LinkedIn GLMix
A snapshot of the LinkedIn jobs homepage.
As the world’s largest professional social network, LinkedIn provides a unique value proposition for its over 400M+ members to connect with all kinds of professional opportunities for their career growth. One of the most important products is the Jobs Homepage, which serves as a central place for members with job seeking intention to come and find good jobs to apply for. One of the main modules on the page is “Jobs you may be interested in”, where relevant job thumbnails are recommended to members based on their public profile data and past activity on the site. If a member is interested in a recommended job, she can click on it to go to the job detail page, where the original job post is shown with information such as the job title, description, responsibilities, required skills and qualifications. The job detail page also has an “apply” button which allows the member to apply for the job with one click, either on LinkedIn or on the website of the company posting the job. One of the key success metrics for LinkedIn jobs business is the total number of job application clicks (i.e the number of clicks on the “apply” button), which is the focus for the job recommendation problem in this paper. Another second-order metric is called “job detail views”, which represents the total number of clicks generated from the “Jobs you may be interested in” module to the job details pages. We consider job application clicks to be the key metric to optimize for, instead of job detail views, because the job posters mostly care about how many applications they receive, instead of how many people view their job postings.
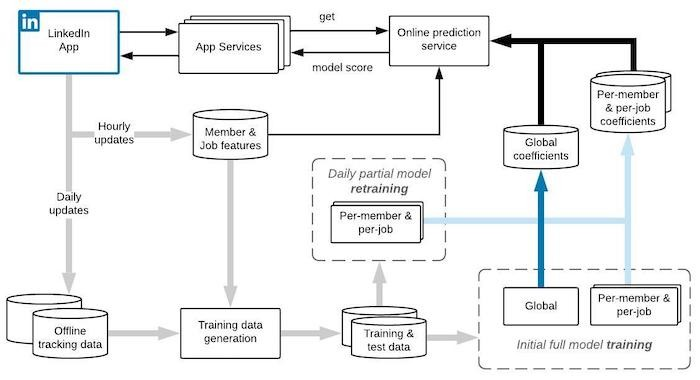
In -th observation, member interacts with job . The total score is:
The first term on the right hand side is from the fixed effects model. The second and the third term represent the contribution of per-member and per-job random effects models. , , are feature vectors for the fixed effects model, the per-member and the per-job random effects model respectively. , , are coefficients vectors for three types of models respectively. Since random effects models represent the entity propensity, they should be updated more frequently than the fixed effects model to capture the propensity change. In practice we update the fixed effects model in a much lower frequency (e.g., update monthly) than random effects models (e.g., update daily). The random effects model training often takes 6-12 hours because the training data contains millions of entities with high dimensional features. Applying incremental learning in the random effects model training is desired to promptly detect the change.
Quality matches via personalized AI for hirer and seeker preferences