33it/s]
saved impression_feats
---epoch 0---
78 0.7303382306338263
---epoch 1---
78 0.7581630234600971
---epoch 2---
78 0.7758875382286556
---epoch 3---
78 0.7947954816858157
---epoch 4---
78 0.8092959307857327
---epoch 5---
78 0.8209026242576345
---epoch 6---
78 0.8281561300331621
---epoch 7---
78 0.831641647559472
---epoch 8---
78 0.8359850391331326
---epoch 9---
78 0.838561799838773
---epoch 10---
78 0.8401704563395371
---epoch 11---
78 0.8411352317648504
---epoch 12---
78 0.8419039896279034
---epoch 13---
78 0.8420276300116679
---epoch 14---
78 0.8417600912427988
---epoch 15---
78 0.8424424910531916
---epoch 16---
78 0.8427186846489241
---epoch 17---
78 0.8426326119202265
---epoch 18---
78 0.8428287245904745
---epoch 19---
78 0.842670274683281
---epoch 20---
78 0.8428754226123425
---epoch 21---
78 0.8429700550599161
---epoch 22---
78 0.8431265076993719
---epoch 23---
78 0.8433620901844372
---epoch 24---
78 0.8435445073044836
---epoch 25---
78 0.8435860694950261
---epoch 26---
78 0.8435829309314381
---epoch 27---
78 0.843662155885035
---epoch 28---
78 0.8437115169305534
---epoch 29---
78 0.8438241247877666
---epoch 30---
78 0.843904205713251
---epoch 31---
78 0.843980862751185
---epoch 32---
78 0.8440994624116114
---epoch 33---
78 0.8442256707110387
---epoch 34---
78 0.8444167426579487
---epoch 35---
78 0.8444864568127943
---epoch 36---
78 0.8446461431238256
---epoch 37---
78 0.8447101507994208
---epoch 38---
78 0.8447210882179845
---epoch 39---
78 0.8447308843406981
def generate_bandit_samples(logging_policy, syn, k=5):
"""Generates partial-labeled bandit samples with the logging policy.
Arguments:
k: The number of items to be sampled for each user.
"""
logging_policy.set_binary(False)
with torch.no_grad():
feats = {}
feats["user_feats"] = syn.user_feats
feats["item_feats"] = syn.item_feats
feats = syn.to_device(feats)
probs = F.softmax(logging_policy(**feats), dim=1)
sampled_users = []
sampled_actions = []
sampled_probs = []
sampled_rewards = []
for i in range(probs.size(0)):
sampled_users.append([i] * k)
sampled_actions.append(
torch.multinomial(probs[i], k).cpu().numpy().tolist())
sampled_probs.append(
probs[i, sampled_actions[-1]].cpu().numpy().tolist())
sampled_rewards.append(syn.impression_feats["labels"][[
i * probs.size(1) + j for j in sampled_actions[-1]
]].numpy().tolist())
return np.array(sampled_users).reshape(-1), np.array(
sampled_actions).reshape(-1), np.array(sampled_probs).reshape(
-1), np.array(sampled_rewards).reshape(-1)
torch.manual_seed(0)
torch.cuda.manual_seed(0)
u, a, p, r = generate_bandit_samples(
logging_policy, syn,
k=5) # u: user, a: item, p: logging policy probability, r: reward/label
simulator = simulator.to(device)
ev = Evaluator(u[r > 0], a[r > 0], simulator, syn)
all_user_feats = syn.to_device(syn.user_feats)
all_item_feats = syn.to_device(syn.item_feats)
all_impression_feats = syn.to_device({
"real_feats":
torch.mean(
syn.impression_feats["real_feats"].view(NUM_USERS, NUM_ITEMS),
dim=1).view(-1, 1)
})
# Split validation/test users.
num_val_users = 2000
val_user_list = list(range(0, num_val_users))
test_user_list = list(range(num_val_users, NUM_USERS))
test_item_feats = all_item_feats
test_user_feats = syn.to_device(
{key: value[test_user_list]
for key, value in all_user_feats.items()})
test_impression_feats = syn.to_device({
key: value[test_user_list]
for key, value in all_impression_feats.items()
})
val_item_feats = all_item_feats
val_user_feats = syn.to_device(
{key: value[val_user_list]
for key, value in all_user_feats.items()})
val_impression_feats = syn.to_device(
{key: value[val_user_list]
for key, value in all_impression_feats.items()})
ranker_path = os.path.join(filepath, "ranker.pt")
if os.path.exists(ranker_path):
ranker = Ranker()
ranker.load_state_dict(torch.load(ranker_path))
ranker.to(device)
ranker.eval()
ranker.set_binary(False)
else:
# train the ranker with binary cross-entropy
torch.manual_seed(0)
torch.cuda.manual_seed(0)
batch_size = 128
neg_sample_size = 29
ranker = Ranker().to(device)
opt = torch.optim.Adagrad(ranker.parameters(), lr=0.05, weight_decay=1e-4)
criterion = nn.BCEWithLogitsLoss()
rs = np.random.RandomState(0)
ranker.train()
for epoch in range(10):
print("---epoch {}---".format(epoch))
for step in range(len(u) // batch_size):
user_list = u[step * batch_size:(step + 1) * batch_size]
item_list = a[step * batch_size:(step + 1) * batch_size]
user_feats = syn.to_device({
key: value[user_list]
for key, value in syn.user_feats.items()
})
item_feats = syn.to_device({
key: value[item_list]
for key, value in syn.item_feats.items()
})
impression_list = [
user_id * NUM_ITEMS + item_id
for user_id, item_id in zip(user_list, item_list)
]
impression_feats = syn.to_device({
"real_feats":
syn.impression_feats["real_feats"][impression_list]
})
labels = torch.FloatTensor(
r[step * batch_size:(step + 1) * batch_size]).to(device)
logits = ranker(user_feats, item_feats, impression_feats)
loss = criterion(logits, labels)
opt.zero_grad()
loss.backward()
opt.step()
with torch.no_grad():
ranker.eval()
ranker.set_binary(False)
logits = ranker(all_user_feats, all_item_feats,
all_impression_feats)
print(step, ev.one_stage_eval(logits))
