Recsim Catalyst¶
We will create a recommender bot by neural networks, and use RL methods to train it.
Abstract¶
We propose RecSim, a configurable platform for authoring simulation environments for recommender systems (RSs) that naturally supports sequential interaction with users. RecSim allows the creation of new environments that reflect particular aspects of user behavior and item structure at a level of abstraction well-suited to pushing the limits of current reinforcement learning (RL) and RS techniques in sequential interactive recommendation problems. Environments can be easily configured that vary assumptions about: user preferences and item familiarity; user latent state and its dynamics; and choice models and other user response behavior. We outline how RecSim offers value to RL and RS researchers and practitioners, and how it can serve as a vehicle for academic-industrial collaboration.
https://arxiv.org/abs/1909.04847
RecSim is a configurable platform for authoring simulation environments for recommender systems (RSs) that naturally supports sequential interaction with users. RecSim allows the creation of new environments that reflect particular aspects of user behavior and item structure at a level of abstraction well-suited to pushing the limits of current reinforcement learning (RL) and RS techniques in sequential interactive recommendation problems. Environments can be easily configured that vary assumptions about: user preferences and item familiarity; user latent state and its dynamics; and choice models and other user response behavior. We outline how RecSim offers value to RL and RS researchers and practitioners, and how it can serve as a vehicle for academic-industrial collaboration. For a detailed description of the RecSim architecture please read Ie et al. Please cite the paper if you use the code from this repository in your work.
RecSim simulates a recommender agent’s interaction with an environment where the agent interacts by doing some recommendations to users. Both the user and the subject of recommendations are simulated. The simulations are done based on popularity, interests, demographics, frequency and other traits. When an RL agent recommends something to a user, then depending on the user’s acceptance, few traits are scored high. This still sounds like a typical recommendation system. However, with RecSim, a developer can author these traits. The features in a user choice model can be made more customised as the agent gets rewarded for making the right recommendation.
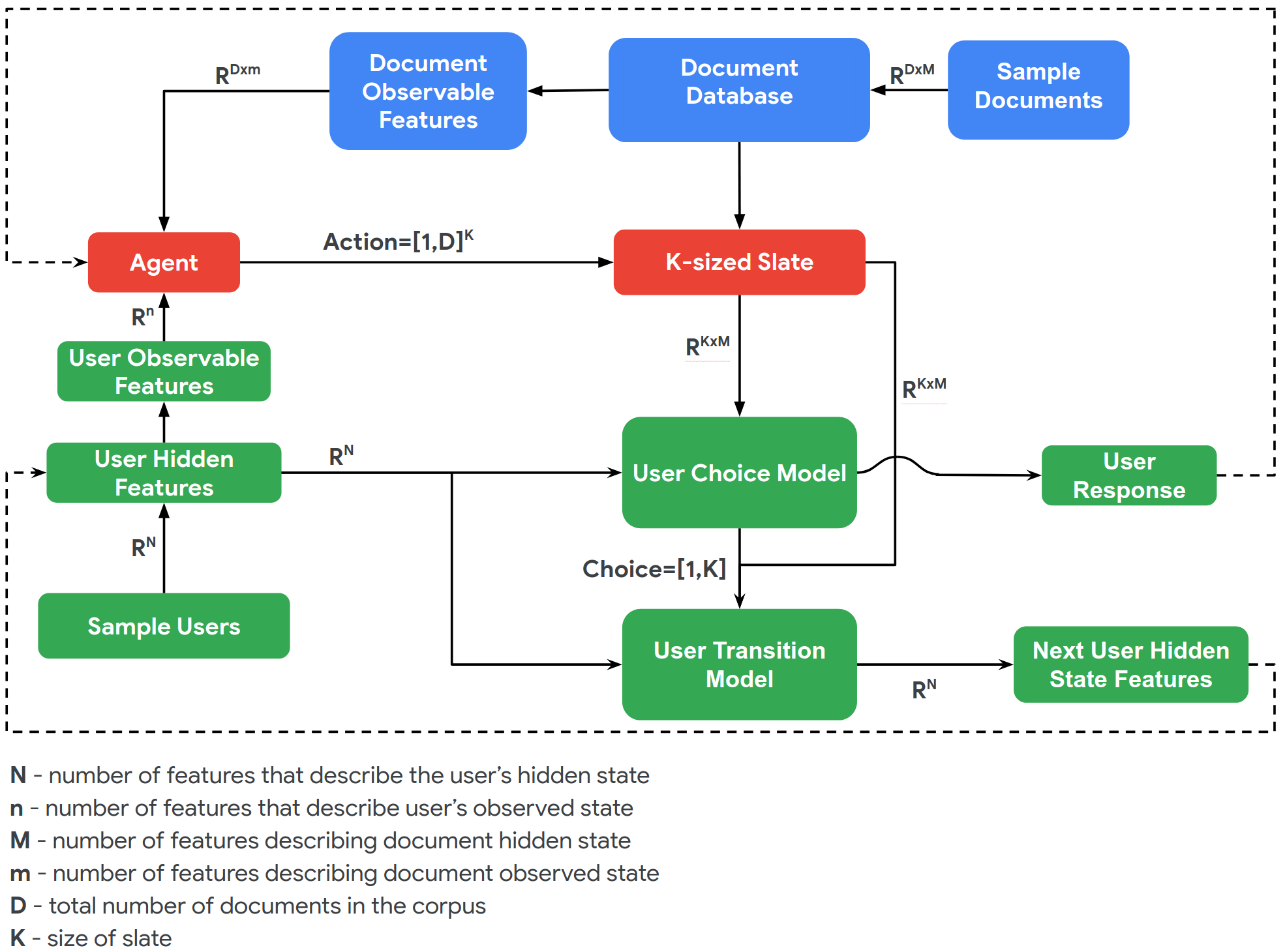
Green and blue boxes show the environment. We need to implement special classes, User and Document. Our bot(“Agent”) have to choose from several documents the most relevant for the user. The user can move to the offered document if he accepts it, to random document overwise or stay on the current document.
Recsim is a configurable simulation platform for recommender systems make by Google, which utilized the document and user database directly. We can break Recsim into two parts,
The environment consists of a user model, a document (item) model and a user-choice model. The user model samples users from a prior distribution of observable and latent user features; the document model samples items from a prior over observable and latent document features; and the user-choice model determines the user’s response, which is dependent on observable document features, observable and latent user features.
