GAN User Model for RL-based Recommendation System¶
A model-based RL framework for recommendation systems, where a user behavior model and the associated reward function are learned in unified minmax framework, and then RL policies are learned using this model.
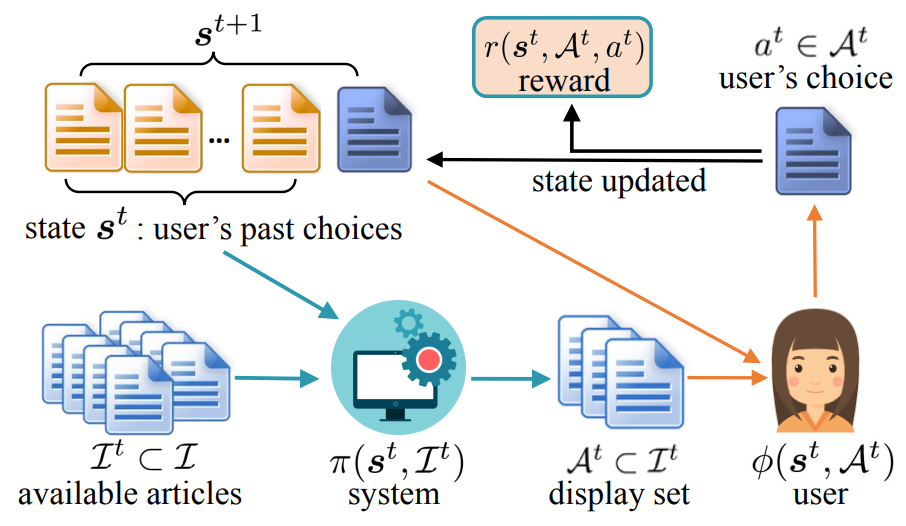
Since reinforcement learning can take into account long-term reward, it holds the promise to improve users’ long-term engagement with an online platform. In the RL framework, a recommendation system aims to find a policy \(π(s, I)\) to choose from a set \(I\) of items in user state \(s\), such that the cumulative expected reward is maximized,
Several key aspects are as follows:
Environment will correspond to a logged online user who can click on one of the k items displayed by the recommendation system in each page view (or interaction).
State \(s^t ∈ S\) will correspond to an ordered sequence of a user’s historical clicks.
\(Action\) \(A^t\) of the recommender will correspond to a subset of k items chosen by the recommender to display to the user. Itemset means the set of all subsets of k items of \(I^t\), where \(I^t ⊂ I\) are available items to recommend at time t.
State Transition \(P(·|s^t,A^t)\) will correspond to a user behavior model which returns the transition probability for \(s^{t+1}\) given previous state \(s^t\) and the set of items \(A^t\) displayed by the system. It is equivalent to the distribution \(φ(s^t , A^t)\) over a user’s actions.
Reward Function will correspond to a user’s utility or satisfaction after making her choice. Here we assume that the reward to the recommendation system is the same as the user’s utility. Thus, a recommendation algorithm which optimizes its long-term reward is designed to satisfy the user in a long run. One can also include the company’s benefit to the reward, but we will focus on users’ satisfaction.
Policy will correspond to a recommendation strategy which returns the probability of displaying a subset \(A^t\) of \(I^t\) in user state \(s^t\).
Since both the reward function and the state transition model are unknown, we need to learn them from data. Once they are learned, the optimal policy \(π^∗\) can be estimated by repeated querying the model using algorithms such as Q-learning.
Setup¶
%tensorflow_version 1.x
TensorFlow 1.x selected.
!wget -q --show-progress -O yelp.txt https://raw.githubusercontent.com/sparsh-ai/drl-recsys/main/data/bronze/yelp.txt?token=APAMRF52LJRGV4LHOTCBSMDBOEDGM
yelp.txt 0%[ ] 0 --.-KB/s
yelp.txt 100%[===================>] 443.24K --.-KB/s in 0.03s
from __future__ import print_function
from __future__ import absolute_import
from __future__ import division
import os
import numpy as np
import pickle
import pandas as pd
import datetime
import itertools
import tensorflow as tf
import threading
Params¶
class Args:
dataset = 'yelp' # 'choose rsc, tb, or yelp'
data_folder = '.'
save_dir = './scratch'
resplit = False
num_thread = 10
learning_rate = 1e-3
batch_size = 128
num_itrs = 2000
rnn_hidden_dim = 20 # LSTM hidden sizes
pw_dim = 4 # position weight dim
pw_band_size = 20 # position weight banded size (i.e. length of history)
dims = '64-64'
user_model = 'LSTM' # architecture choice: LSTM or PW
cmd_args = Args()
Data Preprocessing¶
# The format of processed data:
# data_behavior[user][0] is user_id
# data_behavior[user][1][t] is displayed list at time t
# data_behavior[user][2][t] is picked id at time t
filename = './'+cmd_args.dataset+'.txt'
raw_data = pd.read_csv(filename, sep='\t', usecols=[1, 3, 5, 7, 6], dtype={1: int, 3: int, 7: int, 5:int, 6:int})
raw_data.drop_duplicates(subset=['session_new_index','Time','item_new_index','is_click'], inplace=True)
raw_data.sort_values(by='is_click',inplace=True)
raw_data.drop_duplicates(keep='last', subset=['session_new_index','Time','item_new_index'], inplace=True)
raw_data
| Time | is_click | session_new_index | item_new_index | tr_val_tst | |
|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 |
| 4212 | 1109 | 0 | 909 | 91 | 1 |
| 4210 | 1108 | 0 | 908 | 453 | 1 |
| 4209 | 1108 | 0 | 908 | 452 | 1 |
| 4206 | 1106 | 0 | 906 | 564 | 1 |
| ... | ... | ... | ... | ... | ... |
| 1144 | 309 | 1 | 256 | 50 | 0 |
| 2273 | 601 | 1 | 507 | 187 | 0 |
| 1146 | 310 | 1 | 257 | 102 | 0 |
| 5249 | 1365 | 1 | 1117 | 764 | 2 |
| 6755 | 1724 | 1 | 1405 | 420 | 2 |
6676 rows × 5 columns
The column ‘session_new_index’ corresponds to user ID
The column ‘item_new_index’ corresponds to item ID
If several items have the same ‘Time’ index, then they are displayed at the same time (in the same display set)
sizes = raw_data.nunique()
size_user = sizes['session_new_index']
size_item = sizes['item_new_index']
data_user = raw_data.groupby(by='session_new_index')
data_behavior = [[] for _ in range(size_user)]
train_user = []
vali_user = []
test_user = []
sum_length = 0
event_cnt = 0
for user in range(size_user):
data_behavior[user] = [[], [], []]
data_behavior[user][0] = user
data_u = data_user.get_group(user)
split_tag = list(data_u['tr_val_tst'])[0]
if split_tag == 0:
train_user.append(user)
elif split_tag == 1:
vali_user.append(user)
else:
test_user.append(user)
data_u_time = data_u.groupby(by='Time')
time_set = np.array(list(set(data_u['Time'])))
time_set.sort()
true_t = 0
for t in range(len(time_set)):
display_set = data_u_time.get_group(time_set[t])
event_cnt += 1
sum_length += len(display_set)
data_behavior[user][1].append(list(display_set['item_new_index']))
data_behavior[user][2].append(int(display_set[display_set.is_click==1]['item_new_index']))
new_features = np.eye(size_item)
filename = './'+cmd_args.dataset+'.pkl'
file = open(filename, 'wb')
pickle.dump(data_behavior, file, protocol=pickle.HIGHEST_PROTOCOL)
pickle.dump(new_features, file, protocol=pickle.HIGHEST_PROTOCOL)
file.close()
filename = './'+cmd_args.dataset+'-split.pkl'
file = open(filename, 'wb')
pickle.dump(train_user, file, protocol=pickle.HIGHEST_PROTOCOL)
pickle.dump(vali_user, file, protocol=pickle.HIGHEST_PROTOCOL)
pickle.dump(test_user, file, protocol=pickle.HIGHEST_PROTOCOL)
file.close()
Dataset¶
class Dataset(object):
def __init__(self, args):
self.data_folder = args.data_folder
self.dataset = args.dataset
self.model_type = args.user_model
self.band_size = args.pw_band_size
data_filename = os.path.join(args.data_folder, args.dataset+'.pkl')
f = open(data_filename, 'rb')
data_behavior = pickle.load(f)
item_feature = pickle.load(f)
f.close()
# data_behavior[user][0] is user_id
# data_behavior[user][1][t] is displayed list at time t
# data_behavior[user][2][t] is picked id at time t
self.size_item = len(item_feature)
self.size_user = len(data_behavior)
self.f_dim = len(item_feature[0])
# Load user splits
filename = os.path.join(self.data_folder, self.dataset+'-split.pkl')
pkl_file = open(filename, 'rb')
self.train_user = pickle.load(pkl_file)
self.vali_user = pickle.load(pkl_file)
self.test_user = pickle.load(pkl_file)
pkl_file.close()
# Process data
k_max = 0
for d_b in data_behavior:
for disp in d_b[1]:
k_max = max(k_max, len(disp))
self.data_click = [[] for x in range(self.size_user)]
self.data_disp = [[] for x in range(self.size_user)]
self.data_time = np.zeros(self.size_user, dtype=np.int)
self.data_news_cnt = np.zeros(self.size_user, dtype=np.int)
self.feature = [[] for x in range(self.size_user)]
self.feature_click = [[] for x in range(self.size_user)]
for user in range(self.size_user):
# (1) count number of clicks
click_t = 0
num_events = len(data_behavior[user][1])
click_t += num_events
self.data_time[user] = click_t
# (2)
news_dict = {}
self.feature_click[user] = np.zeros([click_t, self.f_dim])
click_t = 0
for event in range(num_events):
disp_list = data_behavior[user][1][event]
pick_id = data_behavior[user][2][event]
for id in disp_list:
if id not in news_dict:
news_dict[id] = len(news_dict) # for each user, news id start from 0
id = pick_id
self.data_click[user].append([click_t, news_dict[id]])
self.feature_click[user][click_t] = item_feature[id]
for idd in disp_list:
self.data_disp[user].append([click_t, news_dict[idd]])
click_t += 1 # splitter a event with 2 clickings to 2 events
self.data_news_cnt[user] = len(news_dict)
self.feature[user] = np.zeros([self.data_news_cnt[user], self.f_dim])
for id in news_dict:
self.feature[user][news_dict[id]] = item_feature[id]
self.feature[user] = self.feature[user].tolist()
self.feature_click[user] = self.feature_click[user].tolist()
self.max_disp_size = k_max
def random_split_user(self):
num_users = len(self.train_user) + len(self.vali_user) + len(self.test_user)
shuffle_order = np.arange(num_users)
np.random.shuffle(shuffle_order)
self.train_user = shuffle_order[0:len(self.train_user)].tolist()
