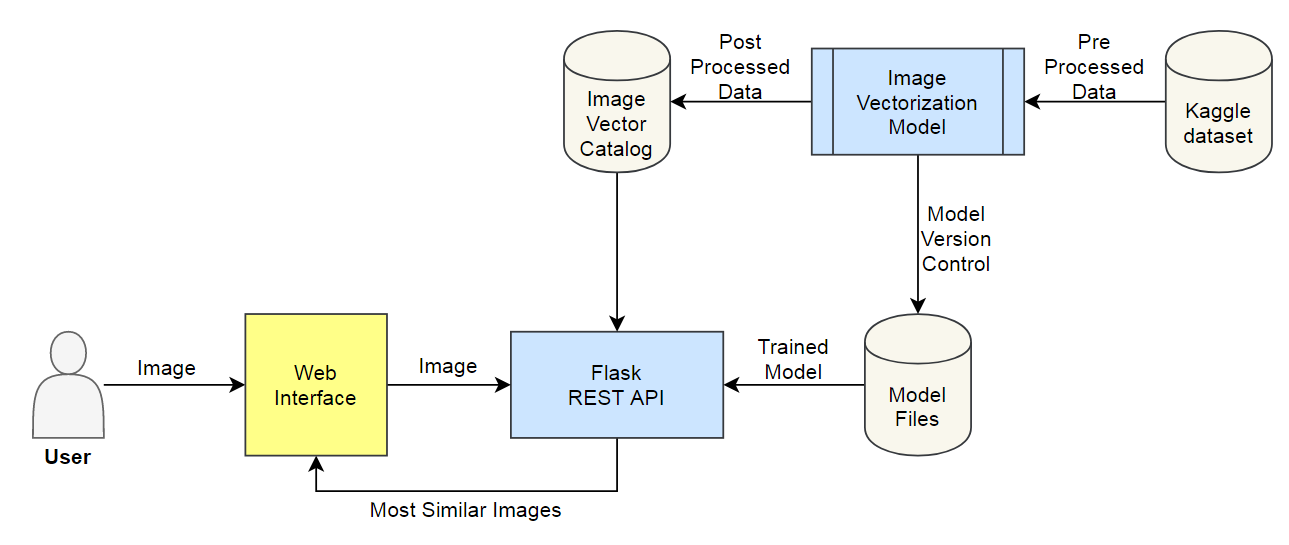
build.py → this script will take the training data as input and save all the required files in the same working directory
recommend.py → this script will take the user query as input and predict top-K BRM recommendations
Variables (during recommendation, you will be asked 2–3 choices, the meaning of those choices are as following)
top-K — how many top items you want to get in recommendation
secondary items: this will determine how many similar items you would like to add in consideration, for each primary matching item
sorted by frequency: since multiple input queries might point to same output, therefore this option allows to take that frequence count of outputs in consideration and will move the more frequent items at the top.
We can select any pre-trained image classification model. These models are commonly known as encoders because their job is to encode an image into a feature vector. I analyzed four encoders named 1) MobileNet, 2) EfficientNet, 3) ResNet and 4) BiT. After basic research, I decided to select BiT model because of its performance and state-of-the-art nature. I selected the BiT-M-50x3 variant of model which is of size 748 MB. More details about this architecture can be found on the official page here.
Images are represented in a fixed-length feature vector format. For the given input vector, we need to find the TopK most similar vectors, keeping the memory efficiency and real-time retrival objective in mind. I explored the most popular techniques and listed down five of them: Annoy, Cosine distance, L1 distance, Locally Sensitive Hashing (LSH) and Image Deep Ranking. I selected Annoy because of its fast and efficient nature. More details about Annoy can be found on the official page here.
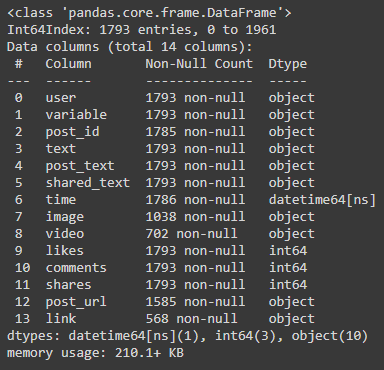
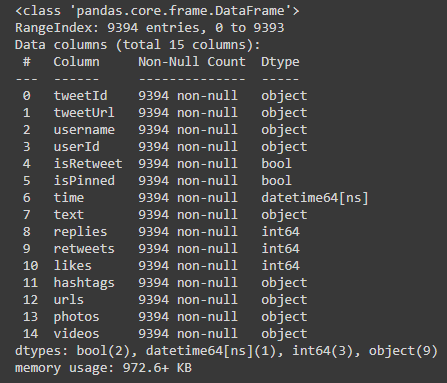
Download the raw image dataset into a directory. Categorize these images into their respective category directories. Make sure that images are of the same type, JPEG recommended. We will also process the metadata and store it in a serialized file, CSV recommended.