# Evaluate ranking metrics on validation users.
logits = ranker(val_user_feats, val_item_feats,
val_impression_feats)
print(step, ev.one_stage_ranking_eval(logits, val_user_list))
ranker.train()
ranker.set_binary(True)
ranker.eval()
ranker.set_binary(False)
ranker.to("cpu")
torch.save(ranker.state_dict(), ranker_path)
ranker.to(device)
---epoch 0---
234 0.49751657247543335
234 OrderedDict([('Precision@1', 0.525853157043457), ('Precision@5', 0.37435382604599), ('Precision@10', 0.3275078535079956), ('Recall@1', 0.001950422883965075), ('Recall@5', 0.006817308254539967), ('Recall@10', 0.011337128467857838), ('NDCG@5', 0.40602830052375793), ('NDCG@10', 0.36229410767555237), ('NDCG@20', 0.3150430917739868)])
---epoch 1---
234 0.5798013210296631
234 OrderedDict([('Precision@1', 0.6003102660179138), ('Precision@5', 0.4798329174518585), ('Precision@10', 0.42228519916534424), ('Recall@1', 0.002812947379425168), ('Recall@5', 0.011755581945180893), ('Recall@10', 0.02120870165526867), ('NDCG@5', 0.5004847645759583), ('NDCG@10', 0.45322883129119873), ('NDCG@20', 0.39284855127334595)])
---epoch 2---
234 0.5889073014259338
234 OrderedDict([('Precision@1', 0.6106514930725098), ('Precision@5', 0.5765244960784912), ('Precision@10', 0.5148389339447021), ('Recall@1', 0.003235821146517992), ('Recall@5', 0.016686489805579185), ('Recall@10', 0.03442412614822388), ('NDCG@5', 0.5764947533607483), ('NDCG@10', 0.5345680713653564), ('NDCG@20', 0.4556241035461426)])
---epoch 3---
234 0.628311276435852
234 OrderedDict([('Precision@1', 0.6411582231521606), ('Precision@5', 0.6560497283935547), ('Precision@10', 0.6184099912643433), ('Recall@1', 0.0033987725619226694), ('Recall@5', 0.0258512943983078), ('Recall@10', 0.045876603573560715), ('NDCG@5', 0.6525105237960815), ('NDCG@10', 0.6282448172569275), ('NDCG@20', 0.5369541049003601)])
---epoch 4---
234 0.7625827789306641
234 OrderedDict([('Precision@1', 0.7487073540687561), ('Precision@5', 0.750673770904541), ('Precision@10', 0.6952475309371948), ('Recall@1', 0.004413578659296036), ('Recall@5', 0.033956073224544525), ('Recall@10', 0.05853657424449921), ('NDCG@5', 0.7535479068756104), ('NDCG@10', 0.715246319770813), ('NDCG@20', 0.6256369352340698)])
---epoch 5---
234 0.8622516989707947
234 OrderedDict([('Precision@1', 0.8490175604820251), ('Precision@5', 0.8347484469413757), ('Precision@10', 0.7592080235481262), ('Recall@1', 0.009471286088228226), ('Recall@5', 0.045272961258888245), ('Recall@10', 0.07097340375185013), ('NDCG@5', 0.840373158454895), ('NDCG@10', 0.7897650003433228), ('NDCG@20', 0.717039942741394)])
---epoch 6---
234 0.9102649092674255
234 OrderedDict([('Precision@1', 0.9089968800544739), ('Precision@5', 0.8815937042236328), ('Precision@10', 0.8184615969657898), ('Recall@1', 0.015791630372405052), ('Recall@5', 0.053664132952690125), ('Recall@10', 0.07895129173994064), ('NDCG@5', 0.8917895555496216), ('NDCG@10', 0.8513309359550476), ('NDCG@20', 0.7841229438781738)])
---epoch 7---
234 0.9369205236434937
234 OrderedDict([('Precision@1', 0.9441571831703186), ('Precision@5', 0.9020691514015198), ('Precision@10', 0.8512938618659973), ('Recall@1', 0.01766125112771988), ('Recall@5', 0.05773942917585373), ('Recall@10', 0.08265078067779541), ('NDCG@5', 0.9147428274154663), ('NDCG@10', 0.8829164505004883), ('NDCG@20', 0.8230650424957275)])
---epoch 8---
234 0.9519867897033691
234 OrderedDict([('Precision@1', 0.9565666913986206), ('Precision@5', 0.9139613509178162), ('Precision@10', 0.8667538166046143), ('Recall@1', 0.01800968125462532), ('Recall@5', 0.060318805277347565), ('Recall@10', 0.08457545191049576), ('NDCG@5', 0.9267275929450989), ('NDCG@10', 0.8979306817054749), ('NDCG@20', 0.844747006893158)])
---epoch 9---
234 0.9541391134262085
234 OrderedDict([('Precision@1', 0.9601861238479614), ('Precision@5', 0.9185118079185486), ('Precision@10', 0.8744063973426819), ('Recall@1', 0.018171625211834908), ('Recall@5', 0.061439476907253265), ('Recall@10', 0.08633137494325638), ('NDCG@5', 0.9311888217926025), ('NDCG@10', 0.9044811129570007), ('NDCG@20', 0.8586583733558655)])
u = u[r > 0]
a = a[r > 0]
p = p[r > 0]
batch_size = 128
check_metric = "Precision@10"
torch.manual_seed(args.seed)
torch.cuda.manual_seed(args.seed)
nominator = Nominator().to(device)
nominator.set_binary(False)
opt = torch.optim.Adagrad(
nominator.parameters(), lr=args.lr, weight_decay=1e-4)
rs = np.random.RandomState(0)
nominator.train()
Nominator(
(item_rep): ItemRep(
(item_embedding): Embedding(3884, 10, padding_idx=0)
(year_embedding): Embedding(81, 5)
(genre_linear): Linear(in_features=18, out_features=5, bias=True)
)
(user_rep): UserRep(
(user_embedding): Embedding(6041, 10, padding_idx=0)
(gender_embedding): Embedding(2, 5)
(age_embedding): Embedding(7, 5)
(occup_embedding): Embedding(21, 5)
(zip_embedding): Embedding(3439, 5)
)
(linear): Linear(in_features=30, out_features=20, bias=True)
)
# Init results.
best_epoch = 0
best_result = 0.0
val_results, test_results = [], []
if args.loss_type == "loss_2s":
with torch.no_grad():
ranker.eval()
ranker.set_binary(False)
ranker_logits = ranker(all_user_feats, all_item_feats,
all_impression_feats)
for epoch in range(20):
print("---epoch {}---".format(epoch))
for step in range(len(u) // batch_size):
item_ids = torch.LongTensor(
a[step * batch_size:(step + 1) * batch_size]).to(device)
item_probs = torch.FloatTensor(
p[step * batch_size:(step + 1) * batch_size]).to(device)
user_ids = u[step * batch_size:(step + 1) * batch_size]
user_feats = {
key: value[user_ids]
for key, value in syn.user_feats.items()
}
user_feats = syn.to_device(user_feats)
logits = nominator(user_feats, val_item_feats)
if args.loss_type == "loss_ce":
loss = loss_ce(logits, item_ids, item_probs)
elif args.loss_type == "loss_ips":
loss = loss_ips(logits, item_ids, item_probs, upper_limit=10)
elif args.loss_type == "loss_2s":
batch_ranker_logits = F.embedding(
torch.LongTensor(user_ids).to(device), ranker_logits)
loss = loss_2s(
logits,
item_ids,
item_probs,
batch_ranker_logits,
upper_limit=10,
alpha=args.alpha)
else:
raise NotImplementedError(
"{} not supported.".format(args.loss_type))
opt.zero_grad()
loss.backward()
opt.step()
with torch.no_grad():
nominator.eval()
logits = nominator(all_user_feats, all_item_feats)
print("1 stage", ev.one_stage_eval(logits))
print("2 stage", ev.two_stage_eval(logits, ranker))
# Evaluate ranking metrics on validation users.
logits = nominator(val_user_feats, val_item_feats)
one_stage_results = ev.one_stage_ranking_eval(logits, val_user_list)
print("1 stage (val)", one_stage_results)
two_stage_results = ev.two_stage_ranking_eval(logits, ranker,
val_user_list)
print("2 stage (val)", two_stage_results)
val_results.append((one_stage_results, two_stage_results))
# Log best epoch
if two_stage_results[check_metric] > best_result:
best_epoch = epoch
best_result = two_stage_results[check_metric]