self.vali_user = shuffle_order[len(self.train_user):len(self.train_user)+len(self.vali_user)].tolist()
self.test_user = shuffle_order[len(self.train_user)+len(self.vali_user):].tolist()
def data_process_for_placeholder(self, user_set):
if self.model_type == 'PW':
sec_cnt_x = 0
news_cnt_short_x = 0
news_cnt_x = 0
click_2d_x = []
disp_2d_x = []
tril_indice = []
tril_value_indice = []
disp_2d_split_sec = []
feature_clicked_x = []
disp_current_feature_x = []
click_sub_index_2d = []
for u in user_set:
t_indice = []
for kk in range(min(self.band_size-1, self.data_time[u]-1)):
t_indice += map(lambda x: [x + kk+1 + sec_cnt_x, x + sec_cnt_x], np.arange(self.data_time[u] - (kk+1)))
tril_indice += t_indice
tril_value_indice += map(lambda x: (x[0] - x[1] - 1), t_indice)
click_2d_tmp = map(lambda x: [x[0] + sec_cnt_x, x[1]], self.data_click[u])
click_2d_x += click_2d_tmp
disp_2d_tmp = map(lambda x: [x[0] + sec_cnt_x, x[1]], self.data_disp[u])
click_sub_index_tmp = map(lambda x: disp_2d_tmp.index(x), click_2d_tmp)
click_sub_index_2d += map(lambda x: x+len(disp_2d_x), click_sub_index_tmp)
disp_2d_x += disp_2d_tmp
disp_2d_split_sec += map(lambda x: x[0] + sec_cnt_x, self.data_disp[u])
sec_cnt_x += self.data_time[u]
news_cnt_short_x = max(news_cnt_short_x, self.data_news_cnt[u])
news_cnt_x += self.data_news_cnt[u]
disp_current_feature_x += map(lambda x: self.feature[u][x], [idd[1] for idd in self.data_disp[u]])
feature_clicked_x += self.feature_click[u]
return click_2d_x, disp_2d_x, \
disp_current_feature_x, sec_cnt_x, tril_indice, tril_value_indice, \
disp_2d_split_sec, news_cnt_short_x, click_sub_index_2d, feature_clicked_x
else:
news_cnt_short_x = 0
u_t_dispid = []
u_t_dispid_split_ut = []
u_t_dispid_feature = []
u_t_clickid = []
size_user = len(user_set)
max_time = 0
click_sub_index = []
for u in user_set:
max_time = max(max_time, self.data_time[u])
user_time_dense = np.zeros([size_user, max_time], dtype=np.float32)
click_feature = np.zeros([max_time, size_user, self.f_dim])
for u_idx in range(size_user):
u = user_set[u_idx]
u_t_clickid_tmp = []
u_t_dispid_tmp = []
for x in self.data_click[u]:
t, click_id = x
click_feature[t][u_idx] = self.feature[u][click_id]
u_t_clickid_tmp.append([u_idx, t, click_id])
user_time_dense[u_idx, t] = 1.0
u_t_clickid = u_t_clickid + u_t_clickid_tmp
for x in self.data_disp[u]:
t, disp_id = x
u_t_dispid_tmp.append([u_idx, t, disp_id])
u_t_dispid_split_ut.append([u_idx, t])
u_t_dispid_feature.append(self.feature[u][disp_id])
click_sub_index_tmp = map(lambda x: u_t_dispid_tmp.index(x), u_t_clickid_tmp)
click_sub_index += map(lambda x: x+len(u_t_dispid), click_sub_index_tmp)
u_t_dispid = u_t_dispid + u_t_dispid_tmp
news_cnt_short_x = max(news_cnt_short_x, self.data_news_cnt[u])
if self.model_type != 'LSTM':
print('model type not supported. using LSTM')
return size_user, max_time, news_cnt_short_x, u_t_dispid, u_t_dispid_split_ut, np.array(u_t_dispid_feature),\
click_feature, click_sub_index, u_t_clickid, user_time_dense
def data_process_for_placeholder_L2(self, user_set):
news_cnt_short_x = 0
u_t_dispid = []
u_t_dispid_split_ut = []
u_t_dispid_feature = []
u_t_clickid = []
size_user = len(user_set)
max_time = 0
click_sub_index = []
for u in user_set:
max_time = max(max_time, self.data_time[u])
user_time_dense = np.zeros([size_user, max_time], dtype=np.float32)
click_feature = np.zeros([max_time, size_user, self.f_dim])
for u_idx in range(size_user):
u = user_set[u_idx]
item_cnt = [{} for _ in range(self.data_time[u])]
u_t_clickid_tmp = []
u_t_dispid_tmp = []
for x in self.data_disp[u]:
t, disp_id = x
u_t_dispid_split_ut.append([u_idx, t])
u_t_dispid_feature.append(self.feature[u][disp_id])
if disp_id not in item_cnt[t]:
item_cnt[t][disp_id] = len(item_cnt[t])
u_t_dispid_tmp.append([u_idx, t, item_cnt[t][disp_id]])
for x in self.data_click[u]:
t, click_id = x
click_feature[t][u_idx] = self.feature[u][click_id]
u_t_clickid_tmp.append([u_idx, t, item_cnt[t][click_id]])
user_time_dense[u_idx, t] = 1.0
u_t_clickid = u_t_clickid + u_t_clickid_tmp
click_sub_index_tmp = map(lambda x: u_t_dispid_tmp.index(x), u_t_clickid_tmp)
click_sub_index += map(lambda x: x+len(u_t_dispid), click_sub_index_tmp)
u_t_dispid = u_t_dispid + u_t_dispid_tmp
# news_cnt_short_x = max(news_cnt_short_x, data_news_cnt[u])
news_cnt_short_x = self.max_disp_size
return size_user, max_time, news_cnt_short_x, \
u_t_dispid, u_t_dispid_split_ut, np.array(u_t_dispid_feature), click_feature, click_sub_index, \
u_t_clickid, user_time_dense
def prepare_validation_data_L2(self, num_sets, v_user):
vali_thread_u = [[] for _ in range(num_sets)]
size_user_v = [[] for _ in range(num_sets)]
max_time_v = [[] for _ in range(num_sets)]
news_cnt_short_v = [[] for _ in range(num_sets)]
u_t_dispid_v = [[] for _ in range(num_sets)]
u_t_dispid_split_ut_v = [[] for _ in range(num_sets)]
u_t_dispid_feature_v = [[] for _ in range(num_sets)]
click_feature_v = [[] for _ in range(num_sets)]
click_sub_index_v = [[] for _ in range(num_sets)]
u_t_clickid_v = [[] for _ in range(num_sets)]
ut_dense_v = [[] for _ in range(num_sets)]
for ii in range(len(v_user)):
vali_thread_u[ii % num_sets].append(v_user[ii])
for ii in range(num_sets):
size_user_v[ii], max_time_v[ii], news_cnt_short_v[ii], u_t_dispid_v[ii],\
u_t_dispid_split_ut_v[ii], u_t_dispid_feature_v[ii], click_feature_v[ii], \
click_sub_index_v[ii], u_t_clickid_v[ii], ut_dense_v[ii] = self.data_process_for_placeholder_L2(vali_thread_u[ii])
return vali_thread_u, size_user_v, max_time_v, news_cnt_short_v, u_t_dispid_v, u_t_dispid_split_ut_v,\
u_t_dispid_feature_v, click_feature_v, click_sub_index_v, u_t_clickid_v, ut_dense_v
def prepare_validation_data(self, num_sets, v_user):
if self.model_type == 'PW':
vali_thread_u = [[] for _ in range(num_sets)]
click_2d_v = [[] for _ in range(num_sets)]
disp_2d_v = [[] for _ in range(num_sets)]
feature_v = [[] for _ in range(num_sets)]
sec_cnt_v = [[] for _ in range(num_sets)]
tril_ind_v = [[] for _ in range(num_sets)]
tril_value_ind_v = [[] for _ in range(num_sets)]
disp_2d_split_sec_v = [[] for _ in range(num_sets)]
feature_clicked_v = [[] for _ in range(num_sets)]
news_cnt_short_v = [[] for _ in range(num_sets)]
click_sub_index_2d_v = [[] for _ in range(num_sets)]
for ii in range(len(v_user)):
vali_thread_u[ii % num_sets].append(v_user[ii])
for ii in range(num_sets):
click_2d_v[ii], disp_2d_v[ii], feature_v[ii], sec_cnt_v[ii], tril_ind_v[ii], tril_value_ind_v[ii], \
disp_2d_split_sec_v[ii], news_cnt_short_v[ii], click_sub_index_2d_v[ii], feature_clicked_v[ii] = self.data_process_for_placeholder(vali_thread_u[ii])
return vali_thread_u, click_2d_v, disp_2d_v, feature_v, sec_cnt_v, tril_ind_v, tril_value_ind_v, \
disp_2d_split_sec_v, news_cnt_short_v, click_sub_index_2d_v, feature_clicked_v
else:
if self.model_type != 'LSTM':
print('model type not supported. using LSTM')
vali_thread_u = [[] for _ in range(num_sets)]
size_user_v = [[] for _ in range(num_sets)]
max_time_v = [[] for _ in range(num_sets)]
news_cnt_short_v = [[] for _ in range(num_sets)]
u_t_dispid_v = [[] for _ in range(num_sets)]
u_t_dispid_split_ut_v = [[] for _ in range(num_sets)]
u_t_dispid_feature_v = [[] for _ in range(num_sets)]
click_feature_v = [[] for _ in range(num_sets)]
click_sub_index_v = [[] for _ in range(num_sets)]
u_t_clickid_v = [[] for _ in range(num_sets)]
ut_dense_v = [[] for _ in range(num_sets)]
for ii in range(len(v_user)):
vali_thread_u[ii % num_sets].append(v_user[ii])
for ii in range(num_sets):
size_user_v[ii], max_time_v[ii], news_cnt_short_v[ii], u_t_dispid_v[ii],\
u_t_dispid_split_ut_v[ii], u_t_dispid_feature_v[ii], click_feature_v[ii], \
click_sub_index_v[ii], u_t_clickid_v[ii], ut_dense_v[ii] = self.data_process_for_placeholder(vali_thread_u[ii])
return vali_thread_u, size_user_v, max_time_v, news_cnt_short_v, u_t_dispid_v, u_t_dispid_split_ut_v,\
u_t_dispid_feature_v, click_feature_v, click_sub_index_v, u_t_clickid_v, ut_dense_v
GAN-based User model¶
def mlp(x, hidden_dims, output_dim, activation, sd, act_last=False):
hidden_dims = tuple(map(int, hidden_dims.split("-")))
for h in hidden_dims:
x = tf.layers.dense(x, h, activation=activation, trainable=True,
kernel_initializer=tf.truncated_normal_initializer(stddev=sd))
if act_last:
return tf.layers.dense(x, output_dim, activation=activation, trainable=True,
kernel_initializer=tf.truncated_normal_initializer(stddev=sd))
else:
return tf.layers.dense(x, output_dim, trainable=True,
kernel_initializer=tf.truncated_normal_initializer(stddev=sd))
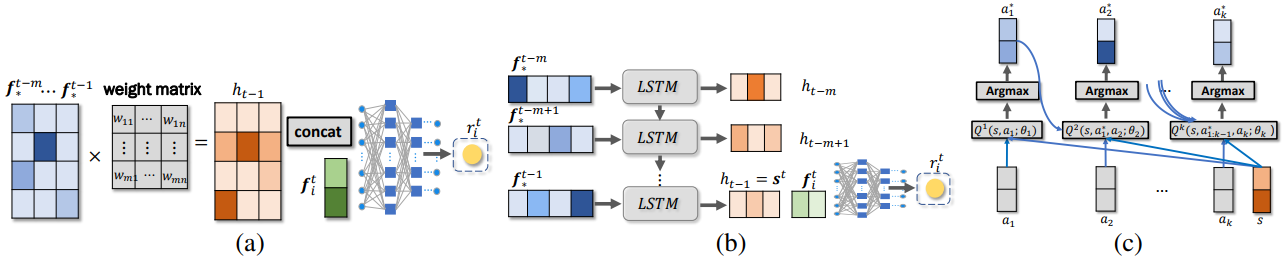
class UserModelLSTM(object):
def __init__(self, f_dim, args, max_disp_size=None):
self.f_dim = f_dim
self.placeholder = {}
self.rnn_hidden = args.rnn_hidden_dim
