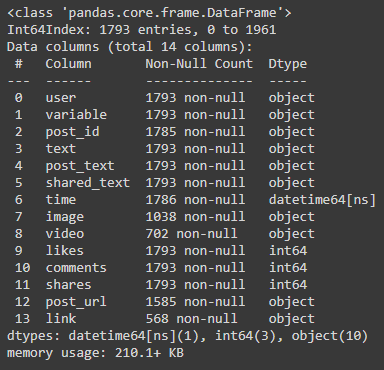
build.py → this script will take the training data as input and save all the required files in the same working directory
recommend.py → this script will take the user query as input and predict top-K BRM recommendations
Variables (during recommendation, you will be asked 2–3 choices, the meaning of those choices are as following)
top-K — how many top items you want to get in recommendation
secondary items: this will determine how many similar items you would like to add in consideration, for each primary matching item
sorted by frequency: since multiple input queries might point to same output, therefore this option allows to take that frequence count of outputs in consideration and will move the more frequent items at the top.
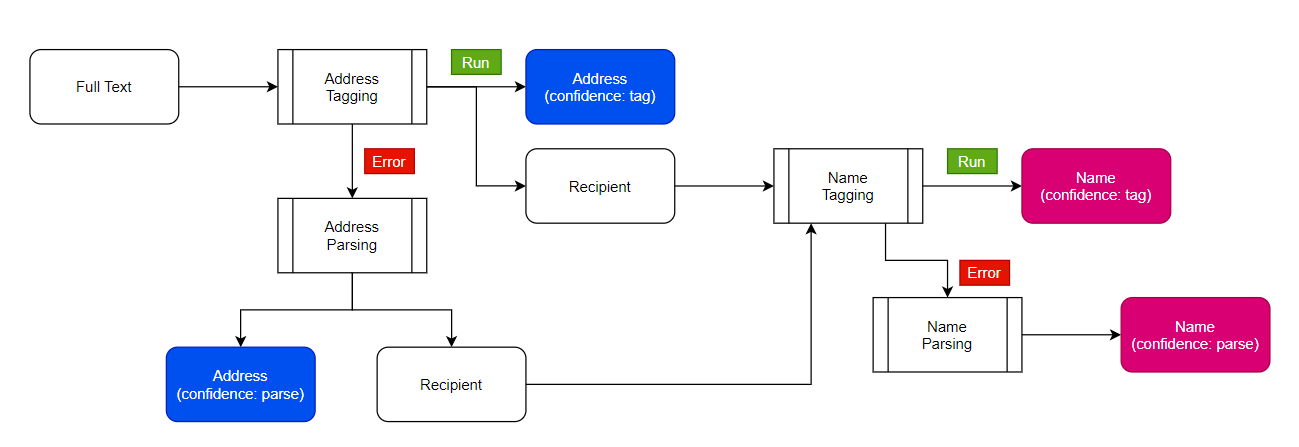
Create an API that can parse and classify names and addresses given a string. We tried probablepeople and usaddress. These work well separately but need the functionality of these packages combined, and better accuracy than what probablepeople provides.
For the API, I'd like to mimic this with some minor modifications.
A few examples:
"KING JOHN A 5643 ROUTH CREEK PKWY #1314 RICHARDSON TEXAS 750820146 UNITED STATES OF AMERICA" would return type: person; first_name: JOHN; last_name: KING; middle: A; street_address: 5643 ROUTH CREEK PKWY #1314; city: RICHARDSON; state: TEXAS; zip: 75082-0146; country: UNITED STATES OF AMERICA.
"THRM NGUYEN LIVING TRUST 2720 SUMMERTREE CARROLLTON HOUSTON TEXAS 750062646 UNITED STATES OF AMERICA" would return type: entity; name: THRM NGUYEN LIVING TRUST; street_address: 2720 SUMMERTREE CARROLLTON; state: TEXAS; city: HOUSTON; zip: 75006-2646; country: UNITED STATES OF AMERICA.
