Cold Start
One long-standing challenge for Collaborative Filtering (CF) based recommendation methods is the cold start problem, i.e., to provide recommendations for new users or items who have no historical interaction record. The cold start problem is common in real world applications. For example, 500 hours of new videos are uploaded to YouTube every minute, 500,000 new users register in Facebook every day, and web/mobile apps face the daily challenge of onboarding new users and subscribers. To provide recommendations for these new users and items, many content-based methods and heuristic methods have been deployed, e.g., recommending popular items or geographically near items. However, recent research efforts that tackle the cold start problem from the perspective of machine learning have made promising strides.
Cold start happens when new users or new items arrive in e-commerce platforms. Classic recommender systems like collaborative filtering assumes that each user or item has some ratings so that we can infer ratings of similar users/items even if those ratings are unavailable. However, for new users/items, this becomes hard because we have no browse, click or purchase data for them. As a result, we cannot “fill in the blank” using typical matrix factorization techniques.
Recommender systems can be generally classified as collaborative filter-based, content-based, or hybrid systems. Collaborative filter-based systems estimate user responses by collecting preference information from numerous users. The predictions are built upon the existing ratings of other users who have similar ratings as the target user. However, such systems cannot handle new users (user cold-start) and new items (item cold-start) because of the lack of user-item interactions. Content-based systems are introduced to solve the cold-start problem. Such systems use user profile information (e.g., gender, nationality, religion, and political stance) and the contents of the items to make recommendations. The systems might have a limitation suggesting the same items to the users who have similar contents regardless of items that user already rated. Hybrid systems, which are based on a collaborative filter and utilize content information, are widely used in various applications. However, these systems are unfit for a recommendation when the user-item interaction data are sparse. Moreover, due to privacy issues, collecting personal information is challenging, which might result in the user cold-start problem. To avoid the user cold-start problem due to privacy issues, many web-based systems, such as Netflix, recommend items based on only minimal user information. Netflix initially presents popular movies and television programs to new users: we call these videos the evidence candidates. Then, the user chooses the videos that he/she likes among the candidates. Afterward, the system recommends some programs based on the videos selected by the user. Recently, to improve performance, the recommendations have been made using deep learning methods; however, the cold-start problem remains for new users who rate only a few items.
note
Recommending items to cold-start users who have very sparse interactions, also known as user cold-start recommendation, is one of the major challenges.
Matrix completion is a classic problem underlying recommender systems. It is traditionally tackled with matrix factorization. Recently, deep learning based methods, especially graph neural networks, have made impressive progress on this problem. Despite their effectiveness, existing methods focus on modeling the user-item interaction graph. The inherent drawback of such methods is that their performance is bound to the density of the interactions, which is however usually of high sparsity. More importantly, for a cold start user/item that does not have any interactions, such methods are unable to learn the preference embedding of the user/item since there is no link to this user/item in the graph.
Recent ML-based approaches have made promising strides versus traditional methods. These ML approaches typically combine both user-item interaction data of existing warm start users and items (as in CF-based methods) with auxiliary information of users and items such as user profiles and item content information (as in content-based methods).
Challenges
- Error superimposition issue - auxiliary-to-CF transformation error increases the final recommendation error.
- Ineffective learning issue - long distance from transformation functions to model output layer leads to ineffective model learning.
- Unified transformation issue - applying the same transformation function for different users and items results in poor transformation.
Concepts
Item cold-start
- Find similar items using item features
- Another approach is to randomly recommend these items to users until enough interaction data is available
- Treating cold start in product search by priors - New products in e-commerce platforms suffer from cold start, both in recommendation and search. In this study, we present experiments to deal with cold start in search by predicting priors for behavioral features in learning to rank set up. The offline results show that our technique generates priors for behavioral features that closely track posterior values. The online A/B test on 140MM queries shows that treatment with priors improves new products impressions and increased customers engagement pointing to their relevance and quality.
User cold-start
- Find similar users, but it requires user information. So if we do not have this information, e.g. in case of session-based recommenders, we will not be able to use this technique.
- Another approach is to ask about interests using surveys. It works pretty well.
- One more approach is to recommend popular items until enough interaction data is available for that user and then gradually switch to personalized recommendations.
Item lifecycle
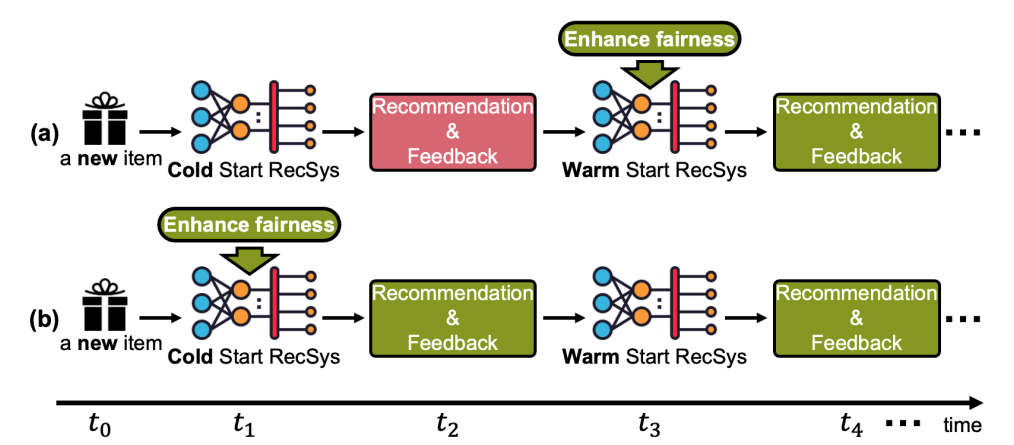
Above figure shows the life cycle of an item: the item first appears in the system at 𝑡0; in the absence of historical feedback, a cold start recommendation algorithm recommends this item to users and receives the first collection of feedback at 𝑡2; then, a warm start recommender can be trained at 𝑡3 by this first collection of feedback, further recommending the item to users and collecting new feedback at 𝑡4; the system continues this loop of collecting new feedback and training a new warm start model until the item leaves the system.
Mapping framework
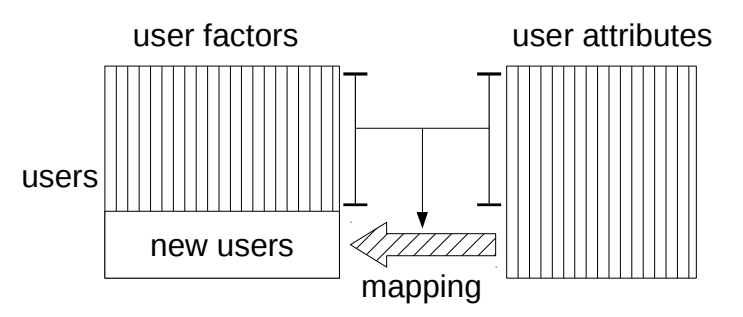
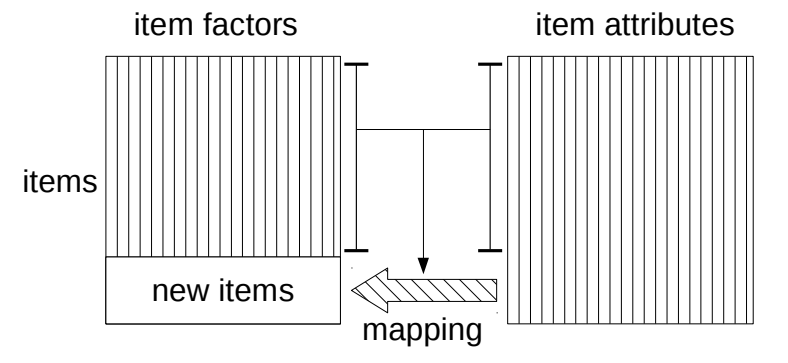
To provide cold start recommendations, typical machine learning based methods need to utilize user-item interactions of existing warm start users and items, and content features of both warm and cold start items. These content features – such as item descriptions, reviews, or from other sources – are often readily available even for new items. The main idea of these cold start recommendation algorithms is to learn a transformation from item content features of warm start items to user-item interactions between warm start users and items during training, and then apply this learned transformation process to the content features of new items to predict possible interactions between users and new items as recommendations during testing. Note that item content features of warm start items and new items share the same feature space.
Approaches
Over the years, many approaches have been proposed including heuristic non-parametric algorithms like KNN, though now there is an emphasis on optimization based machine learning algorithms. These methods can be categorized into two types: separate-training methods and joint-training methods.
- Separate-training methods separately learn two models: a collaborative filtering (CF) model learns CF embeddings of warm start items; and a content model learns how to transform the item content features to the learned collaborative embeddings using warm start items. During inference, the content model is first applied on content features of new items to generate CF embeddings and then recommendations for these new items are provided by these embeddings. A typical example is DeepMusic, which utilizes a multi-layer perceptron (MLP) to transform item content features to CF embeddings learned by a pretrained matrix factorization model.
- Joint-training methods combine the CF model and content model together and train both of them through a single backpropagation process. A typical example is DropoutNet, which has an MLP based content component to first transform item content features, followed by a dot-product based neural CF component to provide recommendations. Moreover, Heater mixes separate-training and joint-training methods, which delivers greater performance.
- Representative based: use subset of items and users that represents the population.
- Content based: use side information such as text, social networks, etc.
- Bandit: consider the exploration vs exploitation tradeoffs in new items.
- Auxiliary information - Incorporate auxiliary data as user or item features.
- Heterogeneous Information Networks - enrich user-item interactions with complementary heterogeneous information via higher-order graph structures.
- Meta learning
- Interactive Dialogue
Representative approaches for cold-start recommendations
TL;DR use subset of items and users that represents the population
If we do not have enough information about users and items, we can rely more on those who “represent” the set of items and users. That’s the philosophy behind representative based methods. Representatives can be users whose linear combinations of preferences accurately approximate other users’.
Random Strategy
A naive method to choose the representatives is simply to randomly select a subset of users or items. This strategy corresponds to the assumption that users or items are indifferent in terms of their predictive power on other users’ and items’ ratings and therefore there would be no gain in strategically choosing which users and items to elicit ratings from.