self.hidden_dims = args.dims
self.lr = args.learning_rate
self.max_disp_size = max_disp_size
def construct_placeholder(self):
self.placeholder['clicked_feature'] = tf.placeholder(tf.float32, (None, None, self.f_dim)) # (time, user=batch, f_dim)
self.placeholder['ut_dispid_feature'] = tf.placeholder(tf.float32, shape=[None, self.f_dim]) # # (user*time*dispid, _f_dim)
self.placeholder['ut_dispid_ut'] = tf.placeholder(dtype=tf.int64, shape=[None, 2])
self.placeholder['ut_dispid'] = tf.placeholder(dtype=tf.int64, shape=[None, 3])
self.placeholder['ut_clickid'] = tf.placeholder(dtype=tf.int64, shape=[None, 3])
self.placeholder['ut_clickid_val'] = tf.placeholder(dtype=tf.float32, shape=[None])
self.placeholder['click_sublist_index'] = tf.placeholder(dtype=tf.int64, shape=[None])
self.placeholder['ut_dense'] = tf.placeholder(dtype=tf.float32, shape=[None, None])
self.placeholder['time'] = tf.placeholder(dtype=tf.int64)
self.placeholder['item_size'] = tf.placeholder(dtype=tf.int64)
def construct_computation_graph(self):
batch_size = tf.shape(self.placeholder['clicked_feature'])[1]
denseshape = tf.concat([tf.cast(tf.reshape(batch_size, [-1]), tf.int64), tf.reshape(self.placeholder['time'], [-1]), tf.reshape(self.placeholder['item_size'], [-1])], 0)
# construct lstm
cell = tf.contrib.rnn.BasicLSTMCell(self.rnn_hidden, state_is_tuple=True)
initial_state = cell.zero_state(batch_size, tf.float32)
rnn_outputs, rnn_states = tf.nn.dynamic_rnn(cell, self.placeholder['clicked_feature'], initial_state=initial_state, time_major=True)
# rnn_outputs: (time, user=batch, rnn_hidden)
# (1) output forward one-step (2) then transpose
u_bar_feature = tf.concat([tf.zeros([1, batch_size, self.rnn_hidden], dtype=tf.float32), rnn_outputs], 0)
u_bar_feature = tf.transpose(u_bar_feature, perm=[1, 0, 2]) # (user, time, rnn_hidden)
# gather corresponding feature
u_bar_feature_gather = tf.gather_nd(u_bar_feature, self.placeholder['ut_dispid_ut'])
combine_feature = tf.concat([u_bar_feature_gather, self.placeholder['ut_dispid_feature']], axis=1)
# indicate size
combine_feature = tf.reshape(combine_feature, [-1, self.rnn_hidden + self.f_dim])
# utility
u_net = mlp(combine_feature, self.hidden_dims, 1, activation=tf.nn.elu, sd=1e-1, act_last=False)
u_net = tf.reshape(u_net, [-1])
click_u_tensor = tf.SparseTensor(self.placeholder['ut_clickid'], tf.gather(u_net, self.placeholder['click_sublist_index']), dense_shape=denseshape)
disp_exp_u_tensor = tf.SparseTensor(self.placeholder['ut_dispid'], tf.exp(u_net), dense_shape=denseshape) # (user, time, id)
disp_sum_exp_u_tensor = tf.sparse_reduce_sum(disp_exp_u_tensor, axis=2)
sum_click_u_tensor = tf.sparse_reduce_sum(click_u_tensor, axis=2)
loss_tmp = - sum_click_u_tensor + tf.log(disp_sum_exp_u_tensor + 1) # (user, time) loss
loss_sum = tf.reduce_sum(tf.multiply(self.placeholder['ut_dense'], loss_tmp))
event_cnt = tf.reduce_sum(self.placeholder['ut_dense'])
loss = loss_sum / event_cnt
dense_exp_disp_util = tf.sparse_tensor_to_dense(disp_exp_u_tensor, default_value=0.0, validate_indices=False)
click_tensor = tf.sparse_to_dense(self.placeholder['ut_clickid'], denseshape, self.placeholder['ut_clickid_val'], default_value=0.0, validate_indices=False)
argmax_click = tf.argmax(click_tensor, axis=2)
argmax_disp = tf.argmax(dense_exp_disp_util, axis=2)
top_2_disp = tf.nn.top_k(dense_exp_disp_util, k=2, sorted=False)[1]
argmax_compare = tf.cast(tf.equal(argmax_click, argmax_disp), tf.float32)
precision_1_sum = tf.reduce_sum(tf.multiply(self.placeholder['ut_dense'], argmax_compare))
tmpshape = tf.concat([tf.cast(tf.reshape(batch_size, [-1]), tf.int64), tf.reshape(self.placeholder['time'], [-1]), tf.constant([1], dtype=tf.int64)], 0)
top2_compare = tf.reduce_sum(tf.cast(tf.equal(tf.reshape(argmax_click, tmpshape), tf.cast(top_2_disp, tf.int64)), tf.float32), axis=2)
precision_2_sum = tf.reduce_sum(tf.multiply(self.placeholder['ut_dense'], top2_compare))
precision_1 = precision_1_sum / event_cnt
precision_2 = precision_2_sum / event_cnt
return loss, precision_1, precision_2, loss_sum, precision_1_sum, precision_2_sum, event_cnt
def construct_computation_graph_u(self):
batch_size = tf.shape(self.placeholder['clicked_feature'])[1]
# construct lstm
cell = tf.contrib.rnn.BasicLSTMCell(self.rnn_hidden, state_is_tuple=True)
initial_state = cell.zero_state(batch_size, tf.float32)
rnn_outputs, rnn_states = tf.nn.dynamic_rnn(cell, self.placeholder['clicked_feature'], initial_state=initial_state, time_major=True)
# rnn_outputs: (time, user=batch, rnn_hidden)
# (1) output forward one-step (2) then transpose
u_bar_feature = tf.concat([tf.zeros([1, batch_size, self.rnn_hidden], dtype=tf.float32), rnn_outputs], 0)
u_bar_feature = tf.transpose(u_bar_feature, perm=[1, 0, 2]) # (user, time, rnn_hidden)
# gather corresponding feature
u_bar_feature_gather = tf.gather_nd(u_bar_feature, self.placeholder['ut_dispid_ut'])
combine_feature = tf.concat([u_bar_feature_gather, self.placeholder['ut_dispid_feature']], axis=1)
# indicate size
combine_feature = tf.reshape(combine_feature, [-1, self.rnn_hidden + self.f_dim])
# utility
u_net = mlp(combine_feature, self.hidden_dims, 1, activation=tf.nn.elu, sd=1e-1, act_last=False)
self.u_net = tf.reshape(u_net, [-1])
self.min_trainable_variables = tf.trainable_variables()
def construct_computation_graph_policy(self):
batch_size = tf.shape(self.placeholder['clicked_feature'])[1]
denseshape = tf.concat([tf.cast(tf.reshape(batch_size, [-1]), tf.int64), tf.reshape(self.placeholder['time'], [-1]), tf.reshape(self.placeholder['item_size'], [-1])], 0)
with tf.variable_scope('lstm2'):
cell2 = tf.contrib.rnn.BasicLSTMCell(self.rnn_hidden, state_is_tuple=True)
initial_state2 = cell2.zero_state(batch_size, tf.float32)
rnn_outputs2, rnn_states2 = tf.nn.dynamic_rnn(cell2, self.placeholder['clicked_feature'], initial_state=initial_state2, time_major=True)
u_bar_feature2 = tf.concat([tf.zeros([1, batch_size, self.rnn_hidden], dtype=tf.float32), rnn_outputs2], 0)
u_bar_feature2 = tf.transpose(u_bar_feature2, perm=[1, 0, 2]) # (user, time, rnn_hidden)
u_bar_feature_gather2 = tf.gather_nd(u_bar_feature2, self.placeholder['ut_dispid_ut'])
combine_feature2 = tf.concat([u_bar_feature_gather2, self.placeholder['ut_dispid_feature']], axis=1)
combine_feature2 = tf.reshape(combine_feature2, [-1, self.rnn_hidden + self.f_dim])
pi_net = mlp(combine_feature2, '256-32', 1, tf.nn.elu, 1e-2)
pi_net = tf.reshape(pi_net, [-1])
disp_pi_tensor = tf.SparseTensor(self.placeholder['ut_dispid'], pi_net, dense_shape=denseshape)
disp_pi_dense_tensor = tf.sparse_add((-10000.0) * tf.ones(tf.cast(denseshape, tf.int32)), disp_pi_tensor)
disp_pi_dense_tensor = tf.reshape(disp_pi_dense_tensor, [tf.cast(batch_size, tf.int32), tf.cast(self.placeholder['time'], tf.int32), self.max_disp_size])
pi_net = tf.contrib.layers.softmax(disp_pi_dense_tensor)
pi_net_val = tf.gather_nd(pi_net, self.placeholder['ut_dispid'])
loss_max_sum = tf.reduce_sum(tf.multiply(pi_net_val, self.u_net - 0.5 * pi_net_val))
event_cnt = tf.reduce_sum(self.placeholder['ut_dense'])
loss_max = loss_max_sum / event_cnt
sum_click_u_tensor = tf.reduce_sum(tf.gather(self.u_net, self.placeholder['click_sublist_index']))
loss_min_sum = loss_max_sum - sum_click_u_tensor
loss_min = loss_min_sum / event_cnt
click_tensor = tf.sparse_to_dense(self.placeholder['ut_clickid'], denseshape, self.placeholder['ut_clickid_val'], default_value=0.0)
argmax_click = tf.argmax(click_tensor, axis=2)
argmax_disp = tf.argmax(pi_net, axis=2)
top_2_disp = tf.nn.top_k(pi_net, k=2, sorted=False)[1]
argmax_compare = tf.cast(tf.equal(argmax_click, argmax_disp), tf.float32)
precision_1_sum = tf.reduce_sum(tf.multiply(self.placeholder['ut_dense'], argmax_compare))
tmpshape = tf.concat([tf.cast(tf.reshape(batch_size, [-1]), tf.int64), tf.reshape(self.placeholder['time'], [-1]), tf.constant([1], dtype=tf.int64)], 0)
top2_compare = tf.reduce_sum(tf.cast(tf.equal(tf.reshape(argmax_click, tmpshape), tf.cast(top_2_disp, tf.int64)), tf.float32), axis=2)
precision_2_sum = tf.reduce_sum(tf.multiply(self.placeholder['ut_dense'], top2_compare))
precision_1 = precision_1_sum / event_cnt
precision_2 = precision_2_sum / event_cnt
opt = tf.train.AdamOptimizer(learning_rate=self.lr)
max_trainable_variables = list(set(tf.trainable_variables()) - set(self.min_trainable_variables))
# lossL2_min = tf.add_n([tf.nn.l2_loss(v) for v in min_trainable_variables if 'bias' not in v.name]) * _regularity
# lossL2_max = tf.add_n([tf.nn.l2_loss(v) for v in max_trainable_variables if 'bias' not in v.name]) * _regularity
train_min_op = opt.minimize(loss_min, var_list=self.min_trainable_variables)
train_max_op = opt.minimize(-loss_max, var_list=max_trainable_variables)
self.init_variables = list(set(tf.global_variables()) - set(self.min_trainable_variables))
return train_min_op, train_max_op, loss_min, loss_max, precision_1, precision_2, loss_min_sum, loss_max_sum, precision_1_sum, precision_2_sum, event_cnt
def construct_model(self, is_training, reuse=False):
with tf.variable_scope('model', reuse=reuse):
loss, precision_1, precision_2, loss_sum, precision_1_sum, precision_2_sum, event_cnt = self.construct_computation_graph()
if is_training:
global_step = tf.Variable(0, trainable=False)
learning_rate = tf.train.exponential_decay(self.lr, global_step, 100000, 0.96, staircase=True)
opt = tf.train.AdamOptimizer(learning_rate=learning_rate)
train_op = opt.minimize(loss, global_step=global_step)
return train_op, loss, precision_1, precision_2, loss_sum, precision_1_sum, precision_2_sum, event_cnt
else:
return loss, precision_1, precision_2, loss_sum, precision_1_sum, precision_2_sum, event_cnt
class UserModelPW(object):
def __init__(self, f_dim, args):
self.f_dim = f_dim
self.placeholder = {}
self.hidden_dims = args.dims
self.lr = args.learning_rate
self.pw_dim = args.pw_dim
self.band_size = args.pw_band_size
def construct_placeholder(self):
self.placeholder['disp_current_feature'] = tf.placeholder(dtype=tf.float32, shape=[None, self.f_dim])
self.placeholder['Xs_clicked'] = tf.placeholder(dtype=tf.float32, shape=[None, self.f_dim])
self.placeholder['item_size'] = tf.placeholder(dtype=tf.int64, shape=[])
self.placeholder['section_length'] = tf.placeholder(dtype=tf.int64)
self.placeholder['click_indices'] = tf.placeholder(dtype=tf.int64, shape=[None, 2])
self.placeholder['click_values'] = tf.placeholder(dtype=tf.float32, shape=[None])
self.placeholder['disp_indices'] = tf.placeholder(dtype=tf.int64, shape=[None, 2])
self.placeholder['disp_2d_split_sec_ind'] = tf.placeholder(dtype=tf.int64, shape=[None])
self.placeholder['cumsum_tril_indices'] = tf.placeholder(dtype=tf.int64, shape=[None, 2])
self.placeholder['cumsum_tril_value_indices'] = tf.placeholder(dtype=tf.int64, shape=[None])
self.placeholder['click_2d_subindex'] = tf.placeholder(dtype=tf.int64, shape=[None])
def construct_computation_graph(self):
denseshape = [self.placeholder['section_length'], self.placeholder['item_size']]
# (1) history feature --- net ---> clicked_feature
# (1) construct cumulative history
click_history = [[] for _ in range(self.pw_dim)]
for ii in range(self.pw_dim):
position_weight = tf.get_variable('p_w'+str(ii), [self.band_size], initializer=tf.constant_initializer(0.0001))
cumsum_tril_value = tf.gather(position_weight, self.placeholder['cumsum_tril_value_indices'])
cumsum_tril_matrix = tf.SparseTensor(self.placeholder['cumsum_tril_indices'], cumsum_tril_value,
[self.placeholder['section_length'], self.placeholder['section_length']]) # sec by sec
click_history[ii] = tf.sparse_tensor_dense_matmul(cumsum_tril_matrix, self.placeholder['Xs_clicked']) # Xs_clicked: section by _f_dim
concat_history = tf.concat(click_history, axis=1)
disp_history_feature = tf.gather(concat_history, self.placeholder['disp_2d_split_sec_ind'])
# (4) combine features
concat_disp_features = tf.reshape(tf.concat([disp_history_feature, self.placeholder['disp_current_feature']], axis=1),
[-1, self.f_dim * self.pw_dim + self.f_dim])
# (5) compute utility
u_disp = mlp(concat_disp_features, self.hidden_dims, 1, tf.nn.elu, 1e-3, act_last=False)
# (5)
exp_u_disp = tf.exp(u_disp)
sum_exp_disp_ubar_ut = tf.segment_sum(exp_u_disp, self.placeholder['disp_2d_split_sec_ind'])
sum_click_u_bar_ut = tf.gather(u_disp, self.placeholder['click_2d_subindex'])
# (6) loss and precision
click_tensor = tf.SparseTensor(self.placeholder['click_indices'], self.placeholder['click_values'], denseshape)
click_cnt = tf.sparse_reduce_sum(click_tensor, axis=1)
loss_sum = tf.reduce_sum(- sum_click_u_bar_ut + tf.log(sum_exp_disp_ubar_ut + 1))
event_cnt = tf.reduce_sum(click_cnt)
loss = loss_sum / event_cnt
exp_disp_ubar_ut = tf.SparseTensor(self.placeholder['disp_indices'], tf.reshape(exp_u_disp, [-1]), denseshape)
dense_exp_disp_util = tf.sparse_tensor_to_dense(exp_disp_ubar_ut, default_value=0.0, validate_indices=False)
argmax_click = tf.argmax(tf.sparse_tensor_to_dense(click_tensor, default_value=0.0), axis=1)
argmax_disp = tf.argmax(dense_exp_disp_util, axis=1)
top_2_disp = tf.nn.top_k(dense_exp_disp_util, k=2, sorted=False)[1]
precision_1_sum = tf.reduce_sum(tf.cast(tf.equal(argmax_click, argmax_disp), tf.float32))
precision_1 = precision_1_sum / event_cnt
precision_2_sum = tf.reduce_sum(tf.cast(tf.equal(tf.reshape(argmax_click, [-1, 1]), tf.cast(top_2_disp, tf.int64)), tf.float32))
precision_2 = precision_2_sum / event_cnt
self.lossL2 = tf.add_n([tf.nn.l2_loss(v) for v in tf.trainable_variables() if 'bias' not in v.name]) * 0.05 # regularity
return loss, precision_1, precision_2, loss_sum, precision_1_sum, precision_2_sum, event_cnt
def construct_model(self, is_training, reuse=False):
global lossL2
with tf.variable_scope('model', reuse=reuse):
loss, precision_1, precision_2, loss_sum, precision_1_sum, precision_2_sum, event_cnt = self.construct_computation_graph()
if is_training:
global_step = tf.Variable(0, trainable=False)
learning_rate = tf.train.exponential_decay(self.lr, global_step, 100000, 0.96, staircase=True)
opt = tf.train.AdamOptimizer(learning_rate=learning_rate)
train_op = opt.minimize(loss, global_step=global_step)
return train_op, loss, precision_1, precision_2, loss_sum, precision_1_sum, precision_2_sum, event_cnt
else:
return loss, precision_1, precision_2, loss_sum, precision_1_sum, precision_2_sum, event_cnt
GA User Model with Shannon Entropy¶
def multithread_compute_vali():
global vali_sum, vali_cnt
vali_sum = [0.0, 0.0, 0.0]
vali_cnt = 0
threads = []
for ii in range(cmd_args.num_thread):
thread = threading.Thread(target=vali_eval, args=(1, ii))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()
return vali_sum[0]/vali_cnt, vali_sum[1]/vali_cnt, vali_sum[2]/vali_cnt
lock = threading.Lock()
def vali_eval(xx, ii):
global vali_sum, vali_cnt
if cmd_args.user_model == 'LSTM':
vali_thread_eval = sess.run([train_loss_sum, train_prec1_sum, train_prec2_sum, train_event_cnt], feed_dict={user_model.placeholder['clicked_feature']: click_feature_vali[ii],
user_model.placeholder['ut_dispid_feature']: u_t_dispid_feature_vali[ii],
user_model.placeholder['ut_dispid_ut']: np.array(u_t_dispid_split_ut_vali[ii], dtype=np.int64),
user_model.placeholder['ut_dispid']: np.array(u_t_dispid_vali[ii], dtype=np.int64),
user_model.placeholder['ut_clickid']: np.array(u_t_clickid_vali[ii], dtype=np.int64),
user_model.placeholder['ut_clickid_val']: np.ones(len(u_t_clickid_vali[ii]), dtype=np.float32),
user_model.placeholder['click_sublist_index']: np.array(click_sub_index_vali[ii], dtype=np.int64),
user_model.placeholder['ut_dense']: ut_dense_vali[ii],
user_model.placeholder['time']: max_time_vali[ii],
user_model.placeholder['item_size']: news_cnt_short_vali[ii]
})
elif cmd_args.user_model == 'PW':
vali_thread_eval = sess.run([train_loss_sum, train_prec1_sum, train_prec2_sum, train_event_cnt],
feed_dict={user_model.placeholder['disp_current_feature']: feature_vali[ii],
user_model.placeholder['item_size']: news_cnt_short_vali[ii],
user_model.placeholder['section_length']: sec_cnt_vali[ii],
user_model.placeholder['click_indices']: np.array(click_2d_vali[ii]),
user_model.placeholder['click_values']: np.ones(len(click_2d_vali[ii]), dtype=np.float32),
user_model.placeholder['disp_indices']: np.array(disp_2d_vali[ii]),
user_model.placeholder['cumsum_tril_indices']: tril_ind_vali[ii],
user_model.placeholder['cumsum_tril_value_indices']: np.array(tril_value_ind_vali[ii], dtype=np.int64),
user_model.placeholder['click_2d_subindex']: click_sub_index_2d_vali[ii],
user_model.placeholder['disp_2d_split_sec_ind']: disp_2d_split_sec_vali[ii],
user_model.placeholder['Xs_clicked']: feature_clicked_vali[ii]})
lock.acquire()
vali_sum[0] += vali_thread_eval[0]
vali_sum[1] += vali_thread_eval[1]
vali_sum[2] += vali_thread_eval[2]
vali_cnt += vali_thread_eval[3]
lock.release()
def multithread_compute_test():
global test_sum, test_cnt
num_sets = 1 * cmd_args.num_thread
thread_dist = [[] for _ in range(cmd_args.num_thread)]
for ii in range(num_sets):
thread_dist[ii % cmd_args.num_thread].append(ii)
test_sum = [0.0, 0.0, 0.0]
test_cnt = 0
threads = []
for ii in range(cmd_args.num_thread):
thread = threading.Thread(target=test_eval, args=(1, thread_dist[ii]))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()
return test_sum[0]/test_cnt, test_sum[1]/test_cnt, test_sum[2]/test_cnt
def test_eval(xx, thread_dist):
global test_sum, test_cnt
test_thread_eval = [0.0, 0.0, 0.0]