The SlateQ Simulation Environment, which uses the SlateQ Algorithm to return a slate of items back to the simulation environment.
Unlike virtual Taobao, Recsim has a concrete representation of items, and the actions returned by the reinforcement learning agent can be directly associated with items. However, the user model and item model of Recsim are too simple, and without sufficient data support, the prior probability distribution for generating simulated users and virtual items is difficult to be accurate.
Setup¶
!pip install -Uq catalyst gym recsim
from collections import deque, namedtuple
import random
import numpy as np
import gym
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from catalyst import dl, utils
from gym import spaces
from recsim import document, user
from recsim.choice_model import AbstractChoiceModel
from recsim.simulator import recsim_gym, environment
Params¶
device = utils.get_device()
utils.set_global_seed(42)
DOC_NUM = 10
EMB_SIZE = 4
P_EXIT_ACCEPTED = 0.1
P_EXIT_NOT_ACCEPTED = 0.2
# let's define a matrix W for simulation of users' respose
# (based on the section 7.3 of the paper https://arxiv.org/pdf/1512.07679.pdf)
# W_ij defines the probability that a user will accept recommendation j
# given that he is consuming item i at the moment
W = (np.ones((DOC_NUM, DOC_NUM)) - np.eye(DOC_NUM)) * \
np.random.uniform(0.0, P_EXIT_NOT_ACCEPTED, (DOC_NUM, DOC_NUM)) + \
np.diag(np.random.uniform(1.0 - P_EXIT_ACCEPTED, 1.0, DOC_NUM))
W = W[:, np.random.permutation(DOC_NUM)]
Document Model¶
class Document(document.AbstractDocument):
def __init__(self, doc_id):
super().__init__(doc_id)
def create_observation(self):
return (self._doc_id,)
@staticmethod
def observation_space():
return spaces.Discrete(DOC_NUM)
def __str__(self):
return "Document #{}".format(self._doc_id)
class DocumentSampler(document.AbstractDocumentSampler):
def __init__(self, doc_ctor=Document):
super().__init__(doc_ctor)
self._doc_count = 0
def sample_document(self):
doc = self._doc_ctor(self._doc_count % DOC_NUM)
self._doc_count += 1
return doc
User Model¶
class UserState(user.AbstractUserState):
def __init__(self, user_id, current, active_session=True):
self.user_id = user_id
self.current = current
self.active_session = active_session
def create_observation(self):
return (self.current,)
def __str__(self):
return "User #{}".format(self.user_id)
@staticmethod
def observation_space():
return spaces.Discrete(DOC_NUM)
def score_document(self, doc_obs):
return W[self.current, doc_obs[0]]
class StaticUserSampler(user.AbstractUserSampler):
def __init__(self, user_ctor=UserState):
super().__init__(user_ctor)
self.user_count = 0
def sample_user(self):
self.user_count += 1
sampled_user = self._user_ctor(
self.user_count, np.random.randint(DOC_NUM))
return sampled_user
class Response(user.AbstractResponse):
def __init__(self, accept=False):
self.accept = accept
def create_observation(self):
return (int(self.accept),)
@classmethod
def response_space(cls):
return spaces.Discrete(2)
class UserChoiceModel(AbstractChoiceModel):
def __init__(self):
super().__init__()
self._score_no_click = P_EXIT_ACCEPTED
def score_documents(self, user_state, doc_obs):
if len(doc_obs) != 1:
raise ValueError(
"Expecting single document, but got: {}".format(doc_obs))
self._scores = np.array(