# Evaluate ranking metrics on test users.
logits = nominator(test_user_feats, test_item_feats)
one_stage_results = ev.one_stage_ranking_eval(logits, test_user_list)
print("1 stage (test)", one_stage_results)
two_stage_results = ev.two_stage_ranking_eval(logits, ranker,
test_user_list)
print("2 stage (test)", two_stage_results)
test_results.append((one_stage_results, two_stage_results))
nominator.train()
---epoch 0---
1 stage 0.8389073014259338
2 stage 0.931456983089447
1 stage (val) OrderedDict([('Precision@1', 0.7761116623878479), ('Precision@5', 0.7825230956077576), ('Precision@10', 0.7693895101547241), ('Recall@1', 0.0026108406018465757), ('Recall@5', 0.01443537138402462), ('Recall@10', 0.02800210937857628), ('NDCG@5', 0.7805129289627075), ('NDCG@10', 0.7720701694488525), ('NDCG@20', 0.7773204445838928)])
2 stage (val) OrderedDict([('Precision@1', 0.9152016639709473), ('Precision@5', 0.8799382448196411), ('Precision@10', 0.8639603853225708), ('Recall@1', 0.010427681729197502), ('Recall@5', 0.02969161979854107), ('Recall@10', 0.04909321665763855), ('NDCG@5', 0.8888923525810242), ('NDCG@10', 0.8768721222877502), ('NDCG@20', 0.8476952910423279)])
1 stage (test) OrderedDict([('Precision@1', 0.894406795501709), ('Precision@5', 0.8917496204376221), ('Precision@10', 0.8819892406463623), ('Recall@1', 0.003005631733685732), ('Recall@5', 0.015431685373187065), ('Recall@10', 0.030124178156256676), ('NDCG@5', 0.8914320468902588), ('NDCG@10', 0.8846309781074524), ('NDCG@20', 0.8876312971115112)])
2 stage (test) OrderedDict([('Precision@1', 0.9671432375907898), ('Precision@5', 0.9465765357017517), ('Precision@10', 0.9378731846809387), ('Recall@1', 0.006223659496754408), ('Recall@5', 0.022564038634300232), ('Recall@10', 0.0406784787774086), ('NDCG@5', 0.9511790871620178), ('NDCG@10', 0.9443507790565491), ('NDCG@20', 0.9283153414726257)])
---epoch 1---
1 stage 0.8367549777030945
2 stage 0.9365894198417664
1 stage (val) OrderedDict([('Precision@1', 0.7730093002319336), ('Precision@5', 0.780661404132843), ('Precision@10', 0.7693895101547241), ('Recall@1', 0.002592692384496331), ('Recall@5', 0.01431603729724884), ('Recall@10', 0.027908695861697197), ('NDCG@5', 0.7788269519805908), ('NDCG@10', 0.7716042399406433), ('NDCG@20', 0.7761374115943909)])
2 stage (val) OrderedDict([('Precision@1', 0.9255428910255432), ('Precision@5', 0.883350670337677), ('Precision@10', 0.8641155958175659), ('Recall@1', 0.012946750037372112), ('Recall@5', 0.03286115825176239), ('Recall@10', 0.052004944533109665), ('NDCG@5', 0.894393801689148), ('NDCG@10', 0.8804171681404114), ('NDCG@20', 0.851220965385437)])
1 stage (test) OrderedDict([('Precision@1', 0.8926511406898499), ('Precision@5', 0.889492392539978), ('Precision@10', 0.8817635774612427), ('Recall@1', 0.002984470222145319), ('Recall@5', 0.01524937804788351), ('Recall@10', 0.030079031363129616), ('NDCG@5', 0.8897153735160828), ('NDCG@10', 0.8841732740402222), ('NDCG@20', 0.8868218660354614)])
2 stage (test) OrderedDict([('Precision@1', 0.9699021577835083), ('Precision@5', 0.9467771649360657), ('Precision@10', 0.9376724362373352), ('Recall@1', 0.007032747846096754), ('Recall@5', 0.023379521444439888), ('Recall@10', 0.04146404191851616), ('NDCG@5', 0.9522501826286316), ('NDCG@10', 0.9452073574066162), ('NDCG@20', 0.9290862083435059)])
---epoch 2---
1 stage 0.8357616066932678
2 stage 0.9385761618614197
1 stage (val) OrderedDict([('Precision@1', 0.771458089351654), ('Precision@5', 0.7803509831428528), ('Precision@10', 0.7697516083717346), ('Recall@1', 0.002546904841437936), ('Recall@5', 0.014310559257864952), ('Recall@10', 0.027927899733185768), ('NDCG@5', 0.7782995104789734), ('NDCG@10', 0.7716609239578247), ('NDCG@20', 0.7768319845199585)])
2 stage (val) OrderedDict([('Precision@1', 0.9281282424926758), ('Precision@5', 0.8846949934959412), ('Precision@10', 0.8650981783866882), ('Recall@1', 0.013078119605779648), ('Recall@5', 0.03309616446495056), ('Recall@10', 0.05231418088078499), ('NDCG@5', 0.895997166633606), ('NDCG@10', 0.8816695213317871), ('NDCG@20', 0.8517394661903381)])
1 stage (test) OrderedDict([('Precision@1', 0.8918986916542053), ('Precision@5', 0.8886397480964661), ('Precision@10', 0.8822652101516724), ('Recall@1', 0.002973585156723857), ('Recall@5', 0.015205418691039085), ('Recall@10', 0.030113695189356804), ('NDCG@5', 0.8889814615249634), ('NDCG@10', 0.8843721747398376), ('NDCG@20', 0.886855959892273)])
2 stage (test) OrderedDict([('Precision@1', 0.9716578722000122), ('Precision@5', 0.9481315016746521), ('Precision@10', 0.9381741285324097), ('Recall@1', 0.007616504095494747), ('Recall@5', 0.024297403171658516), ('Recall@10', 0.0423288531601429), ('NDCG@5', 0.9539521932601929), ('NDCG@10', 0.9464597702026367), ('NDCG@20', 0.9301363229751587)])
---epoch 3---
1 stage 0.8339403867721558
2 stage 0.940562903881073
1 stage (val) OrderedDict([('Precision@1', 0.7683557271957397), ('Precision@5', 0.7795237898826599), ('Precision@10', 0.7704238891601562), ('Recall@1', 0.0025028539821505547), ('Recall@5', 0.014192001894116402), ('Recall@10', 0.028007399290800095), ('NDCG@5', 0.7769649624824524), ('NDCG@10', 0.7715820074081421), ('NDCG@20', 0.7766546607017517)])
2 stage (val) OrderedDict([('Precision@1', 0.9332988858222961), ('Precision@5', 0.8861426711082458), ('Precision@10', 0.8660286664962769), ('Recall@1', 0.01370152272284031), ('Recall@5', 0.034078482538461685), ('Recall@10', 0.05330389738082886), ('NDCG@5', 0.8979603052139282), ('NDCG@10', 0.88340163230896), ('NDCG@20', 0.8530087471008301)])