test_thread_cnt = 0
for ii in thread_dist:
if cmd_args.user_model == 'LSTM':
test_set_eval = sess.run([train_loss_sum, train_prec1_sum, train_prec2_sum, train_event_cnt], feed_dict={user_model.placeholder['clicked_feature']: click_feature_test[ii],
user_model.placeholder['ut_dispid_feature']: u_t_dispid_feature_test[ii],
user_model.placeholder['ut_dispid_ut']: np.array(u_t_dispid_split_ut_test[ii], dtype=np.int64),
user_model.placeholder['ut_dispid']: np.array(u_t_dispid_test[ii], dtype=np.int64),
user_model.placeholder['ut_clickid']: np.array(u_t_clickid_test[ii], dtype=np.int64),
user_model.placeholder['ut_clickid_val']: np.ones(len(u_t_clickid_test[ii]), dtype=np.float32),
user_model.placeholder['click_sublist_index']: np.array(click_sub_index_test[ii], dtype=np.int64),
user_model.placeholder['ut_dense']: ut_dense_test[ii],
user_model.placeholder['time']: max_time_test[ii],
user_model.placeholder['item_size']: news_cnt_short_test[ii]
})
elif cmd_args.user_model == 'PW':
test_set_eval = sess.run([train_loss_sum, train_prec1_sum, train_prec2_sum, train_event_cnt],
feed_dict={user_model.placeholder['disp_current_feature']: feature_test[ii],
user_model.placeholder['item_size']: news_cnt_short_test[ii],
user_model.placeholder['section_length']: sec_cnt_test[ii],
user_model.placeholder['click_indices']: np.array(click_2d_test[ii]),
user_model.placeholder['click_values']: np.ones(len(click_2d_test[ii]), dtype=np.float32),
user_model.placeholder['disp_indices']: np.array(disp_2d_test[ii]),
user_model.placeholder['cumsum_tril_indices']: tril_ind_test[ii],
user_model.placeholder['cumsum_tril_value_indices']: np.array(tril_value_ind_test[ii], dtype=np.int64),
user_model.placeholder['click_2d_subindex']: click_sub_index_2d_test[ii],
user_model.placeholder['disp_2d_split_sec_ind']: disp_2d_split_sec_test[ii],
user_model.placeholder['Xs_clicked']: feature_clicked_test[ii]})
test_thread_eval[0] += test_set_eval[0]
test_thread_eval[1] += test_set_eval[1]
test_thread_eval[2] += test_set_eval[2]
test_thread_cnt += test_set_eval[3]
lock.acquire()
test_sum[0] += test_thread_eval[0]
test_sum[1] += test_thread_eval[1]
test_sum[2] += test_thread_eval[2]
test_cnt += test_thread_cnt
lock.release()
if __name__ == '__main__':
log_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("%s, start" % log_time)
dataset = Dataset(cmd_args)
if cmd_args.resplit:
dataset.random_split_user()
log_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("%s, load data completed" % log_time)
log_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("%s, start to construct graph" % log_time)
if cmd_args.user_model == 'LSTM':
user_model = UserModelLSTM(dataset.f_dim, cmd_args)
elif cmd_args.user_model == 'PW':
user_model = UserModelPW(dataset.f_dim, cmd_args)
else:
print('using LSTM user model instead.')
user_model = UserModelLSTM(dataset.f_dim, cmd_args)
user_model.construct_placeholder()
train_opt, train_loss, train_prec1, train_prec2, train_loss_sum, train_prec1_sum, train_prec2_sum, train_event_cnt = user_model.construct_model(is_training=True, reuse=False)
log_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("%s, graph completed" % log_time)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
# prepare validation data
log_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("%s, start prepare vali data" % log_time)
if cmd_args.user_model == 'LSTM':
vali_thread_user, size_user_vali, max_time_vali, news_cnt_short_vali, u_t_dispid_vali, \
u_t_dispid_split_ut_vali, u_t_dispid_feature_vali, click_feature_vali, click_sub_index_vali, \
u_t_clickid_vali, ut_dense_vali = dataset.prepare_validation_data(cmd_args.num_thread, dataset.vali_user)
elif cmd_args.user_model == 'PW':
vali_thread_user, click_2d_vali, disp_2d_vali, \
feature_vali, sec_cnt_vali, tril_ind_vali, tril_value_ind_vali, disp_2d_split_sec_vali, \
news_cnt_short_vali, click_sub_index_2d_vali, feature_clicked_vali = dataset.prepare_validation_data(cmd_args.num_thread, dataset.vali_user)
else:
vali_thread_user, size_user_vali, max_time_vali, news_cnt_short_vali, u_t_dispid_vali, \
u_t_dispid_split_ut_vali, u_t_dispid_feature_vali, click_feature_vali, click_sub_index_vali, \
u_t_clickid_vali, ut_dense_vali = dataset.prepare_validation_data(cmd_args.num_thread, dataset.vali_user)
log_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("%s, prepare validation data, completed" % log_time)
best_metric = [100000.0, 0.0, 0.0]
vali_path = cmd_args.save_dir+'/'
if not os.path.exists(vali_path):
os.makedirs(vali_path)
saver = tf.train.Saver(max_to_keep=None)
for i in range(cmd_args.num_itrs):
# training_start_point = (i * cmd_args.batch_size) % (len(dataset.train_user))
# training_user = dataset.train_user[training_start_point: min(training_start_point + cmd_args.batch_size, len(dataset.train_user))]
training_user = np.random.choice(dataset.train_user, cmd_args.batch_size, replace=False)
if cmd_args.user_model == 'LSTM':
size_user_tr, max_time_tr, news_cnt_short_tr, u_t_dispid_tr, u_t_dispid_split_ut_tr, \
u_t_dispid_feature_tr, click_feature_tr, click_sub_index_tr, u_t_clickid_tr, ut_dense_tr = dataset.data_process_for_placeholder(training_user)
sess.run(train_opt, feed_dict={user_model.placeholder['clicked_feature']: click_feature_tr,
user_model.placeholder['ut_dispid_feature']: u_t_dispid_feature_tr,
user_model.placeholder['ut_dispid_ut']: np.array(u_t_dispid_split_ut_tr, dtype=np.int64),
user_model.placeholder['ut_dispid']: np.array(u_t_dispid_tr, dtype=np.int64),
user_model.placeholder['ut_clickid']: np.array(u_t_clickid_tr, dtype=np.int64),
user_model.placeholder['ut_clickid_val']: np.ones(len(u_t_clickid_tr), dtype=np.float32),
user_model.placeholder['click_sublist_index']: np.array(click_sub_index_tr, dtype=np.int64),
user_model.placeholder['ut_dense']: ut_dense_tr,
user_model.placeholder['time']: max_time_tr,
user_model.placeholder['item_size']: news_cnt_short_tr
})
elif cmd_args.user_model == 'PW':
click_2d, disp_2d, feature_tr, sec_cnt, tril_ind, tril_value_ind, disp_2d_split_sect, \
news_cnt_sht, click_2d_subind, feature_clicked_tr = dataset.data_process_for_placeholder(training_user)
sess.run(train_opt, feed_dict={user_model.placeholder['disp_current_feature']: feature_tr,
user_model.placeholder['item_size']: news_cnt_sht,
user_model.placeholder['section_length']: sec_cnt,
user_model.placeholder['click_indices']: click_2d,
user_model.placeholder['click_values']: np.ones(len(click_2d), dtype=np.float32),
user_model.placeholder['disp_indices']: np.array(disp_2d),
user_model.placeholder['cumsum_tril_indices']: tril_ind,
user_model.placeholder['cumsum_tril_value_indices']: np.array(tril_value_ind, dtype=np.int64),
user_model.placeholder['click_2d_subindex']: click_2d_subind,
user_model.placeholder['disp_2d_split_sec_ind']: disp_2d_split_sect,
user_model.placeholder['Xs_clicked']: feature_clicked_tr})
if np.mod(i, 10) == 0:
if i == 0:
log_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("%s, start first iteration validation" % log_time)
vali_loss_prc = multithread_compute_vali()
if i == 0:
log_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("%s, first iteration validation complete" % log_time)
log_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("%s: itr%d, vali: %.5f, %.5f, %.5f" %
(log_time, i, vali_loss_prc[0], vali_loss_prc[1], vali_loss_prc[2]))
if vali_loss_prc[0] < best_metric[0]:
best_metric[0] = vali_loss_prc[0]
best_save_path = os.path.join(vali_path, 'best-loss')
best_save_path = saver.save(sess, best_save_path)
if vali_loss_prc[1] > best_metric[1]:
best_metric[1] = vali_loss_prc[1]
best_save_path = os.path.join(vali_path, 'best-pre1')
best_save_path = saver.save(sess, best_save_path)
if vali_loss_prc[2] > best_metric[2]:
best_metric[2] = vali_loss_prc[2]
best_save_path = os.path.join(vali_path, 'best-pre2')
best_save_path = saver.save(sess, best_save_path)
log_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("%s, iteration %d train complete" % (log_time, i))
# test
log_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("%s, start prepare test data" % log_time)
if cmd_args.user_model == 'LSTM':
test_thread_user, size_user_test, max_time_test, news_cnt_short_test, u_t_dispid_test, \
u_t_dispid_split_ut_test, u_t_dispid_feature_test, click_feature_test, click_sub_index_test, \
u_t_clickid_test, ut_dense_test = dataset.prepare_validation_data(cmd_args.num_thread, dataset.test_user)
elif cmd_args.user_model == 'PW':
test_thread_user, click_2d_test, disp_2d_test, \
feature_test, sec_cnt_test, tril_ind_test, tril_value_ind_test, disp_2d_split_sec_test, \
news_cnt_short_test, click_sub_index_2d_test, feature_clicked_test = dataset.prepare_validation_data(cmd_args.num_thread, dataset.test_user)
log_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("%s, prepare test data end" % log_time)
best_save_path = os.path.join(vali_path, 'best-loss')
saver.restore(sess, best_save_path)
test_loss_prc = multithread_compute_test()
vali_loss_prc = multithread_compute_vali()
print("test!!!loss!!!, test: %.5f, vali: %.5f" % (test_loss_prc[0], vali_loss_prc[0]))
best_save_path = os.path.join(vali_path, 'best-pre1')
saver.restore(sess, best_save_path)
test_loss_prc = multithread_compute_test()
vali_loss_prc = multithread_compute_vali()
print("test!!!pre1!!!, test: %.5f, vali: %.5f" % (test_loss_prc[1], vali_loss_prc[1]))
best_save_path = os.path.join(vali_path, 'best-pre2')
saver.restore(sess, best_save_path)
test_loss_prc = multithread_compute_test()
vali_loss_prc = multithread_compute_vali()
print("test!!!pre2!!!, test: %.5f, vali: %.5f" % (test_loss_prc[2], vali_loss_prc[2]))
2021-10-21 06:28:28, iteration 1988 train complete
2021-10-21 06:28:28, iteration 1989 train complete
2021-10-21 06:28:28: itr1990, vali: nan, 0.00000, 0.38031
2021-10-21 06:28:28, iteration 1990 train complete
2021-10-21 06:28:28, iteration 1991 train complete
2021-10-21 06:28:28, iteration 1992 train complete
2021-10-21 06:28:28, iteration 1993 train complete
2021-10-21 06:28:28, iteration 1994 train complete
2021-10-21 06:28:28, iteration 1995 train complete
2021-10-21 06:28:28, iteration 1996 train complete
2021-10-21 06:28:28, iteration 1997 train complete
2021-10-21 06:28:28, iteration 1998 train complete
2021-10-21 06:28:28, iteration 1999 train complete
2021-10-21 06:28:28, start prepare test data
2021-10-21 06:28:28, prepare test data end
INFO:tensorflow:Restoring parameters from ./scratch/best-loss
test!!!loss!!!, test: 0.93315, vali: 0.98756
INFO:tensorflow:Restoring parameters from ./scratch/best-pre1
test!!!pre1!!!, test: 0.74828, vali: 0.67562
INFO:tensorflow:Restoring parameters from ./scratch/best-pre2
test!!!pre2!!!, test: 0.87643, vali: 0.84340
GA User Model with L2 Regularization¶
We trained the user model using Shannon Entropy. With this saved model as an initilization, we can continue to train the model using other regularizations. For example, L2.
cmd_args.num_thread = 10
cmd_args.rnn_hidden_dim = 20
cmd_args.learning_rate = 0.0005
cmd_args.batch_size = 50
cmd_args.num_itrs = 5000
cmd_args.resplit = False
cmd_args.pw_dim = 4
def multithread_compute_vali():
global vali_sum, vali_cnt
vali_sum = [0.0, 0.0, 0.0, 0.0]
vali_cnt = 0
threads = []
for ii in range(cmd_args.num_thread):
thread = threading.Thread(target=vali_eval, args=(1, ii))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()
return vali_sum[0]/vali_cnt, vali_sum[1]/vali_cnt, vali_sum[2]/vali_cnt, vali_sum[3]/vali_cnt
def vali_eval(xx, ii):
global vali_sum, vali_cnt
vali_thread_eval = sess.run([train_loss_min_sum, train_loss_max_sum, train_prec1_sum, train_prec2_sum, train_event_cnt],
feed_dict={user_model.placeholder['clicked_feature']: click_feature_vali[ii],
user_model.placeholder['ut_dispid_feature']: u_t_dispid_feature_vali[ii],
user_model.placeholder['ut_dispid_ut']: np.array(u_t_dispid_split_ut_vali[ii], dtype=np.int64),
user_model.placeholder['ut_dispid']: np.array(u_t_dispid_vali[ii], dtype=np.int64),
user_model.placeholder['ut_clickid']: np.array(u_t_clickid_vali[ii], dtype=np.int64),
user_model.placeholder['ut_clickid_val']: np.ones(len(u_t_clickid_vali[ii]), dtype=np.float32),
user_model.placeholder['click_sublist_index']: np.array(click_sub_index_vali[ii], dtype=np.int64),
user_model.placeholder['ut_dense']: ut_dense_vali[ii],
user_model.placeholder['time']: max_time_vali[ii],
user_model.placeholder['item_size']: news_cnt_short_vali[ii]
})
lock.acquire()
vali_sum[0] += vali_thread_eval[0]
vali_sum[1] += vali_thread_eval[1]
vali_sum[2] += vali_thread_eval[2]
vali_sum[3] += vali_thread_eval[3]
vali_cnt += vali_thread_eval[4]
lock.release()
def multithread_compute_test():
global test_sum, test_cnt
num_sets = cmd_args.num_thread
thread_dist = [[] for _ in range(cmd_args.num_thread)]
for ii in range(num_sets):
thread_dist[ii % cmd_args.num_thread].append(ii)
test_sum = [0.0, 0.0, 0.0, 0.0]
test_cnt = 0
threads = []
for ii in range(cmd_args.num_thread):
thread = threading.Thread(target=test_eval, args=(1, thread_dist[ii]))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()
return test_sum[0]/test_cnt, test_sum[1]/test_cnt, test_sum[2]/test_cnt, test_sum[3]/test_cnt
def test_eval(xx, thread_dist):
global test_sum, test_cnt
test_thread_eval = [0.0, 0.0, 0.0, 0.0]
test_thread_cnt = 0
for ii in thread_dist:
test_set_eval = sess.run([train_loss_min_sum, train_loss_max_sum, train_prec1_sum, train_prec2_sum, train_event_cnt],
feed_dict={user_model.placeholder['clicked_feature']: click_feature_test[ii],
user_model.placeholder['ut_dispid_feature']: u_t_dispid_feature_test[ii],
user_model.placeholder['ut_dispid_ut']: np.array(u_t_dispid_split_ut_test[ii], dtype=np.int64),
user_model.placeholder['ut_dispid']: np.array(u_t_dispid_test[ii], dtype=np.int64),
user_model.placeholder['ut_clickid']: np.array(u_t_clickid_test[ii], dtype=np.int64),
user_model.placeholder['ut_clickid_val']: np.ones(len(u_t_clickid_test[ii]), dtype=np.float32),
user_model.placeholder['click_sublist_index']: np.array(click_sub_index_test[ii], dtype=np.int64),
user_model.placeholder['ut_dense']: ut_dense_test[ii],
user_model.placeholder['time']: max_time_test[ii],
user_model.placeholder['item_size']: news_cnt_short_test[ii]
})
test_thread_eval[0] += test_set_eval[0]
test_thread_eval[1] += test_set_eval[1]
test_thread_eval[2] += test_set_eval[2]
test_thread_eval[3] += test_set_eval[3]
test_thread_cnt += test_set_eval[4]
lock.acquire()
test_sum[0] += test_thread_eval[0]
test_sum[1] += test_thread_eval[1]
test_sum[2] += test_thread_eval[2]
test_sum[3] += test_thread_eval[3]
test_cnt += test_thread_cnt
lock.release()
lock = threading.Lock()
if __name__ == '__main__':
log_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("%s, start" % log_time)
dataset = Dataset(cmd_args)
log_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("%s, start construct graph" % log_time)
# restore pre-trained u function
user_model = UserModelLSTM(dataset.f_dim, cmd_args, dataset.max_disp_size)
user_model.construct_placeholder()
with tf.variable_scope('model', reuse=False):
user_model.construct_computation_graph_u()
saved_path = cmd_args.save_dir+'/'
saver = tf.train.Saver(max_to_keep=None)
sess = tf.Session()
sess.run(tf.variables_initializer(user_model.min_trainable_variables))
best_save_path = os.path.join(saved_path, 'best-pre1')
saver.restore(sess, best_save_path)
# construct policy net
train_min_opt, train_max_opt, train_loss_min, train_loss_max, train_prec1, train_prec2, train_loss_min_sum, \
train_loss_max_sum, train_prec1_sum, train_prec2_sum, train_event_cnt = user_model.construct_computation_graph_policy()
sess.run(tf.initialize_variables(user_model.init_variables))
log_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("%s, graph completed" % log_time)
batch_size = 100
batch = 100
if cmd_args.dataset == 'lastfm':
batch_size = 10
batch = 10
iterations = cmd_args.num_itrs
# prepare validation data
log_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("%s, start prepare vali data" % log_time)
vali_thread_user, size_user_vali, max_time_vali, news_cnt_short_vali, u_t_dispid_vali, \
u_t_dispid_split_ut_vali, u_t_dispid_feature_vali, click_feature_vali, click_sub_index_vali, \
u_t_clickid_vali, ut_dense_vali = dataset.prepare_validation_data_L2(cmd_args.num_thread, dataset.vali_user)
log_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("%s, prepare vali data complete" % log_time)
best_metric = [0.0, 0.0, 0.0, 0.0]
saver = tf.train.Saver(max_to_keep=None)
vali_path = cmd_args.save_dir+'/minmax_L2/'
if not os.path.exists(vali_path):
os.makedirs(vali_path)
for i in range(iterations):
training_user = np.random.choice(len(dataset.train_user), batch, replace=False)
if i == 0:
log_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("%s, start prepare train data" % log_time)
size_user_tr, max_time_tr, news_cnt_short_tr, u_t_dispid_tr, u_t_dispid_split_ut_tr, \
u_t_dispid_feature_tr, click_feature_tr, click_sub_index_tr, u_t_clickid_tr, ut_dense_tr = dataset.data_process_for_placeholder_L2(training_user)
if i == 0:
log_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("%s, prepare train data completed" % log_time)
print("%s, start first iteration training" % log_time)
sess.run(train_max_opt, feed_dict={user_model.placeholder['clicked_feature']: click_feature_tr,
user_model.placeholder['ut_dispid_feature']: u_t_dispid_feature_tr,
