FrozenLake using Q-Learning¶
Create the Q-table and initialize it 🗄️¶
Now, we’ll create our Q-table, to know how much rows (states) and columns (actions) we need, we need to calculate the action_size and the state_size OpenAI Gym provides us a way to do that: env.action_space.n and env.observation_space.n
action_size = env.action_space.n
state_size = env.observation_space.n
# Create our Q table with state_size rows and action_size columns (64x4)
qtable = np.zeros((state_size, action_size))
print(qtable)
[[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]]
Create the hyperparameters ⚙️¶
Here, we’ll specify the hyperparameters
total_episodes = 20000 # Total episodes
learning_rate = 0.7 # Learning rate
max_steps = 99 # Max steps per episode
gamma = 0.95 # Discounting rate
# Exploration parameters
epsilon = 1.0 # Exploration rate
max_epsilon = 1.0 # Exploration probability at start
min_epsilon = 0.01 # Minimum exploration probability
decay_rate = 0.005 # Exponential decay rate for exploration prob
The Q learning algorithm 🧠¶
Now we implement the Q learning algorithm:
# List of rewards
rewards = []
# 2 For life or until learning is stopped
for episode in range(total_episodes):
# Reset the environment
state = env.reset()
step = 0
done = False
total_rewards = 0
for step in range(max_steps):
# 3. Choose an action a in the current world state (s)
## First we randomize a number
exp_exp_tradeoff = random.uniform(0, 1)
## If this number > greater than epsilon --> exploitation (taking the biggest Q value for this state)
if exp_exp_tradeoff > epsilon:
action = np.argmax(qtable[state,:])
#print(exp_exp_tradeoff, "action", action)
# Else doing a random choice --> exploration
else:
action = env.action_space.sample()
#print("action random", action)
# Take the action (a) and observe the outcome state(s') and reward (r)
new_state, reward, done, info = env.step(action)
# Update Q(s,a):= Q(s,a) + lr [R(s,a) + gamma * max Q(s',a') - Q(s,a)]
# qtable[new_state,:] : all the actions we can take from new state
qtable[state, action] = qtable[state, action] + learning_rate * (reward + gamma * np.max(qtable[new_state, :]) - qtable[state, action])
total_rewards += reward
# Our new state is state
state = new_state
# If done (if we're dead) : finish episode
if done == True:
break
# Reduce epsilon (because we need less and less exploration)
epsilon = min_epsilon + (max_epsilon - min_epsilon)*np.exp(-decay_rate*episode)
rewards.append(total_rewards)
print ("Score over time: " + str(sum(rewards)/total_episodes))
print(qtable)
Score over time: 0.5091
[[9.01507329e-02 8.17424478e-02 6.39680351e-02 6.86630922e-02]
[2.62376785e-02 1.09112058e-02 8.89889825e-03 7.77301606e-02]
[2.64740266e-02 1.47344615e-02 2.38915905e-02 2.52383378e-02]
[1.27543068e-03 2.20765613e-03 3.16416215e-03 2.46832992e-02]
[9.79766765e-02 4.04794442e-02 6.38497041e-02 3.75700055e-04]
[0.00000000e+00 0.00000000e+00 0.00000000e+00 0.00000000e+00]
[1.10458406e-03 2.96899943e-02 6.25840861e-04 1.48050755e-04]
[0.00000000e+00 0.00000000e+00 0.00000000e+00 0.00000000e+00]
[4.09218831e-02 4.63296542e-02 4.42937432e-02 1.55235475e-01]
[1.05014686e-02 1.58532972e-01 3.70542973e-03 4.56743994e-02]
[6.42722208e-01 7.37759086e-03 1.53679103e-03 2.50722701e-02]
[0.00000000e+00 0.00000000e+00 0.00000000e+00 0.00000000e+00]
[0.00000000e+00 0.00000000e+00 0.00000000e+00 0.00000000e+00]
[8.74653767e-02 2.29993112e-02 7.76083629e-01 3.36186831e-01]
[1.68609535e-01 9.43051365e-01 3.12274680e-01 3.48405559e-01]
[0.00000000e+00 0.00000000e+00 0.00000000e+00 0.00000000e+00]]
Use our Q-table to play FrozenLake ! 👾¶
After 10 000 episodes, our Q-table can be used as a “cheatsheet” to play FrozenLake”
By running this cell you can see our agent playing FrozenLake.
env.reset()
for episode in range(5):
state = env.reset()
step = 0
done = False
print("****************************************************")
print("EPISODE ", episode)
for step in range(max_steps):
# Take the action (index) that have the maximum expected future reward given that state
action = np.argmax(qtable[state,:])
new_state, reward, done, info = env.step(action)
if done:
# Here, we decide to only print the last state (to see if our agent is on the goal or fall into an hole)
env.render()
if new_state == 15:
print("We reached our Goal 🏆")
else:
print("We fell into a hole ☠️")