[user_state.score_document(doc) for doc in doc_obs])
def choose_item(self):
if np.random.random() < self.scores[0]:
return 0
class UserModel(user.AbstractUserModel):
def __init__(self):
super().__init__(Response, StaticUserSampler(), 1)
self.choice_model = UserChoiceModel()
def simulate_response(self, slate_documents):
if len(slate_documents) != 1:
raise ValueError("Expecting single document, but got: {}".format(
slate_documents))
responses = [self._response_model_ctor() for _ in slate_documents]
self.choice_model.score_documents(
self._user_state,
[doc.create_observation() for doc in slate_documents]
)
selected_index = self.choice_model.choose_item()
if selected_index is not None:
responses[selected_index].accept = True
return responses
def update_state(self, slate_documents, responses):
if len(slate_documents) != 1:
raise ValueError(
f"Expecting single document, but got: {slate_documents}"
)
response = responses[0]
doc = slate_documents[0]
if response.accept:
self._user_state.current = doc.doc_id()
self._user_state.active_session = bool(
np.random.binomial(1, 1 - P_EXIT_ACCEPTED))
else:
self._user_state.current = np.random.choice(DOC_NUM)
self._user_state.active_session = bool(
np.random.binomial(1, 1 - P_EXIT_NOT_ACCEPTED))
def is_terminal(self):
"""Returns a boolean indicating if the session is over."""
return not self._user_state.active_session
def clicked_reward(responses):
reward = 0.0
for response in responses:
if response.accept:
reward += 1
return reward
RecSim Environment¶
def make_env():
env = recsim_gym.RecSimGymEnv(
environment.Environment(
UserModel(),
DocumentSampler(),
DOC_NUM,
1,
resample_documents=False
),
clicked_reward
)
return env
Actor-Critic Policy¶
The actor is a simple NN, that generate embedding action vector based on current state. The critic model is more complicated. In our implementation, we need action embeddings. Our actions is a picking a document. So, we just need a embedding vector for each document. They can be trained as well as a critic model. And we have to implement choosing process by choosing top-k variants and calculate q-value on them.
from catalyst.contrib.nn import Normalize
inner_fn = utils.get_optimal_inner_init(nn.ReLU)
outer_fn = utils.outer_init
class ActorModel(nn.Module):
def __init__(self, hidden=64, doc_num=10, doc_emb_size=4):
super().__init__()
self.actor = nn.Sequential(
nn.Linear(doc_num, hidden),
nn.ReLU(),
nn.Linear(hidden, hidden),
nn.ReLU(),
)
self.head = nn.Sequential(
nn.Linear(hidden, doc_emb_size),
Normalize()
)
self.actor.apply(inner_fn)
self.head.apply(outer_fn)
self.doc_num = doc_num
self.doc_emb_size = doc_emb_size
def forward(self, states):
return self.head(self.actor(states))
class CriticModel(nn.Module):
def __init__(self, hidden=64, doc_num=10, doc_emb_size=4):
super().__init__()
self.critic = nn.Sequential(
nn.Linear(doc_num + doc_emb_size, hidden),
nn.ReLU(),
nn.Linear(hidden, hidden),
nn.ReLU(),
)
self.head = nn.Linear(hidden, 1)
self.critic.apply(inner_fn)
self.head.apply(outer_fn)
self.doc_embs = nn.Sequential(
nn.Embedding(doc_num, doc_emb_size),
Normalize()
)
self.doc_num = doc_num
self.doc_emb_size = doc_emb_size
def _generate_input(self, states, proto_actions):
return torch.cat([states, proto_actions], 1)
def forward(self, states, proto_actions):
inputs = self._generate_input(states, proto_actions)
return self.head(self.critic(inputs))
def get_topk(self, states, proto_actions, top_k=1):