Download the pre-trained image model and add two additional layers on top of that: the first layer is a feature vector layer and the second layer is the classification layer. We will only train these 2 layers on our data and after training, we will select the feature vector layer as the output of our fine-tuned encoder. After fine-tuning the model, we will save the feature extractor for later use.
Now, we will use the encoder (prepared in step 2) to encode the images (prepared in step 1). We will save feature vector of each image as an array in a directory. After processing, we will save these embeddings for later use.
We will assign a unique id to each image and create dictionaries to locate information of this image: 1) Image id to Image name dictionary, 2) Image id to image feature vector dictionary, and 3) (optional) Image id to metadata product id dictionary. We will also create an image id to image feature vector indexing. Then we will save these dictionaries and index object for later use.
We will receive an image from user, encode it with our image encoder, find TopK similar vectors using Indexing object, and retrieve the image (and metadata) using dictionaries. We send these images (and metadata) back to the user.
Deployment
The API was deployed on AWS cloud infrastructure using AWS Elastic Beanstalk service.
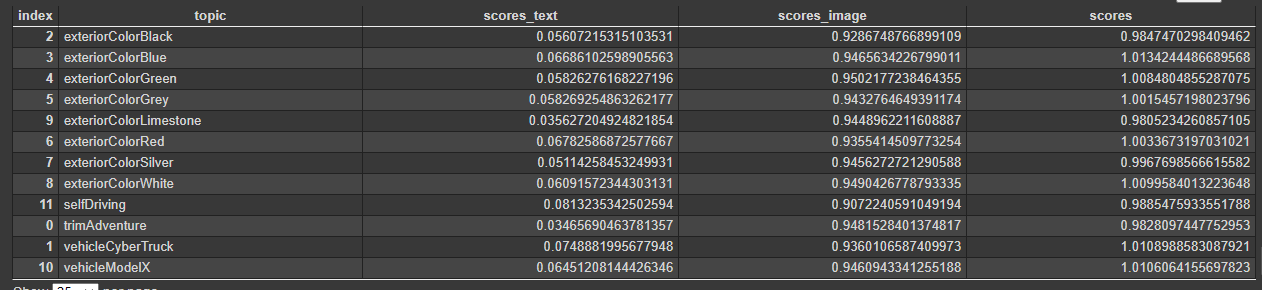
Deliverable - Two paragraph-level distance outputs for L and Q, each has 35 columns.
For each paragraph, we need to calculate the L1 distance of consecutive sentences in this paragraph, and then generate the mean and standard deviation of all these distances for this paragraph. For example, say the paragraph 1 starts from sentence1 and ends with sentence 5. First, calculate the L1 distances for L1(1,2), L1(2,3), L1(3,4) and L1(4,5) and then calculate the mean and standard deviation of the 4 distances. In the end we got two measures for this paragraph: L1_m and L1_std. Similarly, we need to calculate the mean and standard deviation using L2 distance, plus a simple mean and deviation of the distances. We use 6 different embeddings: all dimensions of BERT embeddings, 100,200 and 300 dimensions of PCA Bert embeddings (PCA is a dimension reduction technique
In the end, we will have 35 columns for each paragraph : Paragraph ID +#sentences in the paragraph +(cosine_m, cosine_std,cossimillarity_m, cosimmilarity_std, L1_m, L1_std, L2_m, L2_std ) – by- ( all, 100, 200, 300)= 3+8*4.
Note: for paragraph that only has 1 sentence, the std measures are empty.
Splitting paragraphs into sentences using 1) NLTK Sentence Tokenizer, 2) Spacy Sentence Tokenizer and, on two additional symbols : and ...
Text Preprocessing: Lowercasing, Removing Non-alphanumeric characters, Removing Null records, Removing sentence records (rows) having less than 3 words.