Most Ratings Strategy
Another simple method to select the representative is to choose the k users or k items which had the most observed ratings. This strategy is also easy to calculate. However, popularity in many cases are not equivalent to informativeness. For example, the most popular movies tend to be widely liked by almost any user and a rating on such movies would provide little information regarding the new user’s unique preferences. Similarly, a very active user may be someone who frequently watches randomly selected movies and may not serve as a good user prototype.
K-Medoids Strategy
The previous two methods do not consider the correlation between the selected representatives and could potentially choose multiple highly similar users or items. To avoid such redundancy problem, we also consider another more complicated strategy based on k-medoids clustering. k-medoids tries to group data objects into k clusters. Each cluster is represented by an actual data object, i.e. the representative. The other instances are clustered with the representative to which it is most similar to.
A famous representative based method, Representative Based Matrix Factorization (RBMF) is an extension of MF methods with an additional constraint that m items should be represented by a linear combination of k items, as can be seen from the objective function below:
Here, we have the reconstruction error similar to standard MF methods, with this additional constraint. When a new user joins the platform, we can ask the new users to rate these items, and use that to infer the ratings of other items. This way, with a small additional cost on users of rating some items, we can improve the recommendations for new users.
note
In most real world systems, new items and new users would be added to the system constantly. A recommender system should be able to adjust its model rapidly in order to be able to make recommendations regarding new users and new items as soon as possible. This require techniques for learning the parameters associated with new users and new items based on an increment of new data without the need to retrain the whole model entirely. This type of techniques have also been known as folding in. Using the RBMF model, folding in is effortless. In particular, we only need to obtain ratings from the representative users for a new item in order to recommend it to other users. Similarly, we only need to ask a new user to rate representative items to recommend other items to him.
There have been improvements on RBMF proposed in this paper, where we can interview only a subset of users instead of all the new users to decrease the burden on the new users. The advantage of this approach is that there is more interpretability, because new users can be expressed in terms of few representative items. Also, If you’re using MF methods already, this can be a simple extension to handle cold start. Possible disadvantage is that might be a need to change UI and front end logic to ask the users to rate the representative items.
Auxiliary information transformation
TL;DR utilizes auxiliary information.
ML-based models combine user-item interactions from existing warm start users and items (as in CF-based methods) with auxiliary information from both warm and cold users and items (as in content-based methods). This auxiliary information – be it from user profiles, item descriptions, reviews, and other sources – is often readily available even in the absence of user-item interactions.
There are various kinds of auxiliary information could be exploited to improve cold-start recommendation performance, e.g., user attributes, item attributes, knowledge graphs, samples in an auxiliary domain, etc.
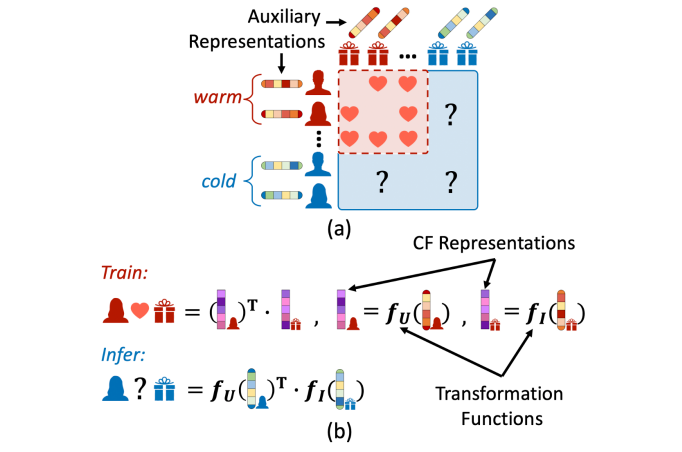
(a) setup of cold start recommendation problem, where both warm and cold users and items have auxiliary representations (such as user profiles and item content); and (b) the main idea of existing cold start recommendation algorithms: learn transformation functions to transform auxiliary representations to CF representations.
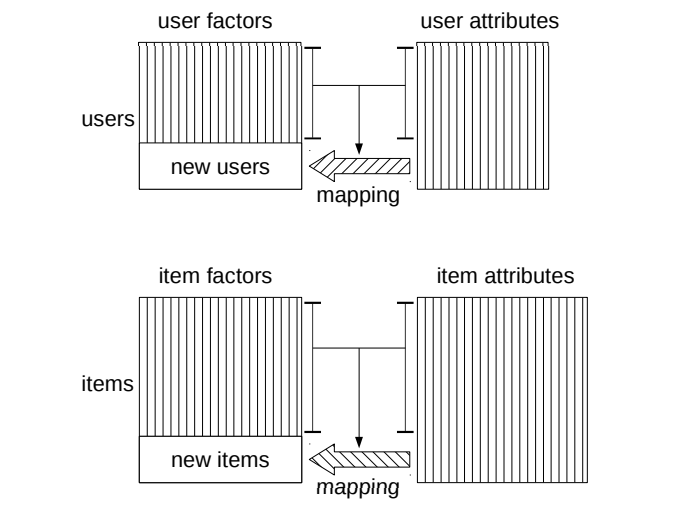
The key insight is to learn two transformation functions – one for users and one for items – to transform the auxiliary representations of these new users and items into the CF space. The learned transformation functions are then applied on auxiliary representations of cold start users and items to predict preference scores at inference time. Hence, the fundamental challenge is how to generate effective transformation functions based on the given auxiliary information and user-item interactions.
Recent ML-based approaches have made promising strides versus traditional methods. These ML approaches typically combine both user-item interaction data of existing warm start users and items (as in CF-based methods) with auxiliary information of users and items such as user profiles and item content information (as in content-based methods). However, such approaches face key drawbacks including the error superimposition issue that the auxiliary-to-CF transformation error increases the final recommendation error; the ineffective learning issue that long distance from transformation functions to model output layer leads to ineffective model learning; and the unified transformation issue that applying the same transformation function for different users and items results in poor transformation.
Recommender systems have been widely deployed in various online services, such as E-commerce platforms and news portals, to address the issue of information overload for users. At their core, they typically adopt collaborative filtering, aiming to estimate the likelihood of a user adopting an item based on the interaction history like past purchases and clicks. However, the interaction data of new users or new items are often very sparse, leading to the so-called cold-start scenarios in which it becomes challenging to learn effective user or item representations.
Bandits
TL;DR designing a decision making strategy. consider the exploration vs exploitation tradeoffs in new items.
When a new user joins the system it initially has no knowledge of the preferences of the user and so would like to quickly learn these. The recommender system therefore initially starts in an “exploration” phase where the first few items that it asks the new user to rate are chosen with the aim of discovering the user’s preferences. Cold-start problem can also be naturally modeled as a CMAB problem. Multi-armed bandit problem (MAB) which derives from the gamble game is a simplified setting of reinforcement learning. In order to earn the maximal sum of rewards, the gambler has two choices, one is trying to play some new arms of the multi-armed bandit which may have higher reward (exploration), while the other is sticking on playing the arm (exploitation) given the high reward so far.
In particular, upper confidence bound (UCB) is an effective method to solve CMAB, which suggests an arm with maximal confidence upper bound. LinUCB extends UCB by considering contextual information about the arm. To recommend diversified items, suggests a batch of items (called super arm) to each user with an entropy regularization.
Cross-domain transfer
TL;DR few-shot meta-learners.
A common challenge for most current recommender systems is the cold-start problem. Due to the lack of user-item interactions, the fine-tuned recommender systems are unable to handle situations with new users or new items. Recently, some works introduce the meta-optimization idea into the recommendation scenarios, i.e. predicting the user preference by only a few of past interacted items. The core idea is learning a global sharing initialization parameter for all users and then learning the local parameters for each user separately. However, most meta-learning based recommendation approaches adopt model-agnostic meta-learning for parameter initialization, where the global sharing parameter may lead the model into local optima for some users.
Although recommendation systems have been proved to play a significant role in a variety of applications, there are two long-standing obstacles that greatly limit the performance of recommendation systems. On the one hand, the number of user-item interaction records often tends to be small and is insufficient to mine user interests well, which is called the data sparsity problem. On the other hand, for any service, there are constantly new users joining, for whom there are no historical interaction records. Traditional recommendation systems cannot make recommendations to these users, which is called the cold-start problem.
As more and more users begin to interact with more than one domains (e.g., music and book), it increases opportunities of leveraging information collected from other domains to alleviate the two problems (i.e., data sparsity and cold-start problems) in one domain. This idea leads to Cross-Domain Recommendation (CDR) which has attracted increasing attention in recent years.
There are two core issues for cross-domain recommendation, namely, what to transfer and how to transfer. What to transfer is how to mine useful knowledge in each domain, and how to transfer focuses on how to establish linkages between domains and realize the transfer of knowledge.
Cold-start problems are enormous challenges in practical recommender systems. One promising solution for this problem is cross-domain recommendation (CDR) which leverages rich information from an auxiliary (source) domain to improve the performance of recommender system in the target domain. In these CDR approaches, the family of Embedding and Mapping methods for CDR (EMCDR) is very effective, which explicitly learn a mapping function from source embeddings to target embeddings with overlapping users.
With the help of the auxiliary (source) domain, cross-domain recommendation (CDR) is a promising solution to alleviate data sparsity and the cold-start problem in the target domain. The core task of CDR is preference transfer. For instance, If I like Song A and Song B (music domain), how much I like Movie X (movie domain)?