# Instead of kNN algorithm we can calculate distance across all of the objects.
dist = torch.cdist(proto_actions, self.doc_embs[0].weight)
indexes = torch.topk(dist, k=top_k, largest=False)[1]
return torch.cat([self.doc_embs(index).unsqueeze(0) for index in indexes]), indexes
def get_best(self, states, proto_actions, top_k=1):
doc_embs, indexes = self.get_topk(states, proto_actions, top_k)
top_k = doc_embs.size(1)
best_values = torch.empty(states.size(0)).to(states.device)
best_indexes = torch.empty(states.size(0)).to(states.device)
for num, (state, actions, idx) in enumerate(zip(states, doc_embs, indexes)):
new_states = state.repeat(top_k, 1)
# for each pair of state and action we use critic to calculate values
values = self(new_states, actions)
best = values.max(0)[1].item()
best_values[num] = values[best]
best_indexes[num] = idx[best]
return best_indexes, best_values
Training¶
import numpy as np
from collections import deque, namedtuple
Transition = namedtuple(
'Transition',
field_names=[
'state',
'action',
'reward',
'done',
'next_state'
]
)
class ReplayBuffer:
def __init__(self, capacity: int):
self.buffer = deque(maxlen=capacity)
def append(self, transition: Transition):
self.buffer.append(transition)
def sample(self, batch_size: int):
indices = np.random.choice(
len(self.buffer),
batch_size,
replace=batch_size > len(self.buffer)
)
states, actions, rewards, dones, next_states = \
zip(*[self.buffer[idx] for idx in indices])
return (
np.array(states, dtype=np.float32),
np.array(actions, dtype=np.int64),
np.array(rewards, dtype=np.float32),
np.array(dones, dtype=np.bool),
np.array(next_states, dtype=np.float32)
)
def __len__(self):
return len(self.buffer)
from torch.utils.data.dataset import IterableDataset
class ReplayDataset(IterableDataset):
def __init__(self, buffer: ReplayBuffer, epoch_size: int = int(1e3)):
self.buffer = buffer
self.epoch_size = epoch_size
def __iter__(self):
states, actions, rewards, dones, next_states = \
self.buffer.sample(self.epoch_size)
for i in range(len(dones)):
yield states[i], actions[i], rewards[i], dones[i], next_states[i]
def __len__(self):
return self.epoch_size
def extract_state(env, state):
user_space = env.observation_space.spaces["user"]
return spaces.flatten(user_space, state["user"])
def get_action(env, actor, critic, state, top_k=10, epsilon=None):
# Our framework is created by PG process and it must be trained with
# a noise added to the actor's output.
# But in our framework it's better to sample action from the enviroment.
state = torch.tensor(state, dtype=torch.float32).to(device).unsqueeze(0)
if epsilon is None or random.random() < epsilon:
proto_action = actor(state)
action = critic.get_best(state, proto_action, top_k)[0]
action = action.detach().cpu().numpy().astype(int)
else:
action = env.action_space.sample()
return action
def generate_session(
env,
actor,
critic,
replay_buffer=None,
epsilon=None,
top_k=10
):
total_reward = 0
s = env.reset()
s = extract_state(env, s)
for t in range(1000):
a = get_action(env, actor, critic, epsilon=epsilon, state=s, top_k=top_k)
next_s, r, done, _ = env.step(a)
next_s = extract_state(env, next_s)
if replay_buffer is not None:
transition = Transition(s, a, r, done, next_s)
replay_buffer.append(transition)
total_reward += r
s = next_s
if done:
break
return total_reward
def generate_sessions(
env,
actor,
critic,
replay_buffer=None,
num_sessions=100,
epsilon=None,
top_k=10
):
sessions_reward = 0
for i_episone in range(num_sessions):
reward = generate_session(
env=env,
actor=actor,
critic=critic,
epsilon=epsilon,
replay_buffer=replay_buffer,
top_k=top_k
)
sessions_reward += reward
sessions_reward /= num_sessions
return sessions_reward
def soft_update(target, source, tau):
"""Updates the target data with smoothing by ``tau``"""
for target_param, param in zip(target.parameters(), source.parameters()):
target_param.data.copy_(
target_param.data * (1.0 - tau) + param.data * tau
)
It’s a standart GameCallback!