1 stage (test) OrderedDict([('Precision@1', 0.8906446099281311), ('Precision@5', 0.8880879282951355), ('Precision@10', 0.8825662732124329), ('Recall@1', 0.002958007389679551), ('Recall@5', 0.015176204033195972), ('Recall@10', 0.030142122879624367), ('NDCG@5', 0.8884179592132568), ('NDCG@10', 0.884431004524231), ('NDCG@20', 0.8868438005447388)])
2 stage (test) OrderedDict([('Precision@1', 0.9721595048904419), ('Precision@5', 0.9488838315010071), ('Precision@10', 0.938500165939331), ('Recall@1', 0.00781310349702835), ('Recall@5', 0.02463247813284397), ('Recall@10', 0.04265395551919937), ('NDCG@5', 0.9547868967056274), ('NDCG@10', 0.9471161961555481), ('NDCG@20', 0.9306148290634155)])
---epoch 4---
1 stage 0.8331125974655151
2 stage 0.9425497055053711
1 stage (val) OrderedDict([('Precision@1', 0.7652533650398254), ('Precision@5', 0.7786965370178223), ('Precision@10', 0.7709408402442932), ('Recall@1', 0.0024512740783393383), ('Recall@5', 0.014100495725870132), ('Recall@10', 0.028065374121069908), ('NDCG@5', 0.7758020758628845), ('NDCG@10', 0.7715065479278564), ('NDCG@20', 0.7763851284980774)])
2 stage (val) OrderedDict([('Precision@1', 0.9358841776847839), ('Precision@5', 0.8872801661491394), ('Precision@10', 0.8661839962005615), ('Recall@1', 0.013996284455060959), ('Recall@5', 0.03461095318198204), ('Recall@10', 0.05393322929739952), ('NDCG@5', 0.8994066715240479), ('NDCG@10', 0.8842594623565674), ('NDCG@20', 0.8535211086273193)])
1 stage (test) OrderedDict([('Precision@1', 0.890895426273346), ('Precision@5', 0.8875863552093506), ('Precision@10', 0.8828924298286438), ('Recall@1', 0.002969894791021943), ('Recall@5', 0.015152904205024242), ('Recall@10', 0.03018353506922722), ('NDCG@5', 0.887993335723877), ('NDCG@10', 0.8845545053482056), ('NDCG@20', 0.886780858039856)])
2 stage (test) OrderedDict([('Precision@1', 0.9739152193069458), ('Precision@5', 0.9496864676475525), ('Precision@10', 0.9387760162353516), ('Recall@1', 0.007960631512105465), ('Recall@5', 0.024898577481508255), ('Recall@10', 0.04285132512450218), ('NDCG@5', 0.9557564854621887), ('NDCG@10', 0.9477135539054871), ('NDCG@20', 0.9310080409049988)])
---epoch 5---
1 stage 0.8336092829704285
2 stage 0.942218542098999
1 stage (val) OrderedDict([('Precision@1', 0.765770435333252), ('Precision@5', 0.7783864140510559), ('Precision@10', 0.7712510228157043), ('Recall@1', 0.0024701899383217096), ('Recall@5', 0.014151088893413544), ('Recall@10', 0.02811473049223423), ('NDCG@5', 0.7756521701812744), ('NDCG@10', 0.7717127799987793), ('NDCG@20', 0.7761114239692688)])
2 stage (val) OrderedDict([('Precision@1', 0.9364012479782104), ('Precision@5', 0.888003945350647), ('Precision@10', 0.8662872314453125), ('Recall@1', 0.013898404315114021), ('Recall@5', 0.03511940315365791), ('Recall@10', 0.05434870347380638), ('NDCG@5', 0.8998069763183594), ('NDCG@10', 0.8843777179718018), ('NDCG@20', 0.8532311916351318)])
1 stage (test) OrderedDict([('Precision@1', 0.8913970589637756), ('Precision@5', 0.887134850025177), ('Precision@10', 0.8827671408653259), ('Recall@1', 0.0029800296761095524), ('Recall@5', 0.015131834894418716), ('Recall@10', 0.03018496185541153), ('NDCG@5', 0.8876475095748901), ('NDCG@10', 0.8844181895256042), ('NDCG@20', 0.8867219686508179)])
2 stage (test) OrderedDict([('Precision@1', 0.9731627702713013), ('Precision@5', 0.9494857788085938), ('Precision@10', 0.9387760162353516), ('Recall@1', 0.007924147881567478), ('Recall@5', 0.024823080748319626), ('Recall@10', 0.042789481580257416), ('NDCG@5', 0.9554441571235657), ('NDCG@10', 0.9475792646408081), ('NDCG@20', 0.9307677149772644)])
---epoch 6---
1 stage 0.8346026539802551
2 stage 0.9417218565940857
1 stage (val) OrderedDict([('Precision@1', 0.7652533650398254), ('Precision@5', 0.7777659296989441), ('Precision@10', 0.7713546752929688), ('Recall@1', 0.002462433883920312), ('Recall@5', 0.014112057164311409), ('Recall@10', 0.02813573367893696), ('NDCG@5', 0.7751555442810059), ('NDCG@10', 0.7717844247817993), ('NDCG@20', 0.7759582996368408)])
2 stage (val) OrderedDict([('Precision@1', 0.9353671073913574), ('Precision@5', 0.8887278437614441), ('Precision@10', 0.866390585899353), ('Recall@1', 0.013995282351970673), ('Recall@5', 0.035590916872024536), ('Recall@10', 0.05474210903048515), ('NDCG@5', 0.9002852439880371), ('NDCG@10', 0.8846437931060791), ('NDCG@20', 0.8533338904380798)])
1 stage (test) OrderedDict([('Precision@1', 0.8931527733802795), ('Precision@5', 0.8867837190628052), ('Precision@10', 0.8830179572105408), ('Recall@1', 0.0030013115610927343), ('Recall@5', 0.01514824852347374), ('Recall@10', 0.03022931143641472), ('NDCG@5', 0.8876431584358215), ('NDCG@10', 0.8846896886825562), ('NDCG@20', 0.886621356010437)])
2 stage (test) OrderedDict([('Precision@1', 0.9729119539260864), ('Precision@5', 0.9496863484382629), ('Precision@10', 0.9388262033462524), ('Recall@1', 0.007614111993461847), ('Recall@5', 0.024715635925531387), ('Recall@10', 0.04267028719186783), ('NDCG@5', 0.9553412199020386), ('NDCG@10', 0.9473593235015869), ('NDCG@20', 0.9304744601249695)])
---epoch 7---
1 stage 0.8350993394851685
2 stage 0.9408940672874451