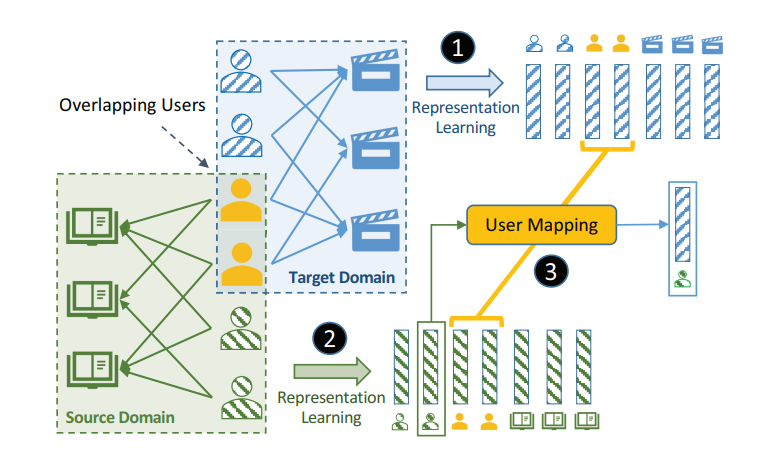
Existing workflow in cross-domain recommendation for cold-start users.
Domain overlapping
](/recohut/assets/images/content-concepts-raw-cold-start-untitled-6-b23d547fbc1ad2c32f3f3b2eddd6af5e.png)
Recommendation scenarios
](/recohut/assets/images/content-concepts-raw-cold-start-untitled-7-7d44ccb6bc17d2eaaa1ef2de7ee6ec02.png)
At the very beginning, CMF assumes a shared global user embedding matrix for all domains, and it factorizes matrices from multiple domains simultaneously. CST utilizes the user embedding in the source domain to initialize the embedding in the target domain and restricts them from being closed. In recent years, researchers proposed many deep learning-based models to enhance knowledge transfer. CoNet transfers and combines the knowledge by using cross-connections between feedforward neural networks. MINDTL combines the CF information of the target-domain with the rating patterns extracted from a cluster-level rating matrix in the source-domain. DDTCDR develops a novel latent orthogonal mapping to extract user preferences over multiple domains while preserving relations between users across different latent spaces. Similar to multi-task methods, these methods focus on proposing a well-designed deep structure that can effectively train the source and target domains together.
Another group of CDR methods focus on bridging user preferences in different domains, which is the most related work. CST utilizes the user embedding learned in the source domain to initialize the user embedding in the target domain and restricts them to being closed. Some methods explicitly model the preference bridge.
CMF is a simple and well-known method for cross-domain recommendation by sharing the user factors and factorizing joint rating matrix across domains.
EMCDR is the first to propose the three-step optimization paradigm by training matrix factorization in both domains successively then utilizing multi-layer perceptrons to map the user latent factors.
CDLFM modifies matrix factorization by fusing three kinds of user similarities as a regularization term based on their rating behaviors. A neighborhood-based mapping approach is used to replace the previous multi-layer perceptrons, by considering similar users and the gradient boosting trees (GBT) based ensemble learning method.
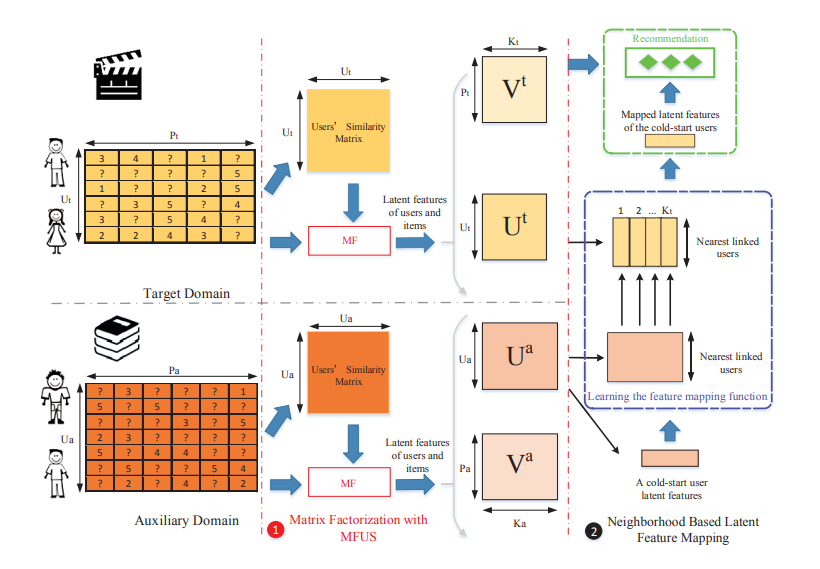
The workflow diagram for our proposed model CDLFM.
Meta Learning
Meta learning covers a wide range of topics and has contributed to a booming study trend. Few-shot learning is one of successful branches of meta learning. We retrospect some representative meta-learning models with strong connections to our work.
They can be divided into the following common types.
- Memory-based approaches: combining deep neural networks (DNNs) with the memory mechanism to enhance the capability of storing and querying meta-knowledge.
- Optimization-based approaches: a meta-learner, e.g. recurrent neural networks (RNNs) is trained to optimize target models.
- Metric-based approaches: learning an effective similarity metric between new examples and other examples in the training set.
- Gradient-based approaches: learning an shared initialization where the model parameters can be trained via a few gradient updates on new tasks. Most meta-learning models follow an episodic learning manner. Among them, MAML is one of the most popular frameworks, which falls into the fourth type. Some MAML-based works consider that the sequence of tasks may originate from different task distributions, and try various task-specific adaptations to improve model capability.
It is also named learning to learn, aiming to improve novel tasks’ performance by training on similar tasks. There are various meta learning methods, e.g., metric-based methods, gradient-based methods, and parameter-generating based methods.
This line of research aims to learn a model which can adapt and generalize to new tasks and new environments with a few training samples. To achieve the goal of “learning-to-learn”, there are three types of different approaches. Metric-based methods are based on a similar idea to the nearest neighbors algorithm with a well-designed metric or distance function, prototypical networks or Siamese Neural Network. Model-based methods usually perform a rapid parameter update with an internal architecture or are controlled by another meta-learner model. As for the optimization-based approaches, by adjusting the optimization algorithm, the models can be efficiently updated with a few examples.
Inspired by the huge progress on few-shot learning and meta learning, there emerge some promising works on solving cold-start problems from the perspective of meta learning, where making recommendations for one user is regarded as a single task.
In the training phase, they try to derive the global knowledge across different tasks as a strong generalization prior. When a cold-start user comes in the test phase, the personalized recommendation for her/him can be predicted with only a few interacted items are available, but does so by using the global knowledge already learned.
Most meta-learning recommenders are built upon the well-known framework of model-agnostic meta learning (MAML), aiming to learn a parameter initialization where a few steps of gradient updates will lead to good performances on the new tasks. A typical assumption here is the recommendations of different users are highly relevant. However, this assumption does not necessarily hold in actual scenarios. When the users exhibit different purchase intentions, the task relevance among them is actually very weak, which makes it problematic to find a shared parameter initialization optimal for all users. As shown in the image below:
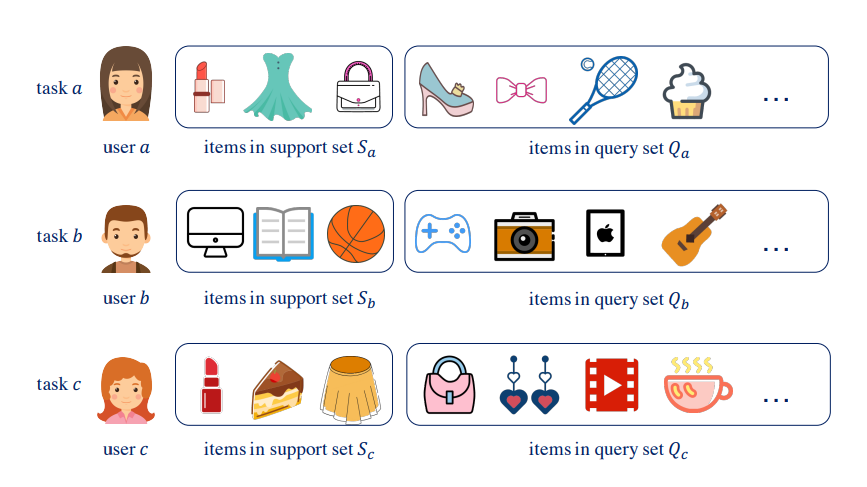
An illustration of the relevance of different tasks. The purchase intentions of user 𝑎, 𝑏 and 𝑐 are manifested by the corresponding user-item interactions. It shows that tasks 𝑎, 𝑐 are closely relevant but task 𝑏 is largely different from them. Each task owns the user-specific support set and query set.
Inspired by the significant improvements of meta learning, the pioneering work of Vartak et. al. provides a meta-learning strategy to solve cold-start problems. It uses a task-dependent way to generate the varying biases of decision layers for different tasks, but it is prone to underfitting and is not flexible enough to handle various recommendation scenarios. MeLU adopts the framework of MAML. Specifically, it divides the model parameters into two groups, i.e., the personalized parameter and the embedding parameter. The personalized parameter is characterized as a fully-connected DNN to estimate user preferences. The embedding parameter is referred as the embeddings of users and items learned from side-information. An inner-outer loop is used to update these two groups of parameters. In the inner loop, the personalized parameter is locally updated via the prediction loss of support set in current task. In the outer loop, these parameters are globally updated according to the prediction loss of query sets in multiple tasks. Through the fashion of local-global update, MeLU can provide a shared initialization for different tasks. The later work MetaCS is much similar to MeLU, and the main difference is that the local-global update involves all parameters from input embedding to model prediction. To generalize well for different tasks, MetaHIN and MAMO propose different task-specific adaptation strategies. In particular, MetaHIN incorporates heterogeneous information networks (HINs) into MAML to capture rich semantics of meta-paths. MAMO introduces two memory matrices based on user profiles: a feature-specific memory that provides a specific bias term for the shared parameter initialization; a task-specific memory that guides the model for predictions. However, these two gradient-based meta-learning models may still suffer from potential training issues in MAML, and the model-level innovations of them are closely related with side-information, which limits their application scenarios.
Cold-start Sequential Models
Though quite a few cold-start recommendation methods have been proposed, most require side information or knowledge from other domains during training, and commonly treat the user-item interactions in a static way. In contrast, cold-start sequential recommendation targets a setting where no additional auxiliary knowledge can be accessed due to privacy issues, and more importantly, the user-item interactions are sequentially dependent. A user’s preferences and tastes may change over time and such dynamics are of great significance in sequential recommendation. Hence, it is necessary to develop a new sequential recommendation framework that can distill short-range item transitional dynamics, and make fast adaptation to those cold-start users with limited user-item interactions.
