1mg Prod2vec
Gurgaon (India) based 1mg is an online pharmacy and healthcare platform that offers medicines, lab tests, and doctor consultations. Launched in 2013 as Healthkartplus, 1mg initially focussed on the alternative medicine space with AYUSH products. Over the years, it rebranded itself as 1mg which is an online pharmacy and healthcare platform that offers medicines, lab tests, and doctor consultations. Today, 1mg provides a wide range of healthcare services. 1mg also provides information on medicines. It facilitates lab tests at home. At present, the platform has about 2,000 tests and 120 verified labs listed and users can consult a doctor across 20 specialties. The company earns from its services like diagnostics, sale of medicines, preventive healthcare, and online consultations, as well as through native ads on its platform.
They make personalized recommendations and similar product recommendations. They show these recommendations on homepage, search page, cart page, and product page. Their first goal is to increase user engagement and discovery, measured using CTR (click-through rate). Secondary goal is the faster purchase or conversion (measured using add-to-cart and purchase counts).
They use graph representation algorithms like Meta Prod2Vec to build user and item embeddings, which are utilised in neural collaborative filtering and models like BERT, GPT-2, to enhance personalisation of product recommendations; this has significantly improved the click-through rate (CTR) and product conversions.
Item embeddings - To learn item embeddings, they initially used TF-IDF method on product descriptions and other meta-info like product tags, categories. The size was 30K. They also tried an alternative method based on BERT. They fine-tuned a BERT model on description text. The size of this embedding is 786. They mainly faced 3 challenges here - 1) meta-info is inconsistent and sparse, 2) detailed text description was available for ~20% of catalogue, and 3) longer pieces of text can't be encoded in pre-trained BERT model. So they tried another alternative based on graph networks. In this, they first used deepwalk algorithm to generate fabricated sequences of user sessions. It helped not only in combating non-homogeneity in items, but also helped in balanced sampling between popular and unpopular items. They they applied word2vec on these fabricated sesions to learn the embeddings. But still the performance was not good enough. So they decided to add product's meta-info to improve the performance.
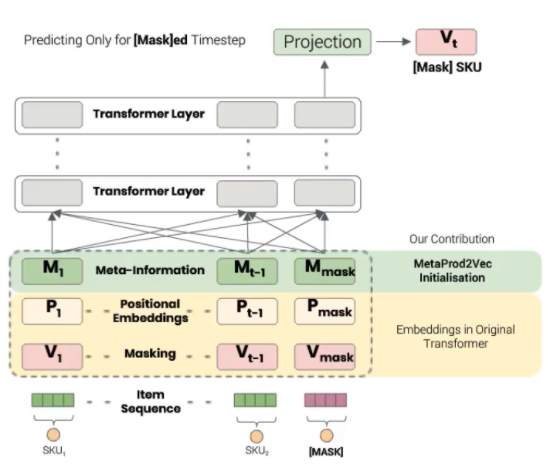