1 stage (val) OrderedDict([('Precision@1', 0.7652533650398254), ('Precision@5', 0.7769388556480408), ('Precision@10', 0.771303117275238), ('Recall@1', 0.002458712086081505), ('Recall@5', 0.014063295908272266), ('Recall@10', 0.028185289353132248), ('NDCG@5', 0.7745227813720703), ('NDCG@10', 0.7716432809829712), ('NDCG@20', 0.7753005027770996)])
2 stage (val) OrderedDict([('Precision@1', 0.9322647452354431), ('Precision@5', 0.8887277841567993), ('Precision@10', 0.865925133228302), ('Recall@1', 0.013905792497098446), ('Recall@5', 0.035767413675785065), ('Recall@10', 0.05483044683933258), ('NDCG@5', 0.8999837636947632), ('NDCG@10', 0.8842496871948242), ('NDCG@20', 0.8529420495033264)])
1 stage (test) OrderedDict([('Precision@1', 0.8939051628112793), ('Precision@5', 0.8863823413848877), ('Precision@10', 0.8830680847167969), ('Recall@1', 0.003021263051778078), ('Recall@5', 0.015123428776860237), ('Recall@10', 0.03023369051516056), ('NDCG@5', 0.887448787689209), ('NDCG@10', 0.8847446441650391), ('NDCG@20', 0.886391818523407)])
2 stage (test) OrderedDict([('Precision@1', 0.9731627702713013), ('Precision@5', 0.9496863484382629), ('Precision@10', 0.9387257099151611), ('Recall@1', 0.00767667219042778), ('Recall@5', 0.024805083870887756), ('Recall@10', 0.04274982586503029), ('NDCG@5', 0.9554198384284973), ('NDCG@10', 0.9473903179168701), ('NDCG@20', 0.9302816390991211)])
---epoch 8---
1 stage 0.8354305028915405
2 stage 0.9399006962776184
1 stage (val) OrderedDict([('Precision@1', 0.765770435333252), ('Precision@5', 0.7759048342704773), ('Precision@10', 0.771199643611908), ('Recall@1', 0.0024883777368813753), ('Recall@5', 0.013925631530582905), ('Recall@10', 0.028112078085541725), ('NDCG@5', 0.7737619876861572), ('NDCG@10', 0.7714693546295166), ('NDCG@20', 0.7745940685272217)])
2 stage (val) OrderedDict([('Precision@1', 0.9307135343551636), ('Precision@5', 0.8879006505012512), ('Precision@10', 0.8653048872947693), ('Recall@1', 0.013744794763624668), ('Recall@5', 0.03534204140305519), ('Recall@10', 0.05429835617542267), ('NDCG@5', 0.8989336490631104), ('NDCG@10', 0.8833516836166382), ('NDCG@20', 0.8518505096435547)])
1 stage (test) OrderedDict([('Precision@1', 0.8941559791564941), ('Precision@5', 0.8859308362007141), ('Precision@10', 0.8831183314323425), ('Recall@1', 0.0030219820328056812), ('Recall@5', 0.015090204775333405), ('Recall@10', 0.030239716172218323), ('NDCG@5', 0.8871259689331055), ('NDCG@10', 0.8847541809082031), ('NDCG@20', 0.8861094117164612)])
2 stage (test) OrderedDict([('Precision@1', 0.9724103212356567), ('Precision@5', 0.9492348432540894), ('Precision@10', 0.9386504292488098), ('Recall@1', 0.007493751123547554), ('Recall@5', 0.02462335117161274), ('Recall@10', 0.04261213541030884), ('NDCG@5', 0.9548900723457336), ('NDCG@10', 0.9471115469932556), ('NDCG@20', 0.9297663569450378)])
---epoch 9---
1 stage 0.8354305028915405
2 stage 0.9394040107727051
1 stage (val) OrderedDict([('Precision@1', 0.7673215866088867), ('Precision@5', 0.7746638655662537), ('Precision@10', 0.7714064717292786), ('Recall@1', 0.002514956519007683), ('Recall@5', 0.013873514719307423), ('Recall@10', 0.028209399431943893), ('NDCG@5', 0.7729977965354919), ('NDCG@10', 0.7715849876403809), ('NDCG@20', 0.7738854885101318)])
2 stage (val) OrderedDict([('Precision@1', 0.9312306046485901), ('Precision@5', 0.8884176015853882), ('Precision@10', 0.8655635714530945), ('Recall@1', 0.01376135554164648), ('Recall@5', 0.03537794202566147), ('Recall@10', 0.0541960671544075), ('NDCG@5', 0.8995826244354248), ('NDCG@10', 0.8838357329368591), ('NDCG@20', 0.8522109389305115)])
1 stage (test) OrderedDict([('Precision@1', 0.8934035897254944), ('Precision@5', 0.8860311508178711), ('Precision@10', 0.8833188414573669), ('Recall@1', 0.003013131907209754), ('Recall@5', 0.015086286701261997), ('Recall@10', 0.030243460088968277), ('NDCG@5', 0.8870205283164978), ('NDCG@10', 0.884793758392334), ('NDCG@20', 0.8854647278785706)])
2 stage (test) OrderedDict([('Precision@1', 0.9714070558547974), ('Precision@5', 0.9491847157478333), ('Precision@10', 0.9384247064590454), ('Recall@1', 0.00736744562163949), ('Recall@5', 0.024592455476522446), ('Recall@10', 0.04252685606479645), ('NDCG@5', 0.9546566605567932), ('NDCG@10', 0.9468095302581787), ('NDCG@20', 0.9292915463447571)])
---epoch 10---
1 stage 0.8355960249900818
2 stage 0.9394040107727051
1 stage (val) OrderedDict([('Precision@1', 0.7688727974891663), ('Precision@5', 0.7746636271476746), ('Precision@10', 0.7718202471733093), ('Recall@1', 0.002541040303185582), ('Recall@5', 0.013961467891931534), ('Recall@10', 0.028273116797208786), ('NDCG@5', 0.773000955581665), ('NDCG@10', 0.7718640565872192), ('NDCG@20', 0.7727073431015015)])
2 stage (val) OrderedDict([('Precision@1', 0.9317476749420166), ('Precision@5', 0.8890381455421448), ('Precision@10', 0.8653049468994141), ('Recall@1', 0.01362884882837534), ('Recall@5', 0.03554679825901985), ('Recall@10', 0.05419434234499931), ('NDCG@5', 0.8999322652816772), ('NDCG@10', 0.8837052583694458), ('NDCG@20', 0.8518556952476501)])
1 stage (test) OrderedDict([('Precision@1', 0.8929019570350647), ('Precision@5', 0.885880708694458), ('Precision@10', 0.8833938837051392), ('Recall@1', 0.0030145926866680384), ('Recall@5', 0.015049256384372711), ('Recall@10', 0.030261926352977753), ('NDCG@5', 0.886837363243103), ('NDCG@10', 0.8847842812538147), ('NDCG@20', 0.8847416043281555)])