Interactive Dialogue
Traditional recommendation systems produce static rather than interactive recommendations invariant to a user’s specific requests, clarifications, or current mood, and can suffer from the cold-start problem if their tastes are unknown. These issues can be alleviated by treating recommendation as an interactive dialogue task instead, where an expert recommender can sequentially ask about someone’s preferences, react to their requests, and recommend more appropriate items.
Hybrid
It is indeed the most common approach because of the flexibility and performance. In this approach, we simply combine different cold-start approaches. E.g. Using bandit exploration-exploitation approach but use meta-learning model to select exploration recommendation (instead of random choice).
Models
KNN
It generates recommendations by conventional nearest neighbor algorithm. The user-user or item-item similarity is computed by the given auxiliary representations. This method works for Task 1 and 2 but not Task 3.
ITFM
Bayesian Personalized Ranking Model with Attribute-to-Feature Mappings for Cold-Start Recommendation
CMF
It combines matrix factorization and auxiliary representations to CF representations transformation together into one objective function and trains these two parts simultaneously. CMF works for Task 1 and Task 2 but not Task 3.
LinMap
It takes pretrained CF representations and learns a matrix to transform auxiliary representations to pretrained CF representations. LinMap can work for all three tasks.
LoCo
It is a linear low-rank regression method, which learns a low-rank transformation matrix to directly transform auxiliary representations to final predicted preference scores. It can only work for Task 1 and 2 but not Task 3.
LWA
It is a meta-learning based algorithm which constructs different logistic regression classifiers for different users based on their historical records. The user-specific logistic regression takes the auxiliary representation of one cold start item as input and predicts whether the user will like input item or not. LWA can only work for Task 2.
DropoutNet
It inputs both pretrained CF representations and auxiliary representations into a MLP and randomly dropouts pretrained CF representations during training. It works for all tasks. The basic idea is simple yet powerful. Their approach is that, in training deep learning based recommendation systems (e.g. collaborative filtering with many layers), we can make it robust against the cold items by randomly dropping ratings of items and users. The key here is that, as opposed to standard dropout in neural net training, they drop the features, not the nodes. By doing so, they can make the neural net depend less on certain ratings, and be more generalizable to items/users with less ratings. The strength of their approach is that it can be used with any neural net based recommender systems, and also that the approach works for cold start in both users and items.
LLAE
It applies the idea of zero-shot learning to solve cold start recommendation problems. Similar to LoCo, LLAE also learns a transformation matrix to directly transform auxiliary representation to predicted preference scores.
Heater
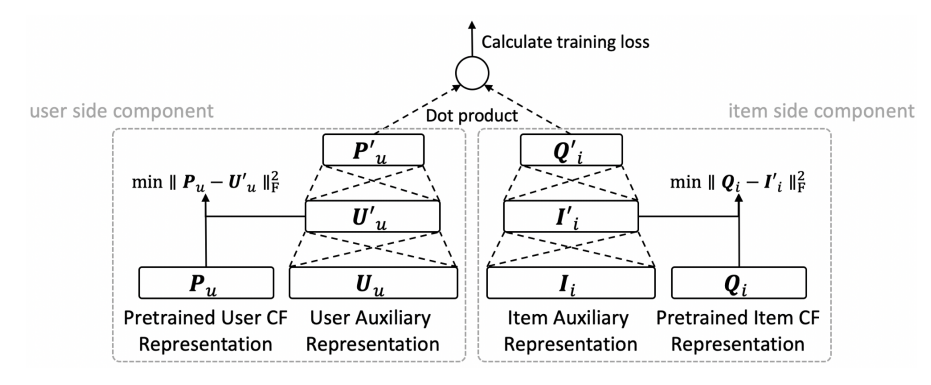
MetaHIN
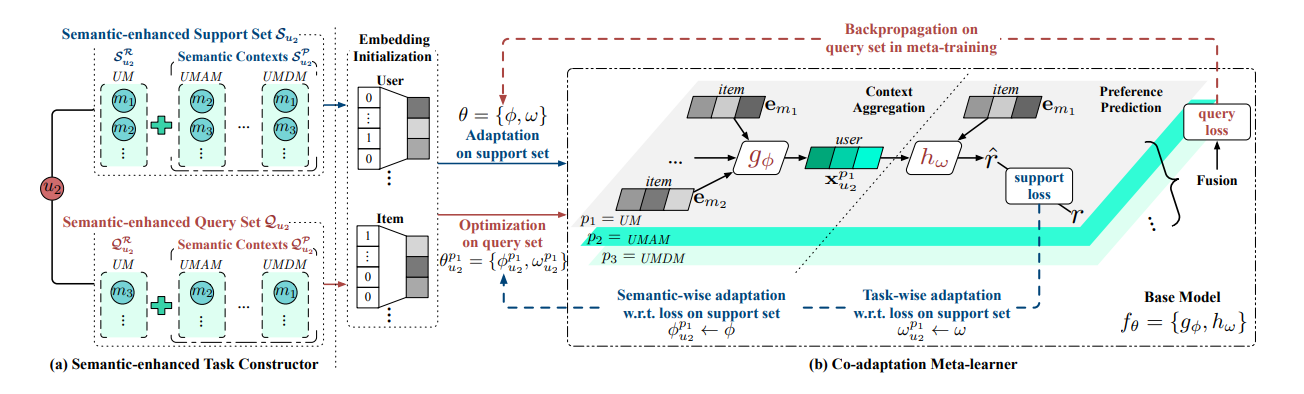
Illustration of the meta-training procedure of a task in MetaHIN. (a) Semantic-enhanced task constructor, where the support and query sets are augmented with meta-path based heterogeneous semantic contexts. (b) Co-adaptation meta learner, with semantic- and task-wise adaptations on the support set, while the global prior θ is optimized on the query set. During meta-testing, each task follows the same procedure except updating the global prior.
MeLU
It get rating predictions by feeding the concatenation of user and item embeddings into fully connected layers. The local parameter of the fully connected layers will be locally updated for personalized recommendation. The global parameter of the recommender and the parameters of embedding layers will be globally updated for all the users.
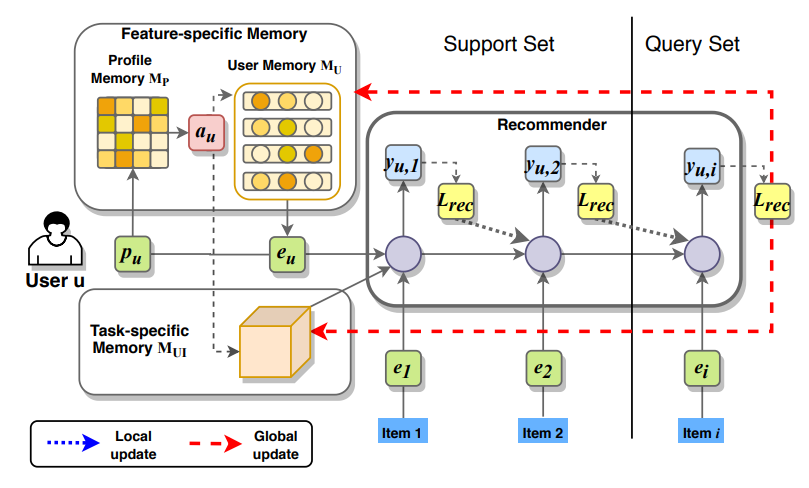
MAMO
Memory-Augmented Meta-Optimization (MAMO) is an adaptive meta learning recommendation model, to improve the stability, generalization and computational cost of model by learning a multi-level personalized model parameters.
STAR-GCN
STAR-GCN: Stacked and Reconstructed Graph Convolutional Networks for Recommender Systems.
We propose a new STAcked and Reconstructed Graph Convolutional Networks (STAR-GCN) architecture to learn node representations for boosting the performance in recommender systems, especially in the cold start scenario. STAR-GCN employs a stack of GCN encoder-decoders combined with intermediate supervision to improve the final prediction performance. Unlike the graph convolutional matrix completion model with one-hot encoding node inputs, our STAR-GCN learns low-dimensional user and item latent factors as the input to restrain the model space complexity. Moreover, our STAR-GCN can produce node embeddings for new nodes by reconstructing masked input node embeddings, which essentially tackles the cold start problem. Furthermore, we discover a label leakage issue when training GCN-based models for link prediction tasks and propose a training strategy to avoid the issue. Empirical results on multiple rating prediction benchmarks demonstrate our model achieves state-of-the-art performance in four out of five real-world datasets and significant improvements in predicting ratings in the cold start scenario.
HERS
HERS: Modeling Influential Contexts with Heterogeneous Relations for Sparse and Cold-Start Recommendation. Classic recommender systems face challenges in addressing the data sparsity and cold-start problems with only modeling the user-item relation. An essential direction is to incorporate and understand the additional heterogeneous relations, e.g., user-user and item-item relations, since each user-item interaction is often influenced by other users and items, which form the user’s/item’s influential contexts. This induces important yet challenging issues, including modeling heterogeneous relations, interactions, and the strength of the influence from users/items in the influential contexts. To this end, we design Influential-Context Aggregation Units (ICAU) to aggregate the user-user/item-item relations within a given context as the influential context embeddings. Accordingly, we propose a Heterogeneous relations-Embedded Recommender System (HERS) based on ICAUs to model and interpret the underlying motivation of user-item interactions by considering user-user and item-item influences. The experiments on two real-world datasets show the highly improved recommendation quality made by HERS and its superiority in handling the cold-start problem. In addition, we demonstrate the interpretability of modeling influential contexts in explaining the recommendation results.