Input Instance: ANDERSON, EARLINE 1423 NEW YORK AVE FORT WORTH, TX 76104 7522
Output Tags:- <Type> - Person/Household/Corporation <GivenName>, <MiddleName>, <Surname> - if Type Person/Household <Name> - Full Name - if Type Person <Name> - Household - if Type Household <Name> - Corporation - If Type Corporation <Address> - Full Address <StreetAddress>, <City>, <State>, <Zipcode>, <Country> ~~NameConfidence, AddrConfidence~~
Name Endpoint
Input Instance: ANDERSON, EARLINE
Output Tags:- - <Type> - Person/Household/Corporation - <GivenName>, <MiddleName>, <Surname> - if Type Person/Household - <Name> - Full Name - if Type Person - <Name> - Household - if Type Household - <Name> - Corporation - If Type Corporation - ~~NameConfidence~~
Address Endpoint
Input Instance: 1423 NEW YORK AVE FORT WORTH, TX 76104 7522
Deployment as REST api with 3 endpoints - name parse, address parse and whole string parse
Framework
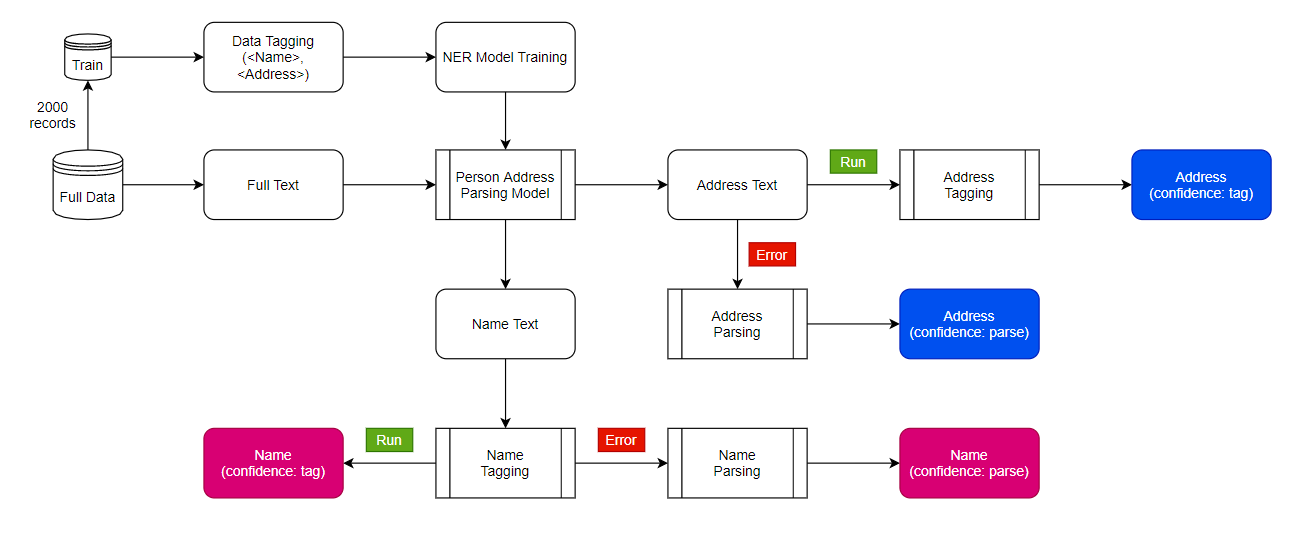
Tagging process
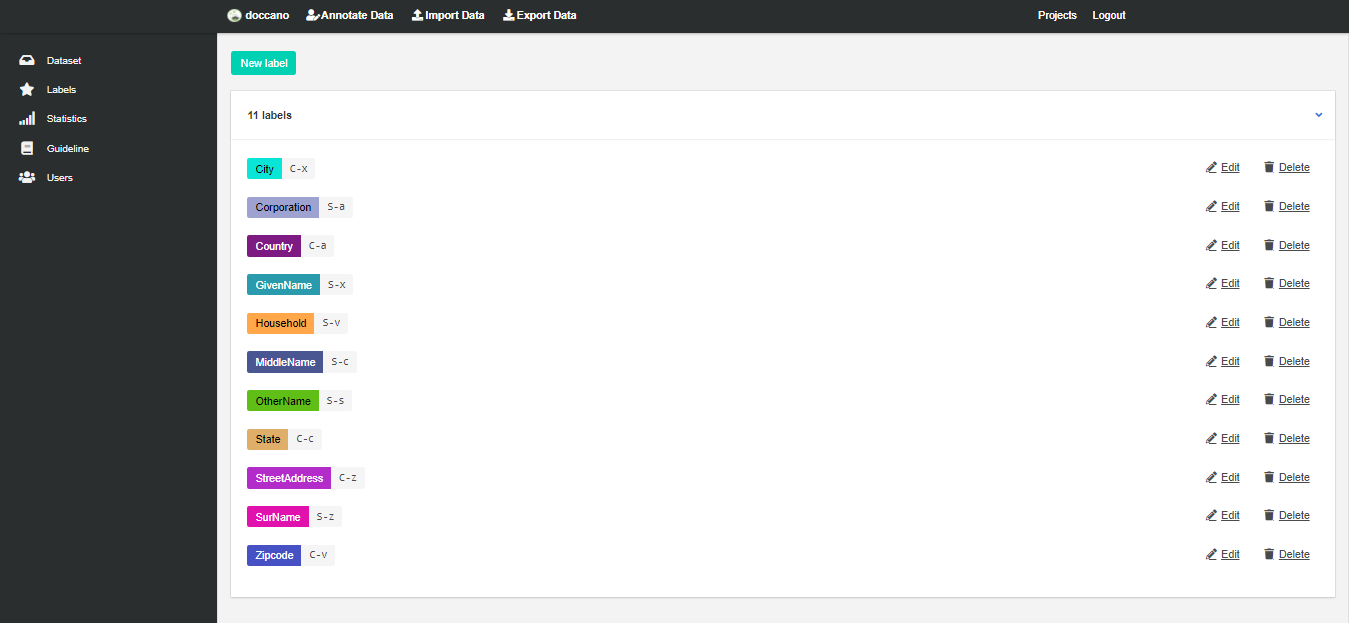
I used Doccano (https://github.com/doccano/doccano) for labeling the dataset. This tool is open-source and free to use. I deployed it with a one-click Heroku service (fig 1). After launching the app, log in with the provided credentials, and create a project (fig 2). Create the labels and upload the dataset (fig 3). Start the annotation process (fig 4). Now after enough annotations (you do not need complete all annotations in one go), go back to projects > edit section and export the data (fig 5). Bring the exported JSON file in python and run the model training code. The whole model will automatically get trained on the new annotations. To make the training faster, you can use Nvidia GPU support.
fig 1: screenshot taken from Doccano's github page
fig 2: Doccano's deployed app homepage
fig 3: create the labels. I defined these labels for my project
fig 5: export the annotations
Model
