FrozenLake using Value Iteration¶
%load_ext tensorboard
import gym
import collections
from torch.utils.tensorboard import SummaryWriter
ENV_NAME = "FrozenLake-v0"
#ENV_NAME = "FrozenLake8x8-v0" # uncomment for larger version
GAMMA = 0.9
TEST_EPISODES = 20
class Agent:
def __init__(self):
self.env = gym.make(ENV_NAME)
self.state = self.env.reset()
self.rewards = collections.defaultdict(float)
self.transits = collections.defaultdict(
collections.Counter)
self.values = collections.defaultdict(float)
def play_n_random_steps(self, count):
for _ in range(count):
action = self.env.action_space.sample()
new_state, reward, is_done, _ = self.env.step(action)
self.rewards[(self.state, action, new_state)] = reward
self.transits[(self.state, action)][new_state] += 1
self.state = self.env.reset() \
if is_done else new_state
def calc_action_value(self, state, action):
target_counts = self.transits[(state, action)]
total = sum(target_counts.values())
action_value = 0.0
for tgt_state, count in target_counts.items():
reward = self.rewards[(state, action, tgt_state)]
val = reward + GAMMA * self.values[tgt_state]
action_value += (count / total) * val
return action_value
def select_action(self, state):
best_action, best_value = None, None
for action in range(self.env.action_space.n):
action_value = self.calc_action_value(state, action)
if best_value is None or best_value < action_value:
best_value = action_value
best_action = action
return best_action
def play_episode(self, env):
total_reward = 0.0
state = env.reset()
while True:
action = self.select_action(state)
new_state, reward, is_done, _ = env.step(action)
self.rewards[(state, action, new_state)] = reward
self.transits[(state, action)][new_state] += 1
total_reward += reward
if is_done:
break
state = new_state
return total_reward
def value_iteration(self):
for state in range(self.env.observation_space.n):
state_values = [
self.calc_action_value(state, action)
for action in range(self.env.action_space.n)
]
self.values[state] = max(state_values)
if __name__ == "__main__":
test_env = gym.make(ENV_NAME)
agent = Agent()
writer = SummaryWriter(comment="-v-iteration")
iter_no = 0
best_reward = 0.0
while True:
iter_no += 1
agent.play_n_random_steps(100)
agent.value_iteration()
reward = 0.0
for _ in range(TEST_EPISODES):
reward += agent.play_episode(test_env)
reward /= TEST_EPISODES
writer.add_scalar("reward", reward, iter_no)
if reward > best_reward:
print("Best reward updated %.3f -> %.3f" % (
best_reward, reward))
best_reward = reward
if reward > 0.80:
print("Solved in %d iterations!" % iter_no)
break
writer.close()
Best reward updated 0.000 -> 0.300
Best reward updated 0.300 -> 0.400
Best reward updated 0.400 -> 0.500
Best reward updated 0.500 -> 0.550
Best reward updated 0.550 -> 0.650
Best reward updated 0.650 -> 0.700