AGNN
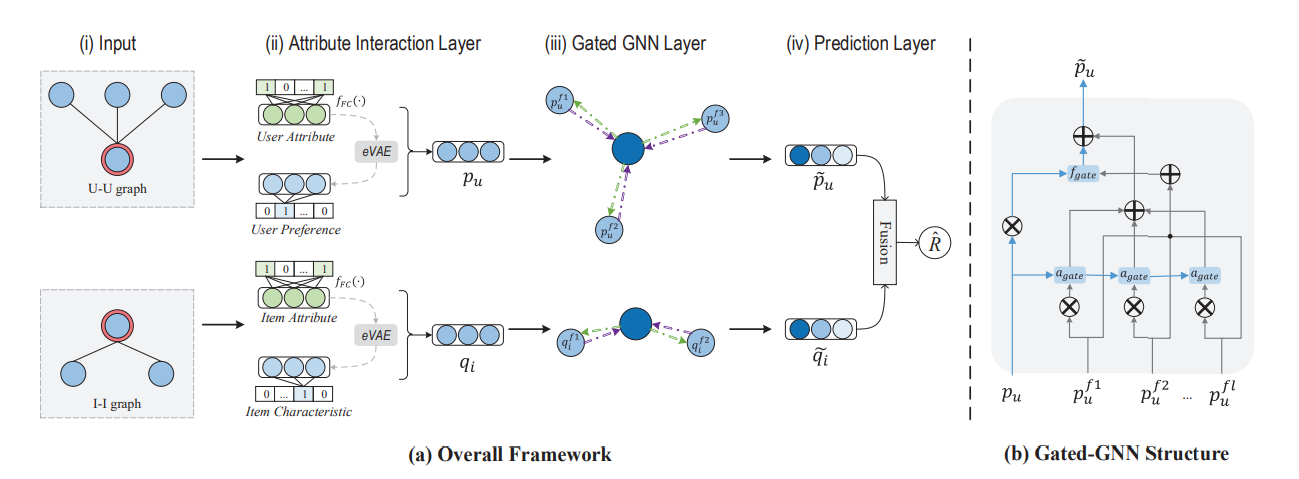
We first design an input layer to build the user (item) attribute graph (). We calculate two kinds of proximity scores between the nodes - preference proximity and attribute proximity (can be calculated with cosine similarity).
- The preference proximity measures the historical preference similarity between two nodes. If two users have similar rating record list (or two items have similar rated record list), they will have a high preference proximity. Note we cannot calculate preference proximity for the cold start nodes as they do not have the historical ratings.
- The attribute proximity measures the similarity between the attributes of two nodes. If two users have similar user profiles, e.g., gender, occupation (or two items have similar properties, e.g., category), they will have a high attribute proximity.
After calculating the overall proximity between two nodes, it becomes a natural choice to build a k-NN graph as adopted in (Monti, Bronstein, and Bresson 2017). Such a method will keep a fixed number of neighbors once the graph is constructed.
In the constructed attribute graph and , each nodes has an attached multi-hot attribute encoding and a unique one-hot representation denoting its identity. Due to the huge number of users and items in the web-scale recommender systems, the dimensionality of nodes’ one-hot representation is extremely high. Moreover, the multi-hot attribute representation simply combines multiple types of attributes into one long vector without considering their interactive relations. The goal of interaction layer is to reduce the dimensionality for one-hot identity representation and learn the high-order attribute interactions for multi-hot attribute representation. To this end, we first set up a lookup table to transform a node’s one-hot representation into the low-dimensional dense vector. The lookup layers correspond to two parameter matrices and . Each entry and encodes the user ’s preference and the item ’s property, respectively. Note that and for cold start nodes are meaningless, since no interaction is observed to train their preference embedding. Inspired by (He and Chua 2017), we capture the high-order attribute interactions with a Bi-Interactive pooling operation, in addition to the linear combination operation.
Intuitively, different neighbors have different relations to a node. Furthermore, one neighbor usually has multiple attributes. For example, in a social network, a user’s neighborhood may consist of classmates, family members, colleagues, and so on, and each neighbor may have several attributes such as age, gender, and occupation. Since all these attributes (along with the preferences) are now encoded in the node’s embedding, it is necessary to pay different attentions to different dimensions of the neighbor node’s embedding. However, existing GCN (Kipf and Welling 2017) or GAT (Veliˇckovi´c et al. 2018) structures cannot do this because they are at the coarse granularity. GCN treats all neighbors equally and GAT differentiates the importance of neighbors at the node level. To solve this problem, we design a gated-GNN structure to aggregate the fine-grained neighbor information.
Given a user ’s final representation and an item ’s final representation after the gated-GNN layer, we model the predicted rating of the user to the item as:
where the MLP function is the multilayer perceptron implemented with one hidden layer, and , , and denotes user bias, item bias, and global bias, respectively. The second term is inner product interaction function (Koren, Bell, and Volinsky 2009), and we add the first term to capture the complicated nonlinear interaction between the user and the item.
The cold start problem is caused by the lack of historical interactions for cold start nodes. We view this as a missing preference problem, and solve it by employing the variational autoencoder structure to reconstruct the preference from the attribute distribution.
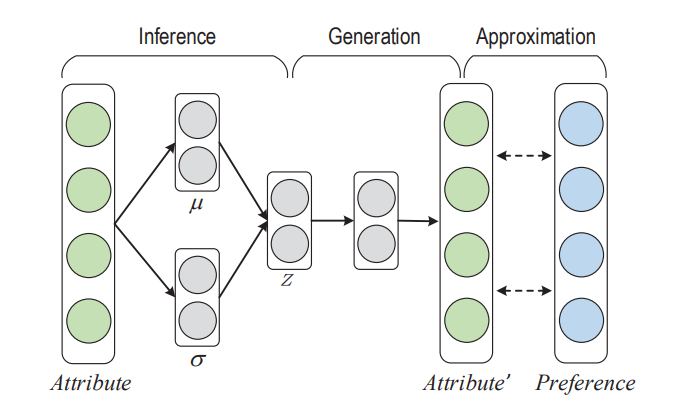
The eVAE structure to generate preference embedding from attribute distribution.
For the rating prediction loss, we employ the square loss as the objective function:
where denotes the set of instances for training, i.e., , is ground truth rating in the training set , and is the predicted rating.
The reconstruction loss function in eVAE is defined as follows:
where the first two terms are same as those in standard VAE, and the last one is our extension for the approximation part.
The overall loss function then becomes:
where is the task-specific rating prediction loss, and is the reconstruction loss.
TaNP
User cold-start recommendation is a long-standing challenge for recommender systems due to the fact that only a few interactions of cold-start users can be exploited. Recent studies seek to address this challenge from the perspective of meta learning, and most of them follow a manner of parameter initialization, where the model parameters can be learned by a few steps of gradient updates. While these gradient-based meta-learning models achieve promising performances to some extent, a fundamental problem of them is how to adapt the global knowledge learned from previous tasks for the recommendations of cold-start users more effectively.
In this paper, we develop a novel meta-learning recommender called task-adaptive neural process (TaNP). TaNP is a new member of the neural process family, where making recommendations for each user is associated with a corresponding stochastic process. TaNP directly maps the observed interactions of each user to a predictive distribution, sidestepping some training issues in gradient-based meta-learning models. More importantly, to balance the trade-off between model capacity and adaptation reliability, we introduce a novel task-adaptive mechanism. It enables our model to learn the relevance of different tasks and customize the global knowledge to the task-related decoder parameters for estimating user preferences. We validate TaNP on multiple benchmark datasets in different experimental settings. Empirical results demonstrate that TaNP yields consistent improvements over several state-of-the-art meta-learning recommenders.
Recent studies seek to address this challenge from the perspective of meta learning, and most of them follow a manner of parameter initialization, where the model parameters can be learned by a few steps of gradient updates. While these gradient-based meta-learning models achieve promising performances to some extent, a fundamental problem of them is how to adapt the global knowledge learned from previous tasks for the recommendations of cold-start users more effectively.
TaNP directly maps the observed interactions of each user to a predictive distribution, sidestepping some training issues in gradient-based meta-learning models. More importantly, to balance the trade-off between model capacity and adaptation reliability, TaNP uses a novel task-adaptive mechanism. It enables this model to learn the relevance of different tasks and customize the global knowledge to the task-related decoder parameters for estimating user preferences.
Background
Inspired by the huge progress on few-shot learning and meta learning, there emerge some promising works on solving cold-start problems from the perspective of meta learning, where making recommendations for one user is regarded as a single task.
In the training phase, they try to derive the global knowledge across different tasks as a strong generalization prior. When a cold-start user comes in the test phase, the personalized recommendation for her/him can be predicted with only a few interacted items are available, but does so by using the global knowledge already learned.
Model
As shown in the above figure, tasks 𝑎 and 𝑐 share the transferable knowledge of recommendations, since user 𝑎 and user 𝑐 express similar purchase intentions, while task 𝑏 is largely different from them. Therefore, learning the relevance of different tasks is an important step in adapting the global knowledge for the recommendations of cold-start users more effectively.
TaNP includes the encoder , the customization module (task identity network and global pool 𝑨) and the adaptive decoder . Both of and are encoded by to generate the variational prior and posterior, respectively. The final task embedding learned from the customized module is used to modulate the model parameters of sampled from is concatenated with to predict via .
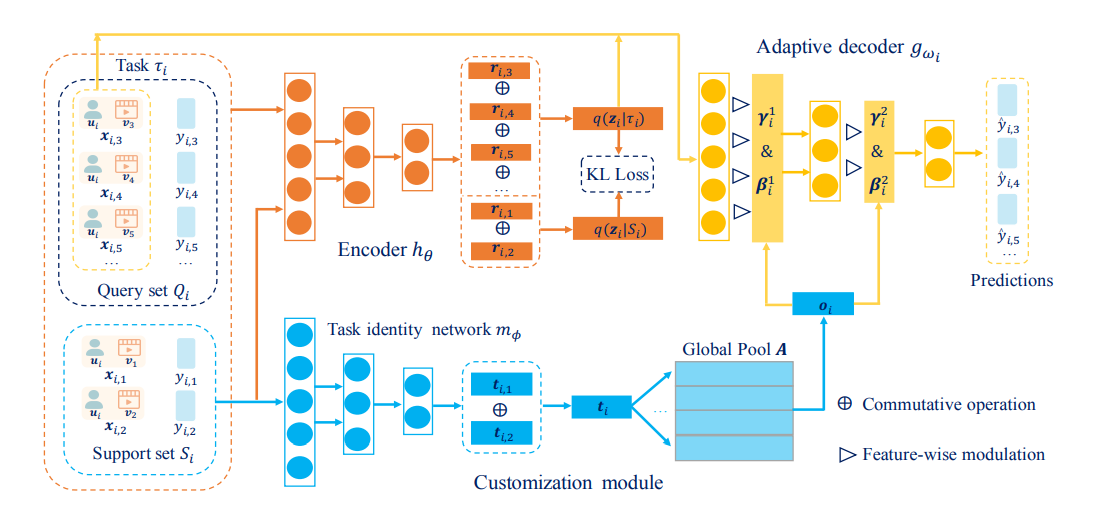
The framework of TaNP in the training phase.