I first tried the Spacy NER blank model but it was not giving high-quality results. So I moved to the PyTorch Flair NER model. This model was a way faster (5 min training because of GPU compatibility comparing to 1-hour Spacy training time) and also much more accurate. F1 results for all tags were near perfect (score of 1). This score will increase further with more labeled data. This model is production-ready.
Inference
For OOR, I directly used the model's output for core tagging and created the aggregated tags like recipient (aggregation of name tags) and address (aggregation of address tags like city and state) using simple conditional concatenation. For only Name and only Address inference, I added the dummy address in name text and dummy name in address text. This way, I passed the text in same model and later on filtered the required tags as output.
Deliverable - Two paragraph-level distance outputs for L and Q, each has 35 columns.
For each paragraph, we need to calculate the L1 distance of consecutive sentences in this paragraph, and then generate the mean and standard deviation of all these distances for this paragraph. For example, say the paragraph 1 starts from sentence1 and ends with sentence 5. First, calculate the L1 distances for L1(1,2), L1(2,3), L1(3,4) and L1(4,5) and then calculate the mean and standard deviation of the 4 distances. In the end we got two measures for this paragraph: L1_m and L1_std. Similarly, we need to calculate the mean and standard deviation using L2 distance, plus a simple mean and deviation of the distances. We use 6 different embeddings: all dimensions of BERT embeddings, 100,200 and 300 dimensions of PCA Bert embeddings (PCA is a dimension reduction technique
In the end, we will have 35 columns for each paragraph : Paragraph ID +#sentences in the paragraph +(cosine_m, cosine_std,cossimillarity_m, cosimmilarity_std, L1_m, L1_std, L2_m, L2_std ) – by- ( all, 100, 200, 300)= 3+8*4.
Note: for paragraph that only has 1 sentence, the std measures are empty.