class RecSimCallback(dl.Callback):
def __init__(self, order=0, session_period=1):
super().__init__(order=0)
self.session_period = session_period
def on_stage_start(self, runner: dl.IRunner):
generate_sessions(
env=runner.env,
actor=runner.model["origin_actor"],
critic=runner.model["origin_critic"],
replay_buffer=runner.replay_buffer,
top_k=runner.k,
epsilon=runner.epsilon,
)
def on_batch_end(self, runner: dl.IRunner):
if runner.global_batch_step % self.session_period == 0:
session_reward = generate_session(
env=runner.env,
actor=runner.model["origin_actor"],
critic=runner.model["origin_critic"],
replay_buffer=runner.replay_buffer,
top_k=runner.k,
epsilon=runner.epsilon,
)
runner.batch_metrics.update({"s_reward": session_reward})
def on_epoch_end(self, runner: dl.IRunner):
valid_reward = generate_sessions(
env=runner.env,
actor=runner.model["origin_actor"],
critic=runner.model["origin_critic"],
top_k=runner.k,
epsilon=None
)
runner.epoch_metrics["_epoch_"]["train_v_reward"] = valid_reward
class CustomRunner(dl.Runner):
def __init__(self, *, env, replay_buffer, gamma, tau, epsilon=0.2, tau_period=1, k=5, **kwargs):
super().__init__(**kwargs)
self.env = env
self.replay_buffer = replay_buffer
self.gamma = gamma
self.tau = tau
self.tau_period = tau_period
self.epsilon = epsilon
self.k = k
def on_stage_start(self, runner: dl.IRunner):
super().on_stage_start(runner)
soft_update(self.model["origin_actor"], self.model["target_actor"], 1.0)
soft_update(self.model["origin_critic"], self.model["target_critic"], 1.0)
def handle_batch(self, batch):
# model train/valid step
states, actions, rewards, dones, next_states = batch
proto_actions = self.model["origin_actor"](states)
policy_loss = (-self.model["origin_critic"](states, proto_actions)).mean()
with torch.no_grad():
target_proto_actions = self.model["target_actor"](next_states)
target_values = self.model["target_critic"].get_best(next_states, target_proto_actions, self.k)[1].detach()
dones = dones * 1.0
expected_values = target_values * self.gamma * (1 - dones) + rewards
actions = self.model["origin_critic"].doc_embs(actions.squeeze())
values = self.model["origin_critic"](states, actions).squeeze()
value_loss = self.criterion(
values,
expected_values
)
self.batch_metrics.update(
{
"critic_loss": value_loss,
"actor_loss": policy_loss,
}
)
if self.is_train_loader:
self.optimizer["actor"].zero_grad()
policy_loss.backward()
self.optimizer["actor"].step()
self.optimizer["critic"].zero_grad()
value_loss.backward()
self.optimizer["critic"].step()
if self.global_batch_step % self.tau_period == 0:
soft_update(self.model["target_critic"], self.model["origin_critic"], self.tau)
soft_update(self.model["target_actor"], self.model["origin_actor"], self.tau)
Let’s train our model and check the results.