A meta-learning recommender is first learned on each support set (learning procedure) and is then updated according to the prediction loss over multiple query sets (learning-to-learn procedure). Through the guide of the second procedure in many iterations, this meta-learning model can derive the global knowledge across different tasks and adapts such knowledge well for a new task with only available.

CATN
In a large recommender system, the products (or items) could be in many different categories or domains. Given two relevant domains (e.g., Book and Movie), users may have interactions with items in one domain but not in the other domain. To the latter, these users are considered as cold-start users. How to effectively transfer users' preferences based on their interactions from one domain to the other relevant domain, is the key issue in cross-domain recommendation. Inspired by the advances made in review-based recommendation, we propose to model user preference transfer at aspect-level derived from reviews. To this end, we propose a cross-domain recommendation framework via aspect transfer network for cold-start users (named CATN).
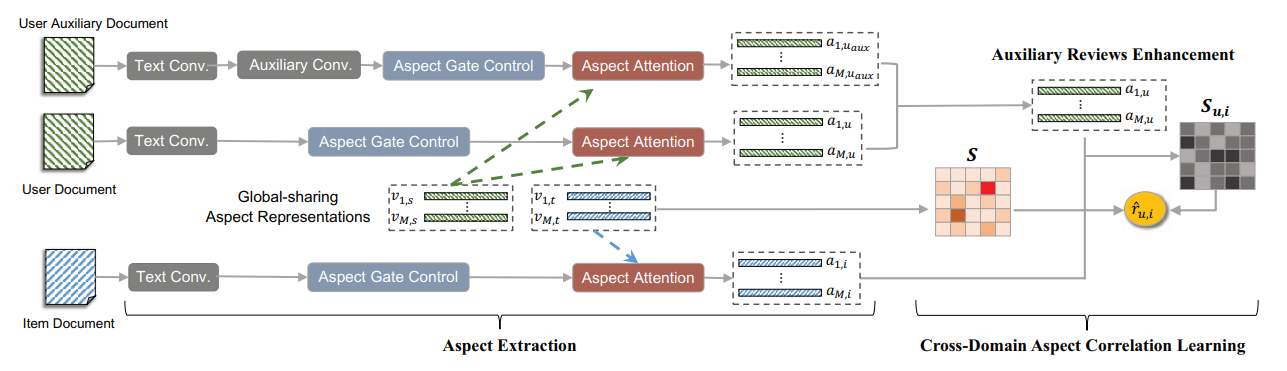
CATN is devised to extract multiple aspects for each user and each item from their review documents, and learn aspect correlations across domains with an attention mechanism. In addition, we further exploit auxiliary reviews from like-minded users to enhance a user's aspect representations. Then, an end-to-end optimization framework is utilized to strengthen the robustness of our model. On real-world datasets, the proposed CATN outperforms SOTA models significantly in terms of rating prediction accuracy. Further analysis shows that our model is able to reveal user aspect connections across domains at a fine level of granularity, making the recommendation explainable.
Two-Level Bandit
KGPL
Solving cold-start problems is indispensable to provide meaningful recommendation results for new users and items. Under sparsely observed data, unobserved user-item pairs are also a vital source for distilling latent users’ information needs. Most present works leverage unobserved samples for extracting negative signals. However, such an optimisation strategy can lead to biased results toward already popular items by frequently handling new items as negative instances. In this study, we tackle the cold-start problems for new users/items by appropriately leveraging unobserved samples. We propose a knowledge graph (KG)-aware recommender based on graph neural networks, which augments labelled samples through pseudo-labelling. Our approach aggressively employs unobserved samples as positive instances and brings new items into the spotlight. To avoid exhaustive label assignments to all possible pairs of users and items, we exploit a KG for selecting probably positive items for each user. We also utilise an improved negative sampling strategy and thereby suppress the exacerbation of popularity biases. Through experiments, we demonstrate that our approach achieves improvements over the state-of-the-art KG-aware recommenders in a variety of scenarios; in particular, our methodology successfully improves recommendation performance for cold-start users/items.
MetaTL
A fundamental challenge for sequential recommenders is to capture the sequential patterns of users toward modeling how users transit among items. In many practical scenarios, however, there are a great number of cold-start users with only minimal logged interactions. As a result, existing sequential recommendation models will lose their predictive power due to the difficulties in learning sequential patterns over users with only limited interactions. In this work, we aim to improve sequential recommendation for cold-start users with a novel framework named MetaTL, which learns to model the transition patterns of users through meta-learning.
Specifically, the proposed MetaTL:
- formulates sequential recommendation for cold-start users as a few-shot learning problem;
- extracts the dynamic transition patterns among users with a translation-based architecture; and
- adopts meta transitional learning to enable fast learning for cold-start users with only limited interactions, leading to accurate inference of sequential interactions.
Background
One of the first approaches for sequential recommendation is the use of Markov Chains to model the transitions of users among items. More recently, TransRec embeds items in a “transition space” and learns a translation vector for each user. With the advance in neural networks, many different neural structures including Recurrent Neural Networks, Convolutional Neural Networks, Transformers and Graph Neural Networks, have been adopted to model the dynamic preferences of users over their behavior sequences. While these methods aim to improve the overall performance via representation learning for sequences, they suffer from weak prediction power for cold-start users with short behavior sequences.
This line of research aims to learn a model which can adapt and generalize to new tasks and new environments with a few training samples. To achieve the goal of “learning-to-learn”, there are three types of different approaches. Metric-based methods are based on a similar idea to the nearest neighbors algorithm with a well-designed metric or distance function, prototypical networks or Siamese Neural Network. Model-based methods usually perform a rapid parameter update with an internal architecture or are controlled by another meta-learner model. As for the optimization-based approaches, by adjusting the optimization algorithm, the models can be efficiently updated with a few examples.
MetaRec proposes a meta-learning strategy to learn user-specific logistic regression. There are also methods including MetaCF, Warm-up and MeLU, adopting Model-Agnostic Meta-Learning (MAML) methods to learn a model to achieve fast adaptation for cold-start users.
cold-start sequential recommendation targets a setting where no additional auxiliary knowledge can be accessed due to privacy issues, and more importantly, the user-item interactions are sequentially dependent. A user’s preferences and tastes may change over time and such dynamics are of great significance in sequential recommendation. Hence, it is necessary to develop a new sequential recommendation framework that can distill short-range item transitional dynamics, and make fast adaptation to those cold-start users with limited user-item interactions.
Model
Let and represent the item set and user set in the platform respectively. Each item is mapped to a trainable embedding associated with its ID. There is no auxiliary information for users or items. In sequential recommendation, given the sequence of items that user 𝑢 has interacted with in chronological order, the model aims to infer the next interesting item . That is to say, we need to predict the preference score for each candidate item based on and thus recommend the top-N items with the highest scores.
In our task, we train the model on , which contains users with various numbers of logged interactions. Then given 𝑢 in a separate test set , the model can quickly learn user transition patterns according to the 𝐾 initial interactions and thus infer the sequential interactions. Note that the size of a user’s initial interactions (i.e., 𝐾) is assumed to be a small number (e.g., 2, 3 or 4) considering the cold-start scenario.
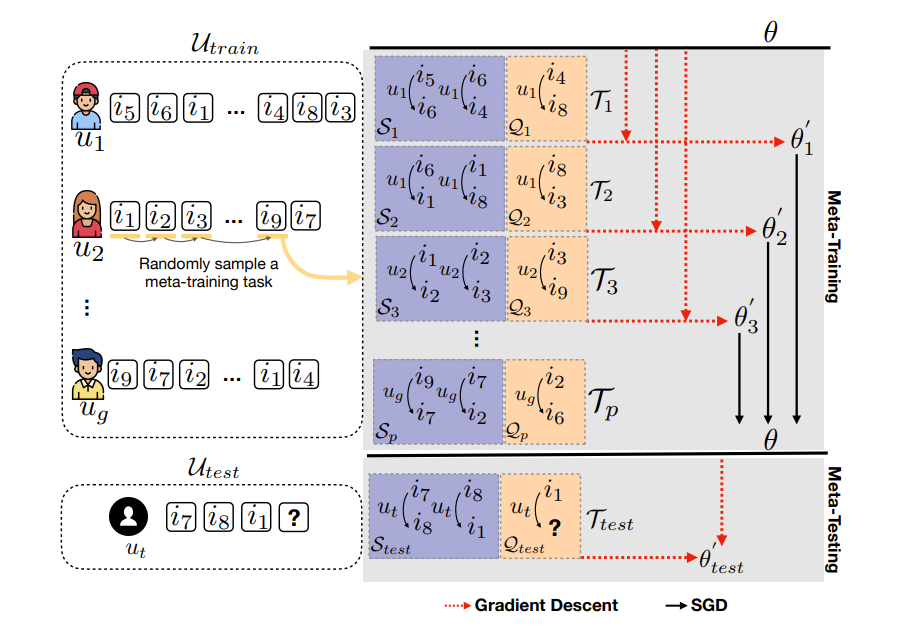
Meta-learning aims to learn a model which can adapt to new tasks (i.e., new users) with a few training samples. To enable meta-learning in sequential recommendation for cold-start users, we formulate training a sequential recommender as solving a new few-shot learning problem (i.e., meta-testing task) by training on many sampled similar tasks (i.e., the meta-training tasks). Each task includes a 𝑠𝑢𝑝𝑝𝑜𝑟𝑡 set S and a 𝑞𝑢𝑒𝑟𝑦 set Q, which can be regarded as the “training” set and “testing” set of the task. For example, while constructing a task , given user with initial interactions in sequence (e.g., ), we will have the a set of transition pairs as support and predict for the query .