2 stage (test) OrderedDict([('Precision@1', 0.9711562395095825), ('Precision@5', 0.9493853449821472), ('Precision@10', 0.9385502338409424), ('Recall@1', 0.007329127751290798), ('Recall@5', 0.024591417983174324), ('Recall@10', 0.04251473769545555), ('NDCG@5', 0.9547252058982849), ('NDCG@10', 0.9468643069267273), ('NDCG@20', 0.9290348887443542)])
---epoch 11---
1 stage 0.8360927104949951
2 stage 0.939238429069519
1 stage (val) OrderedDict([('Precision@1', 0.7683557271957397), ('Precision@5', 0.7737331390380859), ('Precision@10', 0.7717682719230652), ('Recall@1', 0.0025312236975878477), ('Recall@5', 0.013931073248386383), ('Recall@10', 0.02832760475575924), ('NDCG@5', 0.7724922895431519), ('NDCG@10', 0.7718040943145752), ('NDCG@20', 0.772021472454071)])
2 stage (val) OrderedDict([('Precision@1', 0.9317476749420166), ('Precision@5', 0.8892449736595154), ('Precision@10', 0.8650463223457336), ('Recall@1', 0.01362884882837534), ('Recall@5', 0.03550821170210838), ('Recall@10', 0.05416148528456688), ('NDCG@5', 0.900104284286499), ('NDCG@10', 0.8835929036140442), ('NDCG@20', 0.8518088459968567)])
1 stage (test) OrderedDict([('Precision@1', 0.8939051628112793), ('Precision@5', 0.8860311508178711), ('Precision@10', 0.8833186030387878), ('Recall@1', 0.003023584373295307), ('Recall@5', 0.015060748904943466), ('Recall@10', 0.030287474393844604), ('NDCG@5', 0.8870344161987305), ('NDCG@10', 0.8848085403442383), ('NDCG@20', 0.8842055201530457)])
2 stage (test) OrderedDict([('Precision@1', 0.9709054231643677), ('Precision@5', 0.949586033821106), ('Precision@10', 0.9382994174957275), ('Recall@1', 0.0073165870271623135), ('Recall@5', 0.02467793971300125), ('Recall@10', 0.04251282662153244), ('NDCG@5', 0.9548905491828918), ('NDCG@10', 0.9467594623565674), ('NDCG@20', 0.9288665652275085)])
---epoch 12---
1 stage 0.8357616066932678
2 stage 0.9385761618614197
1 stage (val) OrderedDict([('Precision@1', 0.7688727974891663), ('Precision@5', 0.7738365530967712), ('Precision@10', 0.7722853422164917), ('Recall@1', 0.002532533835619688), ('Recall@5', 0.01389816403388977), ('Recall@10', 0.028517844155430794), ('NDCG@5', 0.7726624011993408), ('NDCG@10', 0.7721626162528992), ('NDCG@20', 0.7710179686546326)])
2 stage (val) OrderedDict([('Precision@1', 0.9312306046485901), ('Precision@5', 0.8893485069274902), ('Precision@10', 0.8653566241264343), ('Recall@1', 0.013489209115505219), ('Recall@5', 0.03542754054069519), ('Recall@10', 0.05412572622299194), ('NDCG@5', 0.9000642895698547), ('NDCG@10', 0.8836491703987122), ('NDCG@20', 0.8513972163200378)])
1 stage (test) OrderedDict([('Precision@1', 0.8931527733802795), ('Precision@5', 0.8858307003974915), ('Precision@10', 0.8832935690879822), ('Recall@1', 0.003019903087988496), ('Recall@5', 0.015028968453407288), ('Recall@10', 0.030282167717814445), ('NDCG@5', 0.886849045753479), ('NDCG@10', 0.8847469687461853), ('NDCG@20', 0.8832032680511475)])
2 stage (test) OrderedDict([('Precision@1', 0.9701529741287231), ('Precision@5', 0.9494857788085938), ('Precision@10', 0.9382240772247314), ('Recall@1', 0.007107383105903864), ('Recall@5', 0.024620026350021362), ('Recall@10', 0.04242135211825371), ('NDCG@5', 0.9546770453453064), ('NDCG@10', 0.9465430974960327), ('NDCG@20', 0.9285589456558228)])
---epoch 13---
1 stage 0.8362582921981812
2 stage 0.937748372554779
1 stage (val) OrderedDict([('Precision@1', 0.7709410786628723), ('Precision@5', 0.7739399671554565), ('Precision@10', 0.7720269560813904), ('Recall@1', 0.0025725809391587973), ('Recall@5', 0.013920770026743412), ('Recall@10', 0.028608163818717003), ('NDCG@5', 0.77310711145401), ('NDCG@10', 0.7722665071487427), ('NDCG@20', 0.7705519795417786)])
2 stage (val) OrderedDict([('Precision@1', 0.9296793937683105), ('Precision@5', 0.8893485069274902), ('Precision@10', 0.8653048276901245), ('Recall@1', 0.013278146274387836), ('Recall@5', 0.03546256572008133), ('Recall@10', 0.054152097553014755), ('NDCG@5', 0.8998194932937622), ('NDCG@10', 0.8834453225135803), ('NDCG@20', 0.8509284257888794)])
1 stage (test) OrderedDict([('Precision@1', 0.8929019570350647), ('Precision@5', 0.8853790760040283), ('Precision@10', 0.8832684755325317), ('Recall@1', 0.0030202772468328476), ('Recall@5', 0.015010001137852669), ('Recall@10', 0.030313612893223763), ('NDCG@5', 0.8865785002708435), ('NDCG@10', 0.8847340941429138), ('NDCG@20', 0.8825224041938782)])
2 stage (test) OrderedDict([('Precision@1', 0.9696513414382935), ('Precision@5', 0.9491847157478333), ('Precision@10', 0.9378730654716492), ('Recall@1', 0.007022056728601456), ('Recall@5', 0.024508126080036163), ('Recall@10', 0.0422583743929863), ('NDCG@5', 0.9543265700340271), ('NDCG@10', 0.9461403489112854), ('NDCG@20', 0.9281177520751953)])
---epoch 14---
1 stage 0.8352649211883545
2 stage 0.937748372554779
1 stage (val) OrderedDict([('Precision@1', 0.7699069380760193), ('Precision@5', 0.7740433216094971), ('Precision@10', 0.7716652154922485), ('Recall@1', 0.0025672533083707094), ('Recall@5', 0.013907205313444138), ('Recall@10', 0.028547627851366997), ('NDCG@5', 0.7730266451835632), ('NDCG@10', 0.7719103097915649), ('NDCG@20', 0.7697432637214661)])
2 stage (val) OrderedDict([('Precision@1', 0.9286453127861023), ('Precision@5', 0.8890382647514343), ('Precision@10', 0.8652012944221497), ('Recall@1', 0.012992068193852901), ('Recall@5', 0.03513404354453087), ('Recall@10', 0.05389030650258064), ('NDCG@5', 0.8995911478996277), ('NDCG@10', 0.8832032084465027), ('NDCG@20', 0.8503848314285278)])