user_model.placeholder['ut_dispid_ut']: np.array(u_t_dispid_split_ut_tr, dtype=np.int64),
user_model.placeholder['ut_dispid']: np.array(u_t_dispid_tr, dtype=np.int64),
user_model.placeholder['ut_clickid']: np.array(u_t_clickid_tr, dtype=np.int64),
user_model.placeholder['ut_clickid_val']: np.ones(len(u_t_clickid_tr), dtype=np.float32),
user_model.placeholder['click_sublist_index']: np.array(click_sub_index_tr, dtype=np.int64),
user_model.placeholder['ut_dense']: ut_dense_tr,
user_model.placeholder['time']: max_time_tr,
user_model.placeholder['item_size']: news_cnt_short_tr
})
if i == 0:
log_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("%s, first iteration training complete" % log_time)
if np.mod(i, 100) == 0:
loss_prc = sess.run([train_loss_min, train_loss_max, train_prec1, train_prec2], feed_dict={user_model.placeholder['clicked_feature']: click_feature_tr,
user_model.placeholder['ut_dispid_feature']: u_t_dispid_feature_tr,
user_model.placeholder['ut_dispid_ut']: np.array(u_t_dispid_split_ut_tr, dtype=np.int64),
user_model.placeholder['ut_dispid']: np.array(u_t_dispid_tr, dtype=np.int64),
user_model.placeholder['ut_clickid']: np.array(u_t_clickid_tr, dtype=np.int64),
user_model.placeholder['ut_clickid_val']: np.ones(len(u_t_clickid_tr), dtype=np.float32),
user_model.placeholder['click_sublist_index']: np.array(click_sub_index_tr, dtype=np.int64),
user_model.placeholder['ut_dense']: ut_dense_tr,
user_model.placeholder['time']: max_time_tr,
user_model.placeholder['item_size']: news_cnt_short_tr
})
if i == 0:
log_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("%s, start first iteration validation" % log_time)
vali_loss_prc = multithread_compute_vali()
if i == 0:
log_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("%s, first iteration validation complete" % log_time)
log_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("%s: itr%d, training: %.5f, %.5f, %.5f, %.5f, vali: %.5f, %.5f, %.5f, %.5f" %
(log_time, i, loss_prc[0], loss_prc[1], loss_prc[2], loss_prc[3], vali_loss_prc[0], vali_loss_prc[1], vali_loss_prc[2], vali_loss_prc[3]))
if vali_loss_prc[2] > best_metric[2]:
best_metric[2] = vali_loss_prc[2]
best_save_path = os.path.join(vali_path, 'best-pre1')
best_save_path = saver.save(sess, best_save_path)
if vali_loss_prc[3] > best_metric[3]:
best_metric[3] = vali_loss_prc[3]
best_save_path = os.path.join(vali_path, 'best-pre2')
best_save_path = saver.save(sess, best_save_path)
save_path = os.path.join(vali_path, 'most_recent_iter')
save_path = saver.save(sess, save_path)
# test
log_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("%s, start prepare test data" % log_time)
test_thread_user, size_user_test, max_time_test, news_cnt_short_test, u_t_dispid_test, \
u_t_dispid_split_ut_test, u_t_dispid_feature_test, click_feature_test, click_sub_index_test, \
u_t_clickid_test, ut_dense_test = dataset.prepare_validation_data_L2(cmd_args.num_thread, dataset.test_user)
log_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("%s, prepare test data end" % log_time)
best_save_path = os.path.join(vali_path, 'best-pre1')
saver.restore(sess, best_save_path)
test_loss_prc = multithread_compute_test()
vali_loss_prc = multithread_compute_vali()
print("test!!!best-pre1!!!, test: %.5f, vali: %.5f" % (test_loss_prc[2], vali_loss_prc[2]))
best_save_path = os.path.join(vali_path, 'best-pre2')
saver.restore(sess, best_save_path)
test_loss_prc = multithread_compute_test()
vali_loss_prc = multithread_compute_vali()
print("test!!!best-pre2!!!, test: %.5f, vali: %.5f" % (test_loss_prc[3], vali_loss_prc[3]))
2021-10-21 06:37:12, start
2021-10-21 06:37:12, start construct graph
WARNING:tensorflow:
The TensorFlow contrib module will not be included in TensorFlow 2.0.
For more information, please see:
* https://github.com/tensorflow/community/blob/master/rfcs/20180907-contrib-sunset.md
* https://github.com/tensorflow/addons
* https://github.com/tensorflow/io (for I/O related ops)
If you depend on functionality not listed there, please file an issue.
WARNING:tensorflow:From <ipython-input-5-6cf3a6077dba>:95: BasicLSTMCell.__init__ (from tensorflow.python.ops.rnn_cell_impl) is deprecated and will be removed in a future version.
Instructions for updating:
This class is equivalent as tf.keras.layers.LSTMCell, and will be replaced by that in Tensorflow 2.0.
WARNING:tensorflow:From <ipython-input-5-6cf3a6077dba>:97: dynamic_rnn (from tensorflow.python.ops.rnn) is deprecated and will be removed in a future version.
Instructions for updating:
Please use `keras.layers.RNN(cell)`, which is equivalent to this API
WARNING:tensorflow:From /tensorflow-1.15.2/python3.7/tensorflow_core/python/ops/rnn_cell_impl.py:735: Layer.add_variable (from tensorflow.python.keras.engine.base_layer) is deprecated and will be removed in a future version.
Instructions for updating:
Please use `layer.add_weight` method instead.
WARNING:tensorflow:From /tensorflow-1.15.2/python3.7/tensorflow_core/python/ops/rnn_cell_impl.py:739: calling Zeros.__init__ (from tensorflow.python.ops.init_ops) with dtype is deprecated and will be removed in a future version.
Instructions for updating:
Call initializer instance with the dtype argument instead of passing it to the constructor
WARNING:tensorflow:From <ipython-input-5-6cf3a6077dba>:5: dense (from tensorflow.python.layers.core) is deprecated and will be removed in a future version.
Instructions for updating:
Use keras.layers.Dense instead.
WARNING:tensorflow:From /tensorflow-1.15.2/python3.7/tensorflow_core/python/layers/core.py:187: Layer.apply (from tensorflow.python.keras.engine.base_layer) is deprecated and will be removed in a future version.
Instructions for updating:
Please use `layer.__call__` method instead.
INFO:tensorflow:Restoring parameters from ./scratch/best-pre1
WARNING:tensorflow:From <ipython-input-5-6cf3a6077dba>:152: sparse_to_dense (from tensorflow.python.ops.sparse_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Create a `tf.sparse.SparseTensor` and use `tf.sparse.to_dense` instead.
/tensorflow-1.15.2/python3.7/tensorflow_core/python/framework/indexed_slices.py:424: UserWarning: Converting sparse IndexedSlices to a dense Tensor of unknown shape. This may consume a large amount of memory.
"Converting sparse IndexedSlices to a dense Tensor of unknown shape. "
WARNING:tensorflow:From /tensorflow-1.15.2/python3.7/tensorflow_core/python/util/tf_should_use.py:198: initialize_variables (from tensorflow.python.ops.variables) is deprecated and will be removed after 2017-03-02.
Instructions for updating:
Use `tf.variables_initializer` instead.
2021-10-21 06:37:15, graph completed
2021-10-21 06:37:15, start prepare vali data
2021-10-21 06:37:15, prepare vali data complete
2021-10-21 06:37:15, start prepare train data
2021-10-21 06:37:15, prepare train data completed
2021-10-21 06:37:15, start first iteration training
2021-10-21 06:37:16, first iteration training complete
2021-10-21 06:37:16, start first iteration validation
2021-10-21 06:37:16, first iteration validation complete
2021-10-21 06:37:16: itr0, training: -14.55946, 3.87918, 0.18033, 0.45082, vali: -11.21879, 5.44785, 0.17002, 0.37808
INFO:tensorflow:./scratch/minmax_L2/best-pre1 is not in all_model_checkpoint_paths. Manually adding it.
INFO:tensorflow:./scratch/minmax_L2/best-pre2 is not in all_model_checkpoint_paths. Manually adding it.
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:37:20: itr100, training: -6.27841, 12.41326, 0.70588, 0.84874, vali: -3.43435, 13.23230, 0.48770, 0.69799
INFO:tensorflow:./scratch/minmax_L2/best-pre1 is not in all_model_checkpoint_paths. Manually adding it.
INFO:tensorflow:./scratch/minmax_L2/best-pre2 is not in all_model_checkpoint_paths. Manually adding it.
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:37:24: itr200, training: -1.83261, 15.74864, 0.84426, 0.97541, vali: 0.62875, 17.29540, 0.58389, 0.78971
INFO:tensorflow:./scratch/minmax_L2/best-pre1 is not in all_model_checkpoint_paths. Manually adding it.
INFO:tensorflow:./scratch/minmax_L2/best-pre2 is not in all_model_checkpoint_paths. Manually adding it.
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:37:28: itr300, training: -0.86641, 17.90119, 0.96000, 0.99200, vali: 1.22508, 17.89172, 0.62416, 0.80537
INFO:tensorflow:./scratch/minmax_L2/best-pre1 is not in all_model_checkpoint_paths. Manually adding it.
INFO:tensorflow:./scratch/minmax_L2/best-pre2 is not in all_model_checkpoint_paths. Manually adding it.
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:37:32: itr400, training: -0.76307, 18.72485, 0.93333, 0.97500, vali: 1.40389, 18.07054, 0.63982, 0.81208
INFO:tensorflow:./scratch/minmax_L2/best-pre1 is not in all_model_checkpoint_paths. Manually adding it.