Splitting paragraphs into sentences using 1) NLTK Sentence Tokenizer, 2) Spacy Sentence Tokenizer and, on two additional symbols : and ...
Text Preprocessing: Lowercasing, Removing Non-alphanumeric characters, Removing Null records, Removing sentence records (rows) having less than 3 words.
TF-IDF vectorization
LSA over document-term matrix
Cosine distance calculation of adjacent sentences (rows)
// car or truck or no mention of vehicle type means Cyber Truck // SUV mention means Model X const one = "I'm looking for a fast suv that I can go camping without worrying about recharging".; const two = "cheap red car that is able to go long distances"; const three = "i am looking for a daily driver that i can charge everyday, do not need any extras"; const four = "i like to go offroading a lot on my jeep and i want to do the same with the truck"; const five = "i want the most basic suv possible"; const six = "I want all of the addons"; // mentions of large family or many people means model x const seven = "I have a big family and want to be able to take them around town and run errands without worrying about charging";
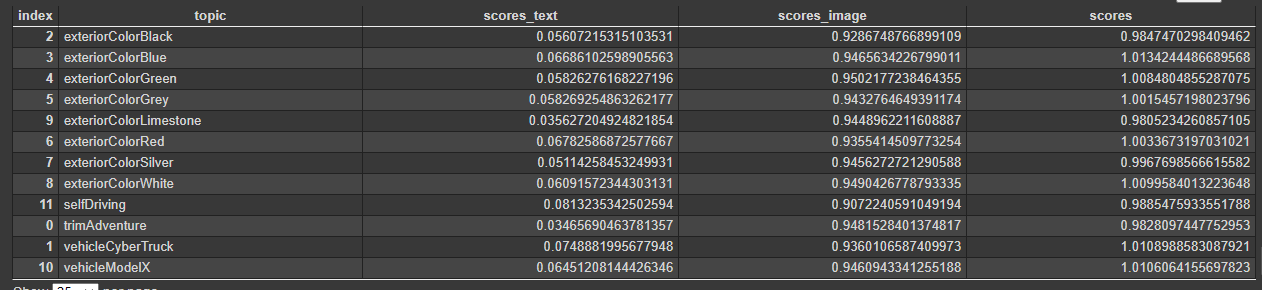
import numpy as np import pandas as pd import tensorflow_hub as hub from itertools import product from sklearn.preprocessing import OneHotEncoder from sklearn.metrics.pairwise import cosine_similarity vehicle =['modelX','cyberTruck'] trim =['adventure','base'] exteriorColor =['whiteExterior','blueExterior','silverExterior','greyExterior','blackExterior','redExterior','greenExterior'] wheels =['20AllTerrain','21AllSeason','22Performance'] tonneau =['powerTonneau','manualTonneau'] interiorColor =['blackInterior','greyInterior','greenInterior'] range=['standardRange','mediumRange','extendedRange'] packages =['offroadPackage','matchingSpareTire','offroadPackage,matchingSpareTire','None'] interiorAddons =['wirelessCharger','None'] software =['selfDrivingPackage','None'] specs_cols =['vehicle','trim','exteriorColor','wheels','tonneau','interiorColor','range','packages','interiorAddons','software'] specs = pd.DataFrame(list(product(vehicle, trim, exteriorColor, wheels, tonneau, interiorColor,range, packages, interiorAddons, software)), columns=specs_cols) enc = OneHotEncoder(handle_unknown='error', sparse=False) specs = pd.DataFrame(enc.fit_transform(specs)) specs_ids = specs.index.tolist() query_list =["I'm looking for a fast suv that I can go camping without worrying about recharging", "cheap red car that is able to go long distances", "i am looking for a daily driver that i can charge everyday, do not need any extras", "i like to go offroading a lot on my jeep and i want to do the same with the truck", "i want the most basic suv possible", "I want all of the addons", "I have a big family and want to be able to take them around town and run errands without worrying about charging"] queries = pd.DataFrame(query_list, columns=['query']) query_ids = queries.index.tolist() const_oneJSON ={ 'vehicle':'modelX', 'trim':'adventure', 'exteriorColor':'whiteExterior', 'wheels':"22Performance", 'tonneau':"powerTonneau", 'packages':"None", 'interiorAddons':"None", 'interiorColor':"blackInterior", 'range':"extendedRange", 'software':"None", } const_twoJSON ={ 'vehicle':'cyberTruck', 'trim':'base', 'exteriorColor':'whiteExterior', 'wheels':"21AllSeason", 'tonneau':"powerTonneau", 'packages':"None", 'interiorAddons':"None", 'interiorColor':"blackInterior", 'range':"extendedRange", 'software':"None", } const_threeJSON ={ 'vehicle':'cyberTruck', 'trim':'base', 'exteriorColor':'whiteExterior', 'wheels':"21AllSeason", 'tonneau':"powerTonneau", 'packages':"None", 'interiorAddons':"None", 'interiorColor':"blackInterior", 'range':"standardRange", 'software':"None", } const_fourJSON ={ 'vehicle':'cyberTruck', 'trim':'adventure', 'exteriorColor':'whiteExterior', 'wheels':"20AllTerrain", 'tonneau':"powerTonneau", 'packages':"offroadPackage,matchingSpareTire", 'interiorAddons':"None", 'interiorColor':"blackInterior", 'range':"extendedRange", 'software':"None", } const_fiveJSON ={ 'vehicle':'modelX', 'trim':'base', 'exteriorColor':'whiteExterior', 'wheels':"20AllTerrain", 'tonneau':"manualTonneau", 'packages':"None", 'interiorAddons':"None", 'interiorColor':"blackInterior", 'range':"standardRange", 'software':"None", } const_sixJSON ={ 'vehicle':'cyberTruck', 'trim':'adventure', 'exteriorColor':'whiteExterior', 'wheels':"20AllTerrain", 'tonneau':"powerTonneau", 'packages':"offroadPackage,matchingSpareTire", 'interiorAddons':"wirelessCharger", 'interiorColor':"blackInterior", 'range':"extendedRange", 'software':"selfDrivingPackage", } const_sevenJSON ={ 'vehicle':'modelX', 'trim':'base', 