1 stage (test) OrderedDict([('Precision@1', 0.8918986916542053), ('Precision@5', 0.8851282596588135), ('Precision@10', 0.8826413154602051), ('Recall@1', 0.003015252063050866), ('Recall@5', 0.015008385293185711), ('Recall@10', 0.030310826376080513), ('NDCG@5', 0.8863389492034912), ('NDCG@10', 0.8842962384223938), ('NDCG@20', 0.8815882802009583)])
2 stage (test) OrderedDict([('Precision@1', 0.9701529741287231), ('Precision@5', 0.9492349028587341), ('Precision@10', 0.9378228783607483), ('Recall@1', 0.006919103674590588), ('Recall@5', 0.024281606078147888), ('Recall@10', 0.04200495406985283), ('NDCG@5', 0.9543092846870422), ('NDCG@10', 0.9460137486457825), ('NDCG@20', 0.9279131889343262)])
---epoch 15---
1 stage 0.8342715501785278
2 stage 0.9382450580596924
1 stage (val) OrderedDict([('Precision@1', 0.7688727974891663), ('Precision@5', 0.7741466164588928), ('Precision@10', 0.7720270752906799), ('Recall@1', 0.0025641624815762043), ('Recall@5', 0.013893092051148415), ('Recall@10', 0.028611961752176285), ('NDCG@5', 0.7728968262672424), ('NDCG@10', 0.7719386219978333), ('NDCG@20', 0.7689577341079712)])
2 stage (val) OrderedDict([('Precision@1', 0.9301964640617371), ('Precision@5', 0.8893486857414246), ('Precision@10', 0.8648910522460938), ('Recall@1', 0.012969724833965302), ('Recall@5', 0.035027049481868744), ('Recall@10', 0.0536569282412529), ('NDCG@5', 0.8999989032745361), ('NDCG@10', 0.8830557465553284), ('NDCG@20', 0.8499181270599365)])
1 stage (test) OrderedDict([('Precision@1', 0.890895426273346), ('Precision@5', 0.885128378868103), ('Precision@10', 0.8826413154602051), ('Recall@1', 0.0030101861339062452), ('Recall@5', 0.014987428672611713), ('Recall@10', 0.030330732464790344), ('NDCG@5', 0.8862097859382629), ('NDCG@10', 0.8841873407363892), ('NDCG@20', 0.8804370760917664)])
2 stage (test) OrderedDict([('Precision@1', 0.9701529741287231), ('Precision@5', 0.9493853449821472), ('Precision@10', 0.9377727508544922), ('Recall@1', 0.006855727173388004), ('Recall@5', 0.0241836067289114), ('Recall@10', 0.04189404845237732), ('NDCG@5', 0.9543688297271729), ('NDCG@10', 0.9459018707275391), ('NDCG@20', 0.9275990128517151)])
---epoch 16---
1 stage 0.8342715501785278
2 stage 0.939238429069519
1 stage (val) OrderedDict([('Precision@1', 0.7699069380760193), ('Precision@5', 0.7728022933006287), ('Precision@10', 0.7725440263748169), ('Recall@1', 0.002587593160569668), ('Recall@5', 0.01379038393497467), ('Recall@10', 0.02874572202563286), ('NDCG@5', 0.7722145915031433), ('NDCG@10', 0.7722715139389038), ('NDCG@20', 0.7682958245277405)])
2 stage (val) OrderedDict([('Precision@1', 0.9322647452354431), ('Precision@5', 0.8898658752441406), ('Precision@10', 0.8647358417510986), ('Recall@1', 0.01313948817551136), ('Recall@5', 0.03528093919157982), ('Recall@10', 0.053822338581085205), ('NDCG@5', 0.9008933305740356), ('NDCG@10', 0.8833855390548706), ('NDCG@20', 0.8500461578369141)])
1 stage (test) OrderedDict([('Precision@1', 0.8903937935829163), ('Precision@5', 0.8849779367446899), ('Precision@10', 0.8826160430908203), ('Recall@1', 0.0030037390533834696), ('Recall@5', 0.014980170875787735), ('Recall@10', 0.03035588748753071), ('NDCG@5', 0.8861247897148132), ('NDCG@10', 0.8841509819030762), ('NDCG@20', 0.8795574903488159)])
2 stage (test) OrderedDict([('Precision@1', 0.9706546068191528), ('Precision@5', 0.9496863484382629), ('Precision@10', 0.9377727508544922), ('Recall@1', 0.006977349519729614), ('Recall@5', 0.024342140182852745), ('Recall@10', 0.0420152023434639), ('NDCG@5', 0.9546906352043152), ('NDCG@10', 0.9460608959197998), ('NDCG@20', 0.9275720715522766)])
---epoch 17---
1 stage 0.8339403867721558
2 stage 0.9387417435646057
1 stage (val) OrderedDict([('Precision@1', 0.7688727974891663), ('Precision@5', 0.7732157707214355), ('Precision@10', 0.7721819281578064), ('Recall@1', 0.0025853486731648445), ('Recall@5', 0.013845651410520077), ('Recall@10', 0.028628256171941757), ('NDCG@5', 0.7722429633140564), ('NDCG@10', 0.7718576192855835), ('NDCG@20', 0.767686665058136)])
2 stage (val) OrderedDict([('Precision@1', 0.9312306046485901), ('Precision@5', 0.8897624015808105), ('Precision@10', 0.864425778388977), ('Recall@1', 0.013013952411711216), ('Recall@5', 0.035018254071474075), ('Recall@10', 0.05353393778204918), ('NDCG@5', 0.9006258249282837), ('NDCG@10', 0.8829480409622192), ('NDCG@20', 0.8497097492218018)])
1 stage (test) OrderedDict([('Precision@1', 0.8903937935829163), ('Precision@5', 0.8849778175354004), ('Precision@10', 0.8823150396347046), ('Recall@1', 0.0030055013485252857), ('Recall@5', 0.014995132572948933), ('Recall@10', 0.030364053323864937), ('NDCG@5', 0.8861544132232666), ('NDCG@10', 0.8839383721351624), ('NDCG@20', 0.8786713480949402)])
2 stage (test) OrderedDict([('Precision@1', 0.970403790473938), ('Precision@5', 0.9499371647834778), ('Precision@10', 0.9376974701881409), ('Recall@1', 0.006946822162717581), ('Recall@5', 0.024365242570638657), ('Recall@10', 0.04201309755444527), ('NDCG@5', 0.9548534750938416), ('NDCG@10', 0.9460048079490662), ('NDCG@20', 0.9273778200149536)])
---epoch 18---
1 stage 0.8332781791687012
2 stage 0.9384106397628784
1 stage (val) OrderedDict([('Precision@1', 0.7683557271957397), ('Precision@5', 0.7734225392341614), ('Precision@10', 0.7714068293571472), ('Recall@1', 0.0025810804218053818), ('Recall@5', 0.013942412100732327), ('Recall@10', 0.02855859324336052), ('NDCG@5', 0.7723387479782104), ('NDCG@10', 0.7713356614112854), ('NDCG@20', 0.767216145992279)])