When testing on a new user , we will firstly construct the support set based on the user’s initial interactions. The model is fine-tuned with all the transition pairs in and updated to , which can be used to generate the updated . Given the test query , the preference score for item (as the next interaction) is calculated as −.
DaRE
Assume two datasets, and , be the information from the source and target domains, respectively. Each dataset consists of tuples, which represents an individual review written by a user 𝑢 for item 𝑖 with a rating . The two datasets take the form of and , respectively. The goal of our task is to predict an accurate rating score using and a partial set of .
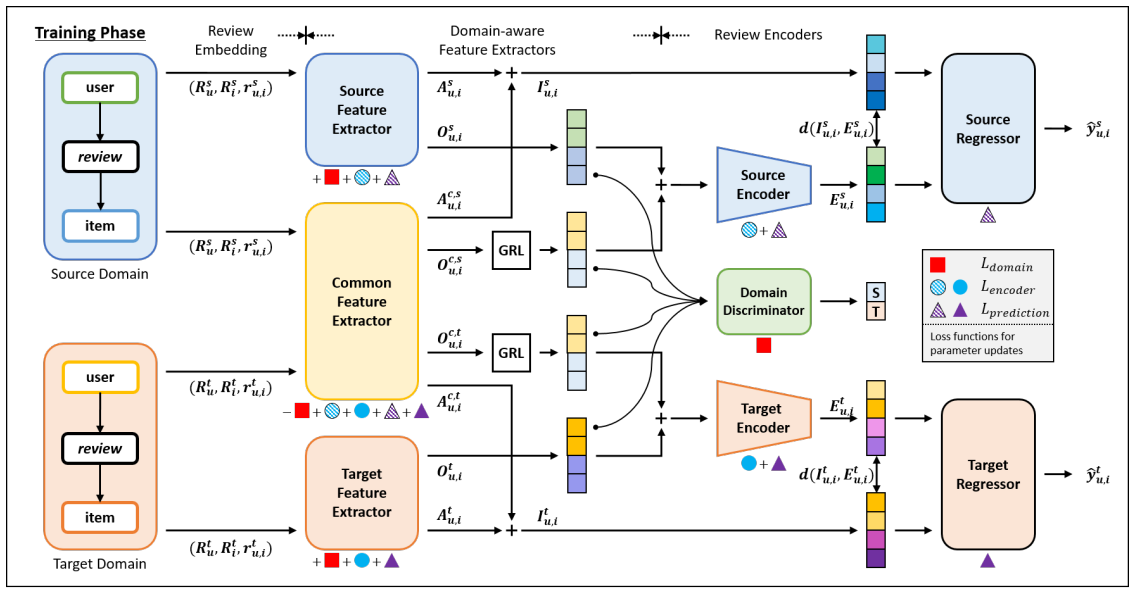
The training phase starts with review embedding layers followed by three types of feature extractors, , , and , named source, common, and target, for the separation of domain-specific, domain-common knowledge. Integrated with domain discriminator, three FEs are trained independently for the parallel extraction of domain-specific , and domain-common knowledge , .
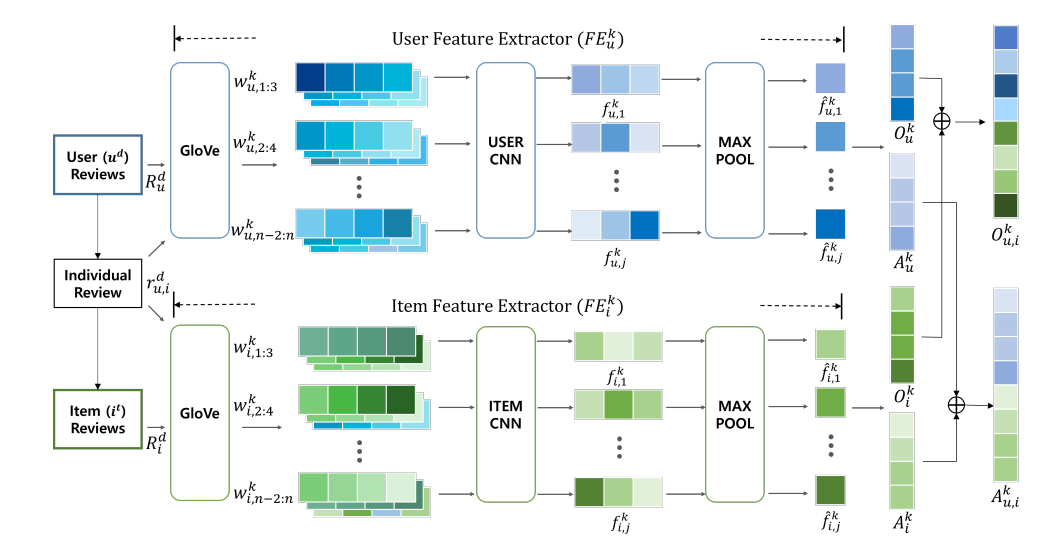
The architecture of a single review feature extractor. DaRE has three parallel review feature extractors of the same architecture with different inputs and parameters.
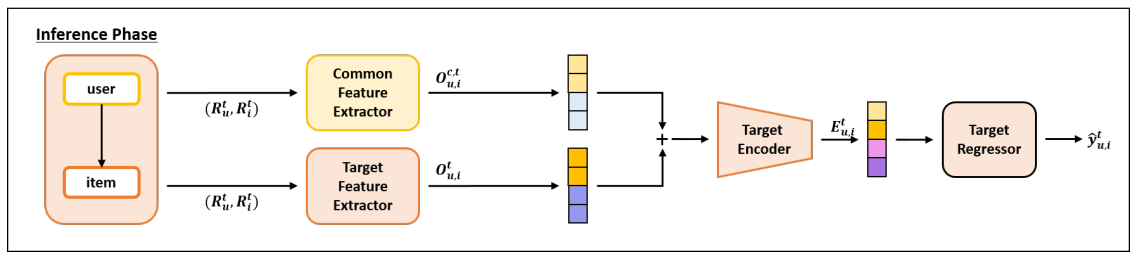
Then, for each domain, the review encoder generates a single vector , with extracted features 𝑂 by aligning them with individual review , . Finally, the regressor predicts an accurate rating that the user will give on an item. Here, shared parameters across two domains are common FE and a domain discriminator.
Tutorials
Attribute to Feature Mappings for Cold-Start Recommendations
Jupyter notebook. In this tutorial, we are learning the attribute to latent feature mapping with three different mapping functions - KNN, linear, and BPT-OPT. Also comparing with 2 baselines - CBF-KNN, and Random. We are using sample dataset but it can be extended to movielens dataset also.
LightFM Cold-start on MovieLens 10m dataset
Jupyter notebook. In this tutorial, we are training a hybrid recommender model on movielens 10m dataset. We are using Movie tags from tags-genome dataset as movie attributes. We are using LightFM library to implement the hybrid model.
EMCDR on MovieLens-Netflix dataset
Jupyter notebook. In this tutorial, we are training the EMCDR cross-domain recommender model on movielens-netflix dataset.
HERS Cold-start Recommendations on LastFM dataset
Jupyter notebook. In this tutorial, we are training the HERS (Heterogeneous Relations for Sparse and Cold-start Recommendation) model to recommend music items to cold-start users. The implementation is in Tensorflow 1x.
Collective Matrix Factorization on MovieLens 1m dataset
Jupyter notebook. In this tutorial, we are training CMF model on MovieLens 1m. Our experiments focus on two tasks: (i) predicting whether a user rated a particular movie: israted; and (ii) predicting the value of a rating for a particular movie: rating. There is a significant difference in the amount of data for the two tasks. In the israted problem we know whether or not a user rated a movie for all combinations of users and movies, so the ratings matrix has no missing values. In the rating problem we observe the relation only when a user rated a movie—unobserved combinations of users and movies have their data weight set to zero.
Double-Domain Recommendations on MovieLens 1m dataset
Jupyter notebook. In this tutorial, we are training DCDCSR model on MovieLens 1m dataset. Data has been divided into four parts D1,D2,D3 and D4. D1 and D2 have users common. D1 and D3 have items common. D1 and D4 have no user and no item in common. We test the model on the testing part of the dataset i.e., testing set from 10% dataset of D1 and calculated the MAE, RMSD, Precision and Recall values. Same is repeated with every dataset. Case 1 :- cross domain recommendation D1 is Target Domain and D4 is Source Domain. Case 2 :- cross domain recommendation D2 is Target Domain and D3 is Source Domain. Case 3 :- cross domain recommendation D3 is Target Domain and D2 is Source Domain. Case 4 :- cross domain recommendation D4 is Target Domain and D1 is Source Domain.
DropoutNet Cold-start Recommendation on CiteULike dataset
Jupyter notebook. In this tutorial, we are training DropoutNet model on CiteuLike dataset to recommend citation items to cold-start users.
MetaTL for Cold-start Recommendations on Amazon Electronics dataset
Jupyter notebook. In this tutorial, we are training MetaTL model on amazon electronics dataset to predict the next best item for a new cold-start user with 3 interactions (K=3).
TaNP Cold-start Recommender on LastFM dataset
Jupyter notebook. In this tutorial, we are training TaNP model to recommend music items to cold-start users. LastFM dataset division ratio of training, validation and test sets is 7:1:2. We only keep the users whose item-consumption history length is between 40 and 200. To generalize well with only a few samples, we set the number of interactions in support set as a small value (20/15/10), and remaining interactions are set as the query set. We only predict the score of each item in the query set for each user.