Initially they feed these embeddings into a sequential model. They chose transformer-based model over LSTM-based model to reduce training time, and longer memory due to attention mechanism. The following diagram shows the overall model architecture:
They used the following setup for testing out this transformer-based model:
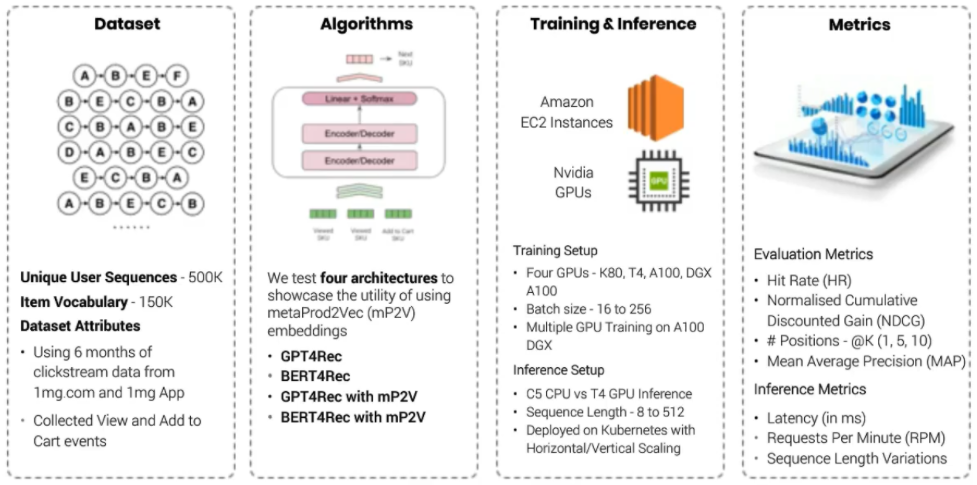
On serving side, initially they tried to served their GPT4Rec model using K8s cluster on a AWS C5 instance (with optimized TF Serving build) but average latency was 500ms at 1000 requests per minute (RPM), with sequence length of just 8. Then they tried another alternative. They optimized their model with TensorRT and used T4 GPU instances using same K8s. This time they get an average latency of 150ms at 7000 RPM, with sequence length of upto 512. It was 1500x speed-up at half the cost.
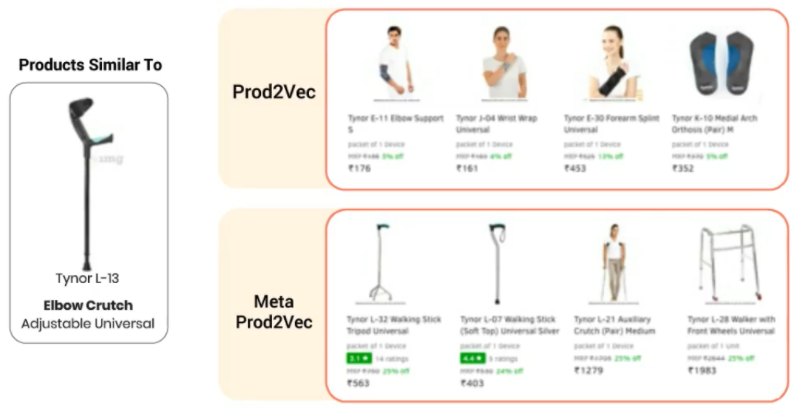
Initially they were using simple matrix factorization. It increased the CTR by 10% and conversion by 80% over the static-list baseline. But this approach was not scalable beyond few million users. Then they used item-item association-rule mining. It is computationally cheap and used for 64% of users who had previous item interactions. It increased CTR by whopping 250%, and this was highly scalable to solve cold-start issue. But it reduced conversion by 5% over static-list baseline. Then they started moving towards deep learning approaches and tried neural collaborative filtering. This was also scalable to million of users. It covered 18% of users (compared to 64% in association rule-mining) with 5+ item interactions to get better results. It increased add-to-cart conversions by 300%, and CTR by 20%. But this approach was not able to solve the cold-start issue. Now, they started using next-event-prediction models. It uses user-item temporal sequences + item meta information. It is capable of real-time learning and gives better cold-start performance. The final results are yet to come but method look promising. Also, they show similar products on item page by directly using cosine similarity metric on embeddings. TF-IDF gave 6.5% increase in CTR, and prod2vec improved by additional 15% on top of TF-IDF. Meta-prod2vec improved it further by 17% on top of prod2vec.
Key takeaways
- Transformer-based sequential models are very much capable of modeling sequential patterns in recommendation systems, and should be tried if data size is not an issue.
- Randomwalk or deepwalk with word2vec is a deadly combo for learning embeddings. It is a collaborative method.
- Using meta-info with this collaborative-type method is even more powerful method for embeddings.
- Serving on GPU instances is not only faster but might cost less, especially when serving to a large user group.