INFO:tensorflow:./scratch/minmax_L2/best-pre2 is not in all_model_checkpoint_paths. Manually adding it.
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:37:35: itr500, training: -0.65650, 18.61495, 0.97500, 0.98333, vali: 1.49072, 18.15737, 0.64206, 0.81208
INFO:tensorflow:./scratch/minmax_L2/best-pre1 is not in all_model_checkpoint_paths. Manually adding it.
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:37:39: itr600, training: -0.58195, 17.94368, 0.97345, 1.00000, vali: 1.55703, 18.22368, 0.65324, 0.81208
INFO:tensorflow:./scratch/minmax_L2/best-pre1 is not in all_model_checkpoint_paths. Manually adding it.
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:37:43: itr700, training: -0.59892, 18.28909, 0.96667, 0.99167, vali: 1.59338, 18.26002, 0.65324, 0.81208
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:37:46: itr800, training: -0.57403, 20.35625, 0.96581, 0.98291, vali: 1.61140, 18.27805, 0.65324, 0.81208
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:37:50: itr900, training: -0.54096, 18.27187, 0.99206, 1.00000, vali: 1.62315, 18.28980, 0.65324, 0.81208
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:37:53: itr1000, training: -0.54646, 19.26600, 0.98246, 0.99123, vali: 1.63227, 18.29892, 0.65548, 0.81208
INFO:tensorflow:./scratch/minmax_L2/best-pre1 is not in all_model_checkpoint_paths. Manually adding it.
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:37:57: itr1100, training: -0.57691, 18.21611, 0.98361, 0.98361, vali: 1.63925, 18.30590, 0.65996, 0.81208
INFO:tensorflow:./scratch/minmax_L2/best-pre1 is not in all_model_checkpoint_paths. Manually adding it.
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:38:00: itr1200, training: -0.54024, 17.75560, 0.98374, 1.00000, vali: 1.64636, 18.31301, 0.65772, 0.81208
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:38:04: itr1300, training: -0.60761, 17.55147, 0.95495, 0.96396, vali: 1.65015, 18.31680, 0.65996, 0.81208
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:38:08: itr1400, training: -0.57991, 19.36499, 0.98198, 0.99099, vali: 1.65279, 18.31944, 0.66219, 0.81432
INFO:tensorflow:./scratch/minmax_L2/best-pre1 is not in all_model_checkpoint_paths. Manually adding it.
INFO:tensorflow:./scratch/minmax_L2/best-pre2 is not in all_model_checkpoint_paths. Manually adding it.
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:38:11: itr1500, training: -0.52982, 17.18512, 0.98361, 0.99180, vali: 1.65443, 18.32107, 0.66219, 0.81655
INFO:tensorflow:./scratch/minmax_L2/best-pre2 is not in all_model_checkpoint_paths. Manually adding it.
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:38:15: itr1600, training: -0.55470, 18.16268, 0.96774, 0.97581, vali: 1.65577, 18.32242, 0.65996, 0.81655
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:38:18: itr1700, training: -0.60629, 19.20172, 0.95000, 0.95000, vali: 1.65788, 18.32453, 0.66443, 0.81655
INFO:tensorflow:./scratch/minmax_L2/best-pre1 is not in all_model_checkpoint_paths. Manually adding it.
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:38:22: itr1800, training: -0.57518, 18.65440, 0.96694, 0.97521, vali: 1.65932, 18.32597, 0.66219, 0.81879
INFO:tensorflow:./scratch/minmax_L2/best-pre2 is not in all_model_checkpoint_paths. Manually adding it.
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:38:26: itr1900, training: -0.53885, 17.52446, 0.98246, 0.99123, vali: 1.66100, 18.32764, 0.66219, 0.81879
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:38:29: itr2000, training: -0.53044, 18.90793, 0.97561, 0.98374, vali: 1.66162, 18.32827, 0.66219, 0.81879
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:38:33: itr2100, training: -0.56982, 18.14847, 0.97500, 0.98333, vali: 1.66299, 18.32964, 0.66219, 0.81879
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:38:36: itr2200, training: -0.57809, 18.67004, 0.98400, 0.98400, vali: 1.66416, 18.33081, 0.66219, 0.82103
INFO:tensorflow:./scratch/minmax_L2/best-pre2 is not in all_model_checkpoint_paths. Manually adding it.
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:38:40: itr2300, training: -0.54540, 18.55279, 0.98387, 0.99194, vali: 1.66503, 18.33168, 0.66219, 0.82327
INFO:tensorflow:./scratch/minmax_L2/best-pre2 is not in all_model_checkpoint_paths. Manually adding it.
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:38:44: itr2400, training: -0.52253, 18.11471, 0.97500, 0.99167, vali: 1.66578, 18.33243, 0.66219, 0.82327
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:38:47: itr2500, training: -0.52938, 18.34142, 0.96721, 0.96721, vali: 1.66572, 18.33237, 0.66219, 0.82327
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:38:51: itr2600, training: -0.52058, 19.54539, 0.97391, 0.98261, vali: 1.66563, 18.33228, 0.65996, 0.82327
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:38:54: itr2700, training: -0.57997, 18.05580, 0.97391, 0.99130, vali: 1.66636, 18.33301, 0.65772, 0.82327
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:38:58: itr2800, training: -0.50133, 18.18809, 1.00000, 1.00000, vali: 1.66667, 18.33332, 0.65996, 0.82327
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:39:01: itr2900, training: -0.56055, 19.66512, 0.96721, 0.97541, vali: 1.66686, 18.33351, 0.65772, 0.82550
INFO:tensorflow:./scratch/minmax_L2/best-pre2 is not in all_model_checkpoint_paths. Manually adding it.
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:39:05: itr3000, training: -0.63166, 18.27195, 0.95652, 0.97391, vali: 1.66745, 18.33410, 0.65772, 0.82550
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:39:09: itr3100, training: -0.50090, 19.38037, 1.00000, 1.00000, vali: 1.66824, 18.33489, 0.65996, 0.82550
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:39:12: itr3200, training: -0.54834, 18.32218, 0.97321, 0.98214, vali: 1.66819, 18.33483, 0.65996, 0.82550
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:39:16: itr3300, training: -0.52781, 17.53323, 0.98305, 1.00000, vali: 1.66775, 18.33440, 0.65996, 0.82550
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:39:19: itr3400, training: -0.53485, 18.05005, 0.99160, 0.99160, vali: 1.66780, 18.33445, 0.65772, 0.82327
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:39:23: itr3500, training: -0.58746, 18.00185, 0.96667, 0.97500, vali: 1.66792, 18.33457, 0.65996, 0.82327
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:39:26: itr3600, training: -0.56236, 18.55064, 0.96639, 0.97479, vali: 1.66786, 18.33451, 0.65772, 0.82327
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:39:30: itr3700, training: -0.51647, 19.16045, 0.99138, 0.99138, vali: 1.66722, 18.33387, 0.65772, 0.82327
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:39:33: itr3800, training: -0.53260, 17.48034, 0.99194, 0.99194, vali: 1.66652, 18.33317, 0.65772, 0.82327
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:39:37: itr3900, training: -0.56512, 17.70387, 0.96610, 0.98305, vali: 1.66638, 18.33303, 0.65772, 0.82327
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:39:40: itr4000, training: -0.58674, 17.74756, 0.97479, 0.98319, vali: 1.66625, 18.33290, 0.65772, 0.82327
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:39:44: itr4100, training: -0.52532, 19.45704, 0.97638, 0.97638, vali: 1.66553, 18.33218, 0.65772, 0.82327
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:39:48: itr4200, training: -0.62433, 17.74587, 0.95763, 0.97458, vali: 1.66537, 18.33202, 0.65772, 0.82327
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:39:51: itr4300, training: -0.60127, 17.62124, 0.96460, 0.96460, vali: 1.66495, 18.33160, 0.65772, 0.82327
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:39:54: itr4400, training: -0.54567, 19.30546, 0.96774, 0.97581, vali: 1.66376, 18.33041, 0.65772, 0.82103
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:39:58: itr4500, training: -0.52169, 18.79628, 0.99180, 0.99180, vali: 1.66256, 18.32921, 0.65772, 0.82103
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:40:01: itr4600, training: -0.58111, 18.74997, 0.96460, 0.98230, vali: 1.66171, 18.32836, 0.65772, 0.82103
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:40:05: itr4700, training: -0.52880, 19.17885, 0.99138, 0.99138, vali: 1.66046, 18.32711, 0.65772, 0.82103
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:40:09: itr4800, training: -0.49726, 18.17569, 0.97541, 0.99180, vali: 1.66002, 18.32667, 0.65996, 0.82103
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:40:13: itr4900, training: -0.51686, 18.48265, 0.99074, 0.99074, vali: 1.65879, 18.32544, 0.65772, 0.82103
INFO:tensorflow:./scratch/minmax_L2/most_recent_iter is not in all_model_checkpoint_paths. Manually adding it.
2021-10-21 06:40:16, start prepare test data
2021-10-21 06:40:16, prepare test data end
INFO:tensorflow:Restoring parameters from ./scratch/minmax_L2/best-pre1
test!!!best-pre1!!!, test: 0.72082, vali: 0.66443
INFO:tensorflow:Restoring parameters from ./scratch/minmax_L2/best-pre2
test!!!best-pre2!!!, test: 0.86041, vali: 0.82550
!apt-get install tree
!tree --du -h .
.
├── [ 20M] scratch
│ ├── [1.4M] best-loss.data-00000-of-00001
│ ├── [ 931] best-loss.index
│ ├── [205K] best-loss.meta
│ ├── [1.4M] best-pre1.data-00000-of-00001
│ ├── [ 931] best-pre1.index
│ ├── [205K] best-pre1.meta
│ ├── [1.4M] best-pre2.data-00000-of-00001
│ ├── [ 931] best-pre2.index
│ ├── [205K] best-pre2.meta
│ ├── [ 75] checkpoint
│ └── [ 15M] minmax_L2
│ ├── [4.7M] best-pre1.data-00000-of-00001
│ ├── [1.7K] best-pre1.index
│ ├── [369K] best-pre1.meta
│ ├── [4.7M] best-pre2.data-00000-of-00001
│ ├── [1.7K] best-pre2.index
│ ├── [369K] best-pre2.meta
│ ├── [ 89] checkpoint
│ ├── [4.7M] most_recent_iter.data-00000-of-00001
│ ├── [1.7K] most_recent_iter.index
│ └── [369K] most_recent_iter.meta
├── [5.0M] yelp.pkl
├── [3.9K] yelp-split.pkl
└── [443K] yelp.txt
25M used in 2 directories, 23 files