TF-IDF vectorization
LSA over document-term matrix
Cosine distance calculation of adjacent sentences (rows)
// car or truck or no mention of vehicle type means Cyber Truck // SUV mention means Model X const one = "I'm looking for a fast suv that I can go camping without worrying about recharging".; const two = "cheap red car that is able to go long distances"; const three = "i am looking for a daily driver that i can charge everyday, do not need any extras"; const four = "i like to go offroading a lot on my jeep and i want to do the same with the truck"; const five = "i want the most basic suv possible"; const six = "I want all of the addons"; // mentions of large family or many people means model x const seven = "I have a big family and want to be able to take them around town and run errands without worrying about charging";
import numpy as np import pandas as pd import tensorflow_hub as hub from itertools import product from sklearn.preprocessing import OneHotEncoder from sklearn.metrics.pairwise import cosine_similarity vehicle =['modelX','cyberTruck'] trim =['adventure','base'] exteriorColor =['whiteExterior','blueExterior','silverExterior','greyExterior','blackExterior','redExterior','greenExterior'] wheels =['20AllTerrain','21AllSeason','22Performance'] tonneau =['powerTonneau','manualTonneau'] interiorColor =['blackInterior','greyInterior','greenInterior'] range=['standardRange','mediumRange','extendedRange'] packages =['offroadPackage','matchingSpareTire','offroadPackage,matchingSpareTire','None'] interiorAddons =['wirelessCharger','None'] software =['selfDrivingPackage','None'] specs_cols =['vehicle','trim','exteriorColor','wheels','tonneau','interiorColor','range','packages','interiorAddons','software'] specs = pd.DataFrame(list(product(vehicle, trim, exteriorColor, wheels, tonneau, interiorColor,range, packages, interiorAddons, software)), columns=specs_cols) enc = OneHotEncoder(handle_unknown='error', sparse=False) specs = pd.DataFrame(enc.fit_transform(specs)) specs_ids = specs.index.tolist() query_list =["I'm looking for a fast suv that I can go camping without worrying about recharging", "cheap red car that is able to go long distances", "i am looking for a daily driver that i can charge everyday, do not need any extras", "i like to go offroading a lot on my jeep and i want to do the same with the truck", "i want the most basic suv possible", "I want all of the addons", "I have a big family and want to be able to take them around town and run errands without worrying about charging"] queries = pd.DataFrame(query_list, columns=['query']) query_ids = queries.index.tolist() const_oneJSON ={ 'vehicle':'modelX', 'trim':'adventure', 'exteriorColor':'whiteExterior', 'wheels':"22Performance", 'tonneau':"powerTonneau", 'packages':"None", 'interiorAddons':"None", 'interiorColor':"blackInterior", 'range':"extendedRange", 'software':"None", } const_twoJSON ={ 'vehicle':'cyberTruck', 'trim':'base', 'exteriorColor':'whiteExterior', 'wheels':"21AllSeason", 'tonneau':"powerTonneau", 'packages':"None", 'interiorAddons':"None", 'interiorColor':"blackInterior", 'range':"extendedRange", 'software':"None", } const_threeJSON ={ 'vehicle':'cyberTruck', 'trim':'base', 'exteriorColor':'whiteExterior', 'wheels':"21AllSeason", 'tonneau':"powerTonneau", 'packages':"None", 'interiorAddons':"None", 'interiorColor':"blackInterior", 'range':"standardRange", 'software':"None", } const_fourJSON ={ 'vehicle':'cyberTruck', 'trim':'adventure', 'exteriorColor':'whiteExterior', 'wheels':"20AllTerrain", 'tonneau':"powerTonneau", 'packages':"offroadPackage,matchingSpareTire", 'interiorAddons':"None", 'interiorColor':"blackInterior", 'range':"extendedRange", 'software':"None", } const_fiveJSON ={ 'vehicle':'modelX', 'trim':'base', 'exteriorColor':'whiteExterior', 'wheels':"20AllTerrain", 'tonneau':"manualTonneau", 'packages':"None", 'interiorAddons':"None", 'interiorColor':"blackInterior", 'range':"standardRange", 'software':"None", } const_sixJSON ={ 'vehicle':'cyberTruck', 'trim':'adventure', 'exteriorColor':'whiteExterior', 'wheels':"20AllTerrain", 'tonneau':"powerTonneau", 'packages':"offroadPackage,matchingSpareTire", 'interiorAddons':"wirelessCharger", 'interiorColor':"blackInterior", 'range':"extendedRange", 'software':"selfDrivingPackage", } const_sevenJSON ={ 'vehicle':'modelX', 'trim':'base', 'exteriorColor':'whiteExterior', 'wheels':"21AllSeason", 'tonneau':"powerTonneau", 'packages':"None", 'interiorAddons':"None", 'interiorColor':"blackInterior", 'range':"mediumRange", 'software':"None", } historical_data = pd.DataFrame([const_oneJSON, const_twoJSON, const_threeJSON, const_fourJSON, const_fiveJSON, const_sixJSON, const_sevenJSON]) input_vec = enc.transform([specs_frame.append(historical_data.iloc[0], sort=False).iloc[-1]]) idx = np.argsort(-cosine_similarity(input_vec, specs.values))[0,:][:1] rslt = enc.inverse_transform([specs.iloc[idx]]) interactions = pd.DataFrