Huawei AppGallery

Recommender system consists of three modules: candidate selection, matching, and ranking. In the App Store, there exist tens or hundreds of thousands of apps. If all the apps are involved for recommendation, the latency is unacceptable in practice, because it takes time to predict the matching score between a user and all the apps. Therefore, the candidate selection module is needed to select several hundred apps from the universal set for each user. Then the matching module predicts the matching score between a user and the selected apps representing the user’s preference on them. Lastly, the ranking module produces the ranking list based on the matching scores and other principles (diversity and business rules).
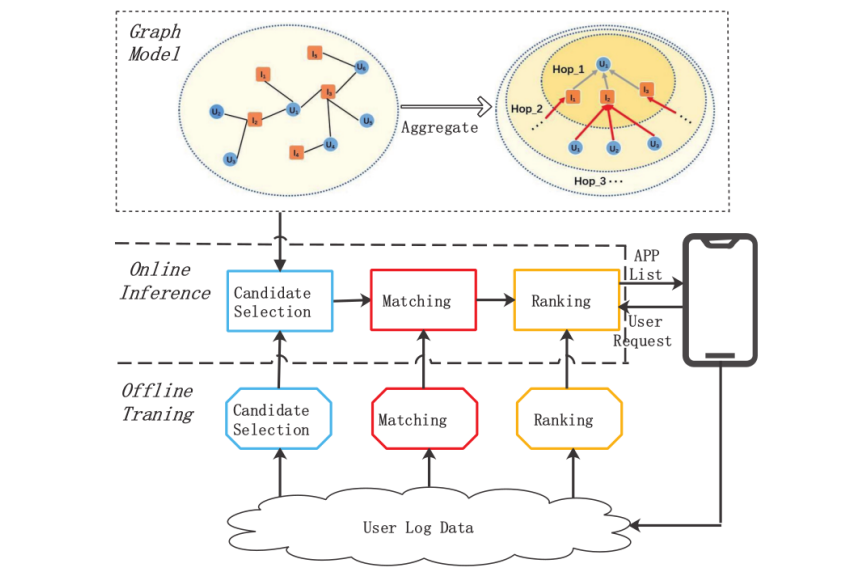
Pipeline of the APP recommendation system.
We sample and collect 22 consecutive days of user-app download records from the game recommendation scenario. A user-item bipartite graph is constructed based on the download records. Two types of nodes (user nodes and item nodes) exist and an edge between a user node and an item node is included if there is an associated download record. App features (e.g., identification and category) and user features (e.g., click/browse/search history) are used as node features in the graph. As can be observed from the figure above, a GCN model (i.e., a simplified version of MGCCF) has been deployed in the candidate selection module. MGCCF learns an embedding for each user as well as each item. Then, candidates for each user are generated by finding the most similar items by computing the similarity between user and item embedding. The model employed in the candidate selection module of our recommender system is trained on 14 days’ data, which is referred to as “batch mode”. Based on the collected 22 days’ data, we test the performance of “batch mode” in a sliding window manner. Specifically, days [T,T +13] of data are used for training, day T +14 of data is used for validation, and day T + 15 of data is for testing, where T ∈ [1, 6]. On the other hand, the model trained by different incremental learning strategies starts with a warm-start model (which is trained on days [0, 13] of data), instead of from scratch. The model is then incrementally updated with training data day T, validated on data T +1, and tested on data T +2, where T ∈ [14, 19].

Performance Comparison (Log loss) in Industrial Dataset. ⋆ denotes p < 0.05 when performing the two-tailed pairwise t-test on GraphSAIL with the best baseline.
The effectiveness of a model is measured by Logloss, while the efficiency is measured by the model’s training time in seconds. As can be observed, our model achieves consistently better results compared to baseline models on all incremental days. Specifically, GraphSAIL outperforms batch mode by 5.84% in terms of Log loss. For efficiency concern, it takes just 3.5% of the training time of batch mode approach. Moreover, GraphSAIL outperforms the other incremental learning baselines which is consistent with the observations in public datasets. It demonstrates the advantage of our model for incrementally training a GCN model on a large-scale industrial scenario with rich side information.