2 stage (val) OrderedDict([('Precision@1', 0.9301964640617371), ('Precision@5', 0.889141857624054), ('Precision@10', 0.8643222451210022), ('Recall@1', 0.01304357685148716), ('Recall@5', 0.034884266555309296), ('Recall@10', 0.053411055356264114), ('NDCG@5', 0.9000440239906311), ('NDCG@10', 0.8827939033508301), ('NDCG@20', 0.8493320941925049)])
1 stage (test) OrderedDict([('Precision@1', 0.8896413445472717), ('Precision@5', 0.8848274350166321), ('Precision@10', 0.8820641040802002), ('Recall@1', 0.0029982151463627815), ('Recall@5', 0.015002566389739513), ('Recall@10', 0.03033376671373844), ('NDCG@5', 0.8859151601791382), ('NDCG@10', 0.883664071559906), ('NDCG@20', 0.8777598142623901)])
2 stage (test) OrderedDict([('Precision@1', 0.970403790473938), ('Precision@5', 0.949836790561676), ('Precision@10', 0.9376975297927856), ('Recall@1', 0.006989224348217249), ('Recall@5', 0.024378934875130653), ('Recall@10', 0.042055051773786545), ('NDCG@5', 0.9547573924064636), ('NDCG@10', 0.946016252040863), ('NDCG@20', 0.9272603392601013)])
---epoch 19---
1 stage 0.8344370722770691
2 stage 0.937417209148407
1 stage (val) OrderedDict([('Precision@1', 0.7724922299385071), ('Precision@5', 0.7734224796295166), ('Precision@10', 0.7712516784667969), ('Recall@1', 0.0026290433015674353), ('Recall@5', 0.013950219377875328), ('Recall@10', 0.028614703565835953), ('NDCG@5', 0.7729315161705017), ('NDCG@10', 0.7716161608695984), ('NDCG@20', 0.7671958208084106)])
2 stage (val) OrderedDict([('Precision@1', 0.9281282424926758), ('Precision@5', 0.8886248469352722), ('Precision@10', 0.8638569712638855), ('Recall@1', 0.01269526220858097), ('Recall@5', 0.03449012339115143), ('Recall@10', 0.05301033332943916), ('NDCG@5', 0.8991745114326477), ('NDCG@10', 0.8819308876991272), ('NDCG@20', 0.8481321334838867)])
1 stage (test) OrderedDict([('Precision@1', 0.8893905282020569), ('Precision@5', 0.8843759894371033), ('Precision@10', 0.8814369440078735), ('Recall@1', 0.0030090906657278538), ('Recall@5', 0.014989291317760944), ('Recall@10', 0.030279411002993584), ('NDCG@5', 0.8855165243148804), ('NDCG@10', 0.8831601738929749), ('NDCG@20', 0.8770545125007629)])
2 stage (test) OrderedDict([('Precision@1', 0.9699021577835083), ('Precision@5', 0.9497867226600647), ('Precision@10', 0.9374968409538269), ('Recall@1', 0.006969019304960966), ('Recall@5', 0.024379633367061615), ('Recall@10', 0.04202014207839966), ('NDCG@5', 0.9546409845352173), ('NDCG@10', 0.9458295702934265), ('NDCG@20', 0.9270906448364258)])
print("Best validation epoch: {}".format(best_epoch))
print("Best validation stage results\n 1 stage: {}\n 2 stage: {}".format(
val_results[best_epoch][0], val_results[best_epoch][1]))
print("Best test results\n 1 stage: {}\n 2 stage: {}".format(
test_results[best_epoch][0], test_results[best_epoch][1]))
Best validation epoch: 6
Best validation stage results
1 stage: OrderedDict([('Precision@1', 0.7652533650398254), ('Precision@5', 0.7777659296989441), ('Precision@10', 0.7713546752929688), ('Recall@1', 0.002462433883920312), ('Recall@5', 0.014112057164311409), ('Recall@10', 0.02813573367893696), ('NDCG@5', 0.7751555442810059), ('NDCG@10', 0.7717844247817993), ('NDCG@20', 0.7759582996368408)])
2 stage: OrderedDict([('Precision@1', 0.9353671073913574), ('Precision@5', 0.8887278437614441), ('Precision@10', 0.866390585899353), ('Recall@1', 0.013995282351970673), ('Recall@5', 0.035590916872024536), ('Recall@10', 0.05474210903048515), ('NDCG@5', 0.9002852439880371), ('NDCG@10', 0.8846437931060791), ('NDCG@20', 0.8533338904380798)])
Best test results
1 stage: OrderedDict([('Precision@1', 0.8931527733802795), ('Precision@5', 0.8867837190628052), ('Precision@10', 0.8830179572105408), ('Recall@1', 0.0030013115610927343), ('Recall@5', 0.01514824852347374), ('Recall@10', 0.03022931143641472), ('NDCG@5', 0.8876431584358215), ('NDCG@10', 0.8846896886825562), ('NDCG@20', 0.886621356010437)])
2 stage: OrderedDict([('Precision@1', 0.9729119539260864), ('Precision@5', 0.9496863484382629), ('Precision@10', 0.9388262033462524), ('Recall@1', 0.007614111993461847), ('Recall@5', 0.024715635925531387), ('Recall@10', 0.04267028719186783), ('NDCG@5', 0.9553412199020386), ('NDCG@10', 0.9473593235015869), ('NDCG@20', 0.9304744601249695)])
pickle.dump((best_epoch, val_results, test_results),
open("{}-a{}_{}.pkl".format(
args.loss_type.split("_")[1], args.alpha, args.seed), "wb"))
!apt-get install tree
!tree --du -h
.
├── [ 20K] ce-a0.001_0.pkl
├── [651M] ml-1m
│ ├── [626M] full_impression_feats.pt
│ ├── [463K] logging_policy.pt
│ ├── [167K] movies.dat
│ ├── [463K] ranker.pt
│ ├── [ 23M] ratings.dat
│ ├── [5.4K] README
│ ├── [502K] simulator.pt
│ └── [131K] users.dat
├── [5.6M] ml-1m.zip
└── [ 54M] sample_data
├── [1.7K] anscombe.json
├── [294K] california_housing_test.csv
├── [1.6M] california_housing_train.csv
├── [ 17M] mnist_test.csv
├── [ 35M] mnist_train_small.csv
└── [ 930] README.md
711M used in 2 directories, 16 files
Experimental results¶
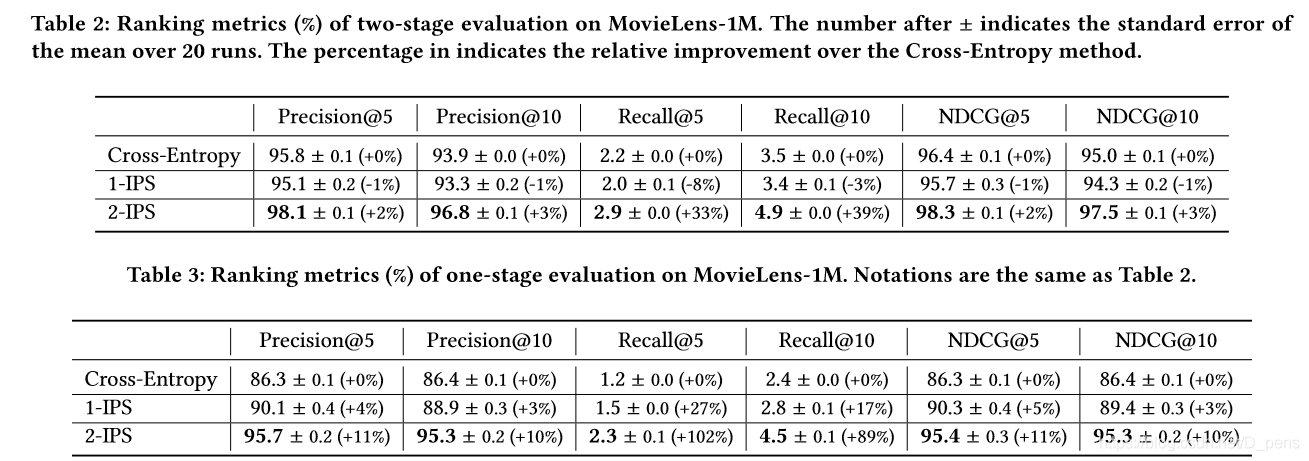
Conclusion¶
The results of 2-IPS method in both evaluations are better than 1-IPS and cross-entropy.
1-IPS performs better than the cross-entropy method in one-stage evaluation, and performs worse than the cross-entropy method in two-stage evaluation, indicating that only improving the performance of a part of the system may not necessarily improve the performance of the entire system.