Best reward updated 0.700 -> 0.850
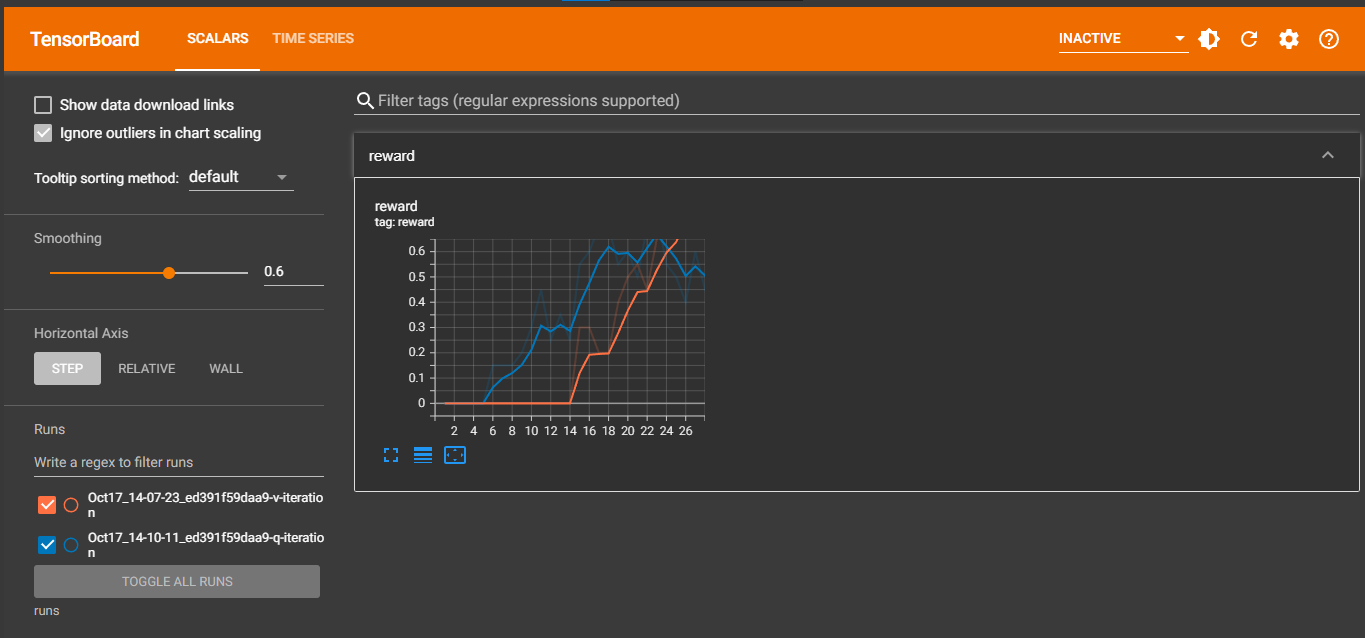
Solved in 26 iterations!
class Agent:
def __init__(self):
self.env = gym.make(ENV_NAME)
self.state = self.env.reset()
self.rewards = collections.defaultdict(float)
self.transits = collections.defaultdict(collections.Counter)
self.values = collections.defaultdict(float)
def play_n_random_steps(self, count):
for _ in range(count):
action = self.env.action_space.sample()
new_state, reward, is_done, _ = self.env.step(action)
self.rewards[(self.state, action, new_state)] = reward
self.transits[(self.state, action)][new_state] += 1
self.state = self.env.reset() if is_done else new_state
def select_action(self, state):
best_action, best_value = None, None
for action in range(self.env.action_space.n):
action_value = self.values[(state, action)]
if best_value is None or best_value < action_value:
best_value = action_value
best_action = action
return best_action
def play_episode(self, env):
total_reward = 0.0
state = env.reset()
while True:
action = self.select_action(state)
new_state, reward, is_done, _ = env.step(action)
self.rewards[(state, action, new_state)] = reward
self.transits[(state, action)][new_state] += 1
total_reward += reward
if is_done:
break
state = new_state
return total_reward
def value_iteration(self):
for state in range(self.env.observation_space.n):
for action in range(self.env.action_space.n):
action_value = 0.0
target_counts = self.transits[(state, action)]
total = sum(target_counts.values())
for tgt_state, count in target_counts.items():
key = (state, action, tgt_state)
reward = self.rewards[key]
best_action = self.select_action(tgt_state)
val = reward + GAMMA * \
self.values[(tgt_state, best_action)]
action_value += (count / total) * val
self.values[(state, action)] = action_value
if __name__ == "__main__":
test_env = gym.make(ENV_NAME)
agent = Agent()
writer = SummaryWriter(comment="-q-iteration")
iter_no = 0
best_reward = 0.0
while True:
iter_no += 1
agent.play_n_random_steps(100)
agent.value_iteration()
reward = 0.0
for _ in range(TEST_EPISODES):
reward += agent.play_episode(test_env)
reward /= TEST_EPISODES
writer.add_scalar("reward", reward, iter_no)
if reward > best_reward:
print("Best reward updated %.3f -> %.3f" % (best_reward, reward))
best_reward = reward
if reward > 0.80:
print("Solved in %d iterations!" % iter_no)
break
writer.close()
Best reward updated 0.000 -> 0.150
Best reward updated 0.150 -> 0.200
Best reward updated 0.200 -> 0.300
Best reward updated 0.300 -> 0.450
Best reward updated 0.450 -> 0.550
Best reward updated 0.550 -> 0.600
Best reward updated 0.600 -> 0.700
Best reward updated 0.700 -> 0.750
Best reward updated 0.750 -> 0.800
Best reward updated 0.800 -> 0.850
Solved in 85 iterations!
%tensorboard --logdir runs