utils.set_global_seed(42)
env = make_env()
replay_buffer = ReplayBuffer(int(1e5))
gamma = 0.99
tau = 0.001
tau_period = 1
session_period = 1
epoch_size = int(1e4)
models = {
"origin_actor": ActorModel(doc_num=DOC_NUM, doc_emb_size=EMB_SIZE),
"origin_critic": CriticModel(doc_num=DOC_NUM, doc_emb_size=EMB_SIZE),
"target_actor": ActorModel(doc_num=DOC_NUM, doc_emb_size=EMB_SIZE),
"target_critic": CriticModel(doc_num=DOC_NUM, doc_emb_size=EMB_SIZE),
}
with torch.no_grad():
models["origin_critic"].doc_embs[0].weight.copy_(models["target_critic"].doc_embs[0].weight)
utils.set_requires_grad(models["target_actor"], requires_grad=False)
utils.set_requires_grad(models["target_critic"], requires_grad=False)
criterion = torch.nn.MSELoss()
optimizer = {
"actor": torch.optim.Adam(models["origin_actor"].parameters(), lr=1e-3),
"critic": torch.optim.Adam(models["origin_critic"].parameters(), lr=1e-3),
}
loaders = {
"train": DataLoader(
ReplayDataset(replay_buffer, epoch_size=epoch_size),
batch_size=32,
),
}
runner = CustomRunner(
env=env,
replay_buffer=replay_buffer,
gamma=gamma,
tau=tau,
tau_period=tau_period
)
runner.train(
model=models,
criterion=criterion,
optimizer=optimizer,
loaders=loaders,
logdir="./logs_rl",
valid_loader="_epoch_",
valid_metric="train_v_reward",
minimize_valid_metric=False,
load_best_on_end=True,
num_epochs=20,
verbose=False,
callbacks=[RecSimCallback(order=0, session_period=session_period)]
)
/usr/local/lib/python3.7/dist-packages/catalyst/core/runner.py:624: UserWarning: No ``ICriterionCallback/CriterionCallback`` were found while runner.criterion is not None.Do you compute the loss during ``runner.handle_batch``?
"No ``ICriterionCallback/CriterionCallback`` were found "
train (1/20)
* Epoch (1/20) train_v_reward: 4.45
train (2/20)
* Epoch (2/20) train_v_reward: 5.48
train (3/20)
* Epoch (3/20) train_v_reward: 4.35
train (4/20)
* Epoch (4/20) train_v_reward: 4.73
train (5/20)
* Epoch (5/20) train_v_reward: 5.52
train (6/20)
* Epoch (6/20) train_v_reward: 4.36
train (7/20)
* Epoch (7/20) train_v_reward: 4.88
train (8/20)
* Epoch (8/20) train_v_reward: 4.33
train (9/20)
* Epoch (9/20) train_v_reward: 5.01
train (10/20)
* Epoch (10/20) train_v_reward: 4.78
train (11/20)
* Epoch (11/20) train_v_reward: 4.9
train (12/20)
* Epoch (12/20) train_v_reward: 5.41
train (13/20)
* Epoch (13/20) train_v_reward: 4.63
train (14/20)
* Epoch (14/20) train_v_reward: 4.86
train (15/20)
* Epoch (15/20) train_v_reward: 4.38
train (16/20)
* Epoch (16/20) train_v_reward: 4.15
train (17/20)
* Epoch (17/20) train_v_reward: 4.45
train (18/20)
* Epoch (18/20) train_v_reward: 4.27
train (19/20)
* Epoch (19/20) train_v_reward: 5.27
train (20/20)
* Epoch (20/20) train_v_reward: 5.14
Top best models:
logs_rl/checkpoints/train.5.pth 5.5200
In our case, we can compare RL bot results with the optimal recommender agent. The agent can be built by the relation matrix W. We need to chose an index with the maximum value in the column.
from recsim.agent import AbstractEpisodicRecommenderAgent
class OptimalRecommender(AbstractEpisodicRecommenderAgent):
def __init__(self, environment, W):
super().__init__(environment.action_space)
self._observation_space = environment.observation_space
self._W = W
def step(self, reward, observation):
return [self._W[observation["user"], :].argmax()]
def run_agent(
env,
agent,
num_steps: int = int(1e4),
log_every: int = int(1e3)
):
reward_history = []
step, episode = 1, 1
observation = env.reset()
while step < num_steps:
action = agent.begin_episode(observation)
episode_reward = 0
while True:
observation, reward, done, info = env.step(action)
episode_reward += reward
if step % log_every == 0:
print(step, np.mean(reward_history[-50:]))
step += 1
if done:
break
else:
action = agent.step(reward, observation)
agent.end_episode(reward, observation)
reward_history.append(episode_reward)
return reward_history
env = make_env()
agent = OptimalRecommender(env, W)
reward_history = run_agent(env, agent)
1000 8.26
2000 7.22
3000 8.18
4000 9.14
5000 8.22
6000 8.22
7000 10.76
8000 9.44
9000 8.2
10000 9.5