# We print the number of step it took.
print("Number of steps", step)
break
state = new_state
env.close()
****************************************************
EPISODE 0
(Down)
SFFF
FHFH
FFFH
HFFG
We reached our Goal 🏆
Number of steps 20
****************************************************
EPISODE 1
(Down)
SFFF
FHFH
FFFH
HFFG
We reached our Goal 🏆
Number of steps 57
****************************************************
EPISODE 2
(Down)
SFFF
FHFH
FFFH
HFFG
We fell into a hole ☠️
Number of steps 87
****************************************************
EPISODE 3
(Down)
SFFF
FHFH
FFFH
HFFG
We reached our Goal 🏆
Number of steps 16
****************************************************
EPISODE 4
(Down)
SFFF
FHFH
FFFH
HFFG
We reached our Goal 🏆
Number of steps 38
PyTorch version¶
import gym
import collections
from torch.utils.tensorboard import SummaryWriter
ENV_NAME = "FrozenLake-v0"
GAMMA = 0.9
ALPHA = 0.2
TEST_EPISODES = 20
class Agent:
def __init__(self):
self.env = gym.make(ENV_NAME)
self.state = self.env.reset()
self.values = collections.defaultdict(float)
def sample_env(self):
action = self.env.action_space.sample()
old_state = self.state
new_state, reward, is_done, _ = self.env.step(action)
self.state = self.env.reset() if is_done else new_state
return old_state, action, reward, new_state
def best_value_and_action(self, state):
best_value, best_action = None, None
for action in range(self.env.action_space.n):
action_value = self.values[(state, action)]
if best_value is None or best_value < action_value:
best_value = action_value
best_action = action
return best_value, best_action
def value_update(self, s, a, r, next_s):
best_v, _ = self.best_value_and_action(next_s)
new_v = r + GAMMA * best_v
old_v = self.values[(s, a)]
self.values[(s, a)] = old_v * (1-ALPHA) + new_v * ALPHA
def play_episode(self, env):
total_reward = 0.0
state = env.reset()
while True:
_, action = self.best_value_and_action(state)
new_state, reward, is_done, _ = env.step(action)
total_reward += reward
if is_done:
break
state = new_state
return total_reward
if __name__ == "__main__":
test_env = gym.make(ENV_NAME)
agent = Agent()
writer = SummaryWriter(comment="-q-learning")
iter_no = 0
best_reward = 0.0
while True:
iter_no += 1
s, a, r, next_s = agent.sample_env()
agent.value_update(s, a, r, next_s)
reward = 0.0
for _ in range(TEST_EPISODES):
reward += agent.play_episode(test_env)
reward /= TEST_EPISODES
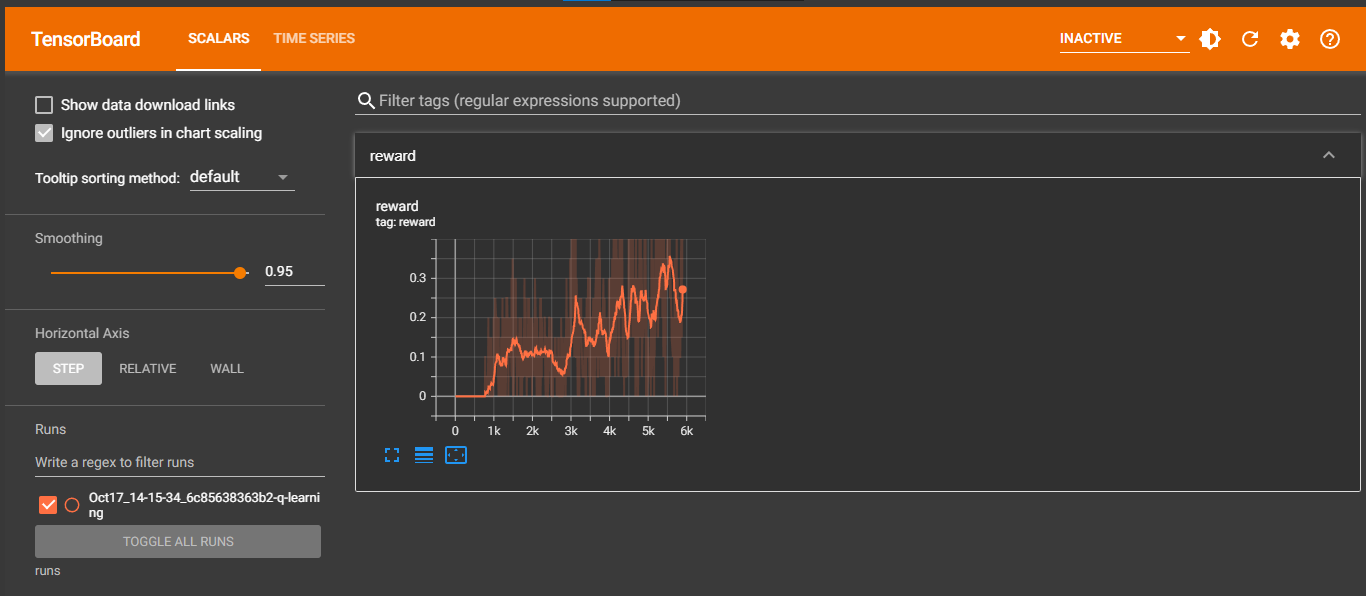
writer.add_scalar("reward", reward, iter_no)
if reward > best_reward:
print("Best reward updated %.3f -> %.3f" % (
best_reward, reward))
best_reward = reward
if reward > 0.80:
print("Solved in %d iterations!" % iter_no)
break
writer.close()
Best reward updated 0.000 -> 0.050
Best reward updated 0.050 -> 0.150
Best reward updated 0.150 -> 0.200
Best reward updated 0.200 -> 0.250
Best reward updated 0.250 -> 0.300
Best reward updated 0.300 -> 0.350
Best reward updated 0.350 -> 0.400
Best reward updated 0.400 -> 0.450
Best reward updated 0.450 -> 0.550
Best reward updated 0.550 -> 0.600
Best reward updated 0.600 -> 0.650
Best reward updated 0.650 -> 0.700
Best reward updated 0.700 -> 0.800
Best reward updated 0.800 -> 0.850
Solved in 5895 iterations!
%load_ext tensorboard
%tensorboard --logdir runs