Netflix Personalize Images
The bandit can choose from a set of images for each show (i.e., action) and observe the number of minutes the user played the show after being impressed with the image (i.e., reward). It also has information about user attributes (e.g., titles played, genres played, country, language preferences), day of the week, time of day, etc. (i.e., context).
For offline evaluation of the bandit, they apply replay on the bandit’s predicted image and the random image shown during the exploration phase. They first get the bandit’s predicted image for each user-show pair. Then, they try to match it with the random images shown to users in the exploration phase. If the predicted image matches the randomly assigned image, that predicted-random match can be used for evaluation.
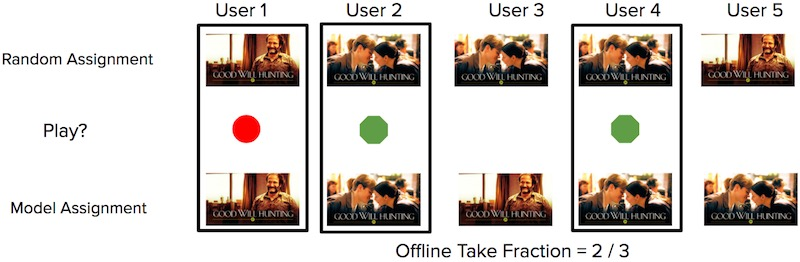
From the set of predicted-random matches, they check if the user played the title or not. The main metric of interest is the number of quality plays over the number of impressions (i.e., take fraction)—for the n images that were recommended, how many resulted in the user watching the show?
The benefit of replay is that it’s an unbiased metric when accounting for the probability of each image shown during exploration. Having the probability allows us to weigh the reward to control for bias in image display rates, either in exploration or production. (Also see this SIGIR tutorial on counterfactual evaluation) The downside is that it requires a lot of data, and there could be high variance in evaluation metrics if there are few matches between the predicted and random data. Nonetheless, techniques such as doubly robust estimation can help.