AGGN Cold-start Recommendation on MovieLens 100k
Jupyter notebook. In this tutorial, we are using attributed GNN model (AGNN) to predict the ratings a new user would give to a movie.
DaRE Cross-domain Recommender on Amazon Reviews dataset
Jupyter notebook. In this tutorial, we are training DaRE model on Amazon reviews dataset. We are using Amazon reviews' Musical_Instruments dataset as the source domain and Patio_Lawn_and_Garden as the target domain. We are also using GloVe word-embeddings to convert reviews' text into vectors.
References
- Wisdom of the better few: cold start recommendation via representative based rating elicitation. Nathan N. Liu, Xiangrui Meng, Chao Liu, Qiang Yang. 2011. RecSys. https://dl.acm.org/doi/10.1145/2043932.2043943
- Local Representative-Based Matrix Factorization for Cold-Start Recommendation. Lei Shi, Wayne Xin Zhao, Yi-Dong Shen. 2017. arXiv. https://dl.acm.org/doi/10.1145/3108148
- Fairness among New Items in Cold Start Recommender Systems. Ziwei Zhu , Jingu Kim , Trung Nguyen , Aish Fenton , James Caverlee. 2021. SIGIR. https://dl.acm.org/doi/abs/10.1145/3404835.3462948
- Personalized Transfer of User Preferences for Cross-domain Recommendation. Yongchun Zhu, Zhenwei Tang, Yudan Liu, Fuzhen Zhuang, Ruobing Xie, Xu Zhang, Leyu Lin, Qing He. 2021. arXiv. https://arxiv.org/abs/2110.11154v2
- Recommendation for New Users and New Items via Randomized Training and Mixture-of-Experts Transformation. Zhu et. al.. 2020. SIGIR. https://people.engr.tamu.edu/caverlee/pubs/zhu20cold.pdf
- Learning Attribute to Feature Mappings for Cold-Start Recommendations. Lucas Drumond, Christoph Freudenthaler, Steffen Rendle, Lars Schmidt-Thieme. 2010. ICDM. https://bit.ly/3Eh4NEK
- Meta-learning on Heterogeneous Information Networks for Cold-start Recommendation. Lu et. al.. 2020. KDD. https://yuanfulu.github.io/publication/KDD-MetaHIN.pdf
- MAMO: Memory-Augmented Meta-Optimization for Cold-start Recommendation. Manqing Dong, Feng Yuan, Lina Yao, Xiwei Xu, Liming Zhu. 2020. arXiv. https://arxiv.org/abs/2007.03183
- Methods and Metrics for Cold-Start Recommendations. Schein et al.. 2002. SIGIR. https://repository.upenn.edu/cgi/viewcontent.cgi?article=1141&context=cis_papers
- Pairwise Preference Regression for Cold-start Recommendation. Seung-Taek et al.. 2009. RecSys. http://www.gatsby.ucl.ac.uk/~chuwei/paper/p21-park.pdf
- LARA: Attribute-to-feature Adversarial Learning for New-item Recommendation. Changfeng Sun , Han Liu , Meng Liu , Zhaochun Ren , Tian Gan , Liqiang Nie. 2020. WSDM. https://dl.acm.org/doi/abs/10.1145/3336191.3371805
- Internal and Contextual Attention Network for Cold-start Multi-channel Matching in Recommendation. 2020. IJCAI. https://www.ijcai.org/proceedings/2020/0379.pdf
- Task-adaptive Neural Process for User Cold-Start Recommendation. Xixun Lin, Jia Wu, Chuan Zhou, Shirui Pan, Yanan Cao, Bin Wang. 2021. arXiv. https://arxiv.org/abs/2103.06137
- Content-aware Neural Hashing for Cold-start Recommendation. Casper Hansen, Christian Hansen, Jakob Grue Simonsen, Stephen Alstrup, Christina Lioma. 2020. arXiv. https://arxiv.org/abs/2006.00617
- Learning Attribute-to-Feature Mappings for Cold-Start Recommendations. Zeno Gantner, Lucas Drumond, Christoph Freudenthaler, Steffen Rendle, Lars Schmidt-Thieme. 2010. IEEE. https://ieeexplore.ieee.org/document/5693971
- HERS: Modeling Influential Contexts with Heterogeneous Relations for Sparse and Cold-Start Recommendation. Hu et. al.. 2019. arXiv. https://ojs.aaai.org//index.php/AAAI/article/view/4270
- CATN: Cross-Domain Recommendation for Cold-Start Users via Aspect Transfer Network. Cheng Zhao, Chenliang Li, Rong Xiao, Hongbo Deng, Aixin Sun. 2020. arXiv. https://arxiv.org/abs/2005.10549
- Improved Cold-Start Recommendation via Two-Level Bandit Algorithms. Rodrigues et. al.. 2017. arXiv. https://bit.ly/3jLtb9H
- DropoutNet: Addressing Cold Start in Recommender Systems. Maksims Volkovs, Guangwei Yu, Tomi Poutanen. 2017. arXiv. https://www.cs.toronto.edu/~mvolkovs/nips2017_deepcf.pdf
- Alleviating Cold-Start Problems in Recommendation through Pseudo-Labelling over Knowledge Graph. Riku Togashi, Mayu Otani, Shin'ichi Satoh. 2020. arXiv. https://arxiv.org/abs/2011.05061
- Sequential Recommendation for Cold-start Users with Meta Transitional Learning. Jianling Wang, Kaize Ding, James Caverlee. 2021. SIGIR. https://arxiv.org/abs/2107.06427
- Social Collaborative Filtering for Cold-start Recommendations. Sedhain et. al.. 2014. RecSys. https://ssanner.github.io/papers/anu/recsys14.pdf
- Addressing cold start in recommender systems: A semi-supervised co-training algorithm. Zhang et. al.. 2014. SIGIR. https://keg.cs.tsinghua.edu.cn/jietang/publications/SIGIR14-Zhang-et-al-cold-start-recommendation.pdf
- Metadata Embeddings for User and Item Cold-start Recommendations. Maciej Kula. 2015. arXiv. https://arxiv.org/abs/1507.08439
- Low-rank Linear Cold-Start Recommendation from Social Data. Sedhain et. al.. 2017. AAAI. https://mesuvash.github.io/assets/pdf/papers/loco-paper.pdf
- Cross-domain recommendation: an embedding and mapping approach. Man et al.. 2017. IJCAI. https://www.ijcai.org/proceedings/2017/0343.pdf
- Expediting Exploration by Attribute-to-Feature Mapping for Cold-Start Recommendations. Cohen et al.. 2017. RecSys. https://research.yahoo.com/mobstor/publication_attachments/Expediting Exploration by Atribute-to-Feature Mapping for Cold-Start Recommendations.pdf
- Handling Cold-Start Collaborative Filtering with Reinforcement Learning. Hima Varsha Dureddy, Zachary Kaden. 2018. arXiv. https://arxiv.org/abs/1806.06192
- Deeply Fusing Reviews and Contents for Cold Start Users in Cross-Domain Recommendation Systems. Fu et. al.. 2019. AAAI. https://ojs.aaai.org//index.php/AAAI/article/view/3773
- Zero-Shot Learning to Cold-Start Recommendation. Jingjing Li, Mengmeng Jing, Ke Lu, Lei Zhu, Yang Yang, Zi Huang. 2019. AAAI. https://arxiv.org/abs/1906.08511
- MeLU: Meta-Learned User Preference Estimator for Cold-Start Recommendation. Hoyeop Lee, Jinbae Im, Seongwon Jang, Hyunsouk Cho, Sehee Chung. 2019. KDD. https://arxiv.org/abs/1908.00413
- Relational Learning via Collective Matrix Factorization. Singh et. al.. 2008. KDD. http://www.cs.cmu.edu/~ggordon/singh-gordon-kdd-factorization.pdf
- Cross-Domain Recommendation for Cold-Start Users via Neighborhood Based Feature Mapping. Xinghua Wang, Zhaohui Peng, Senzhang Wang, Philip S. Yu, Wenjing Fu, Xiaoguang Hong. 2018. arXiv. https://arxiv.org/abs/1803.01617
- A Deep Framework for Cross-Domain and Cross-System Recommendations. Feng Zhu, Yan Wang, Chaochao Chen, Guanfeng Liu, Mehmet Orgun, Jia Wu. 2018. IJCAI. https://www.ijcai.org/proceedings/2018/0516.pdf
- Semi-Supervised Learning for Cross-Domain Recommendation to Cold-Start Users. SeongKu Kang , Junyoung Hwang , Dongha Lee , Hwanjo Yu. 2019. CIKM. https://dl.acm.org/doi/10.1145/3357384.3357914
- Transfer-Meta Framework for Cross-domain Recommendation to Cold-Start Users. Yongchun Zhu, Kaikai Ge, Fuzhen Zhuang, Ruobing Xie, Dongbo Xi, Xu Zhang, Leyu Lin, Qing He. 2021. SIGIR. https://arxiv.org/abs/2105.04785
- ANR: Aspect-based Neural Recommender. Jin Yao Chin, Kaiqi Zhao, Shafiq Joty, Gao Cong. 2018. CIKM. https://dl.acm.org/doi/10.1145/3269206.3271810
- A Survey on Cross-domain Recommendation: Taxonomies, Methods, and Future Directions. Tianzi Zang, Yanmin Zhu, Haobing Liu, Ruohan Zhang, Jiadi Yu. 2021. arXiv. https://arxiv.org/abs/2108.03357
- Cross-Domain Recommendation: Challenges, Progress, and Prospects. Feng Zhu, Yan Wang, Chaochao Chen, Jun Zhou, Longfei Li, Guanfeng Liu. 2021. arXiv. https://arxiv.org/abs/2103.01696
- CMML: Contextual Modulation Meta Learning for Cold-Start Recommendation. Xidong Feng, Chen Chen, Dong Li, Mengchen Zhao, Jianye Hao, Jun Wang. 2021. arXiv. https://arxiv.org/abs/2108.10511v4
- Tackling the Cold Start Problem in Recommender Systems
- In-session Recommendation in eCommerce notebook