'exteriorColor':'whiteExterior', 'wheels':"21AllSeason", 'tonneau':"powerTonneau", 'packages':"None", 'interiorAddons':"None", 'interiorColor':"blackInterior", 'range':"mediumRange", 'software':"None", } historical_data = pd.DataFrame([const_oneJSON, const_twoJSON, const_threeJSON, const_fourJSON, const_fiveJSON, const_sixJSON, const_sevenJSON]) input_vec = enc.transform([specs_frame.append(historical_data.iloc[0], sort=False).iloc[-1]]) idx = np.argsort(-cosine_similarity(input_vec, specs.values))[0,:][:1] rslt = enc.inverse_transform([specs.iloc[idx]]) interactions = pd.DataFrame(columns=['query_id','specs_id']) interactions['query_id']= queries.index.tolist() input_vecs = enc.transform(specs_frame.append(historical_data, sort=False).iloc[-len(historical_data):]) interactions['specs_id']= np.argsort(-cosine_similarity(input_vecs, specs.values))[:,0] module_url ="https://tfhub.dev/google/universal-sentence-encoder/4" embed_model = hub.load(module_url) defembed(input): return embed_model(input) query_vecs = embed(queries['query'].tolist()).numpy() _query =input('Please enter query: ')or'i want the most basic suv possible' _query_vec = embed([_query]).numpy() _match_qid = np.argsort(-cosine_similarity(_query_vec, query_vecs))[0,:][:1] _match_sid = interactions.loc[interactions['query_id']==_match_qid[0],'specs_id'].values[0] input_vec = enc.transform([specs_frame.append(historical_data.iloc[0], sort=False).iloc[-1]]) idx = np.argsort(-cosine_similarity([specs.iloc[_match_sid].values], specs.values))[0,:][:5] results =[] for x in idx: results.append(enc.inverse_transform([specs.iloc[x]])) _temp = np.array(results).reshape(5,-1) _temp = pd.DataFrame(_temp, columns=specs_frame.columns) print(_temp)
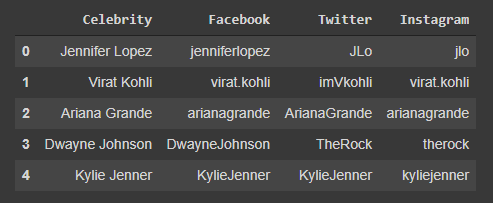
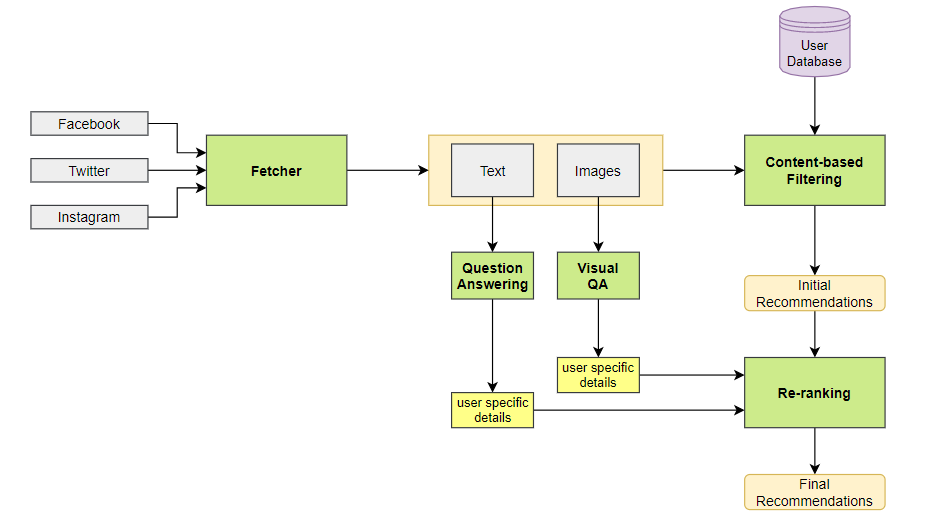
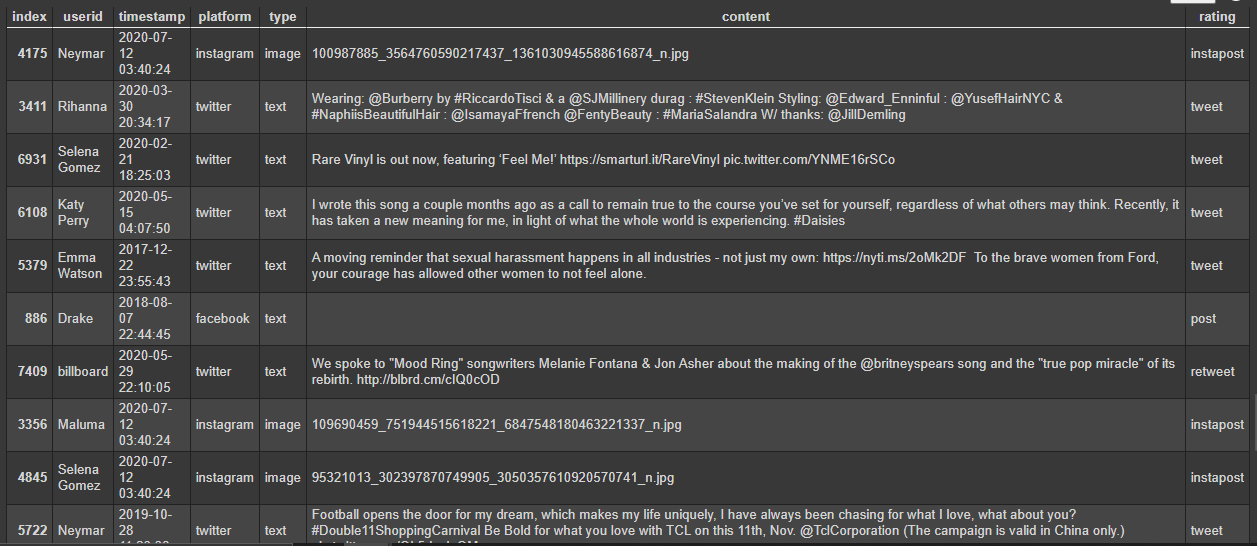
API with 3 input fields - Facebook username, Twitter handle & Instagram username
The system will automatically scrap the user's publicly available text and images from these 3 social media platforms and provide a list of recommendations from most to least preferred product
A bot that logs daily wellness data to a spreadsheet (using the Airtable API), to help the user keep track of their health goals. Connect the assistant to a messaging channel—Twilio—so users can talk to the assistant via text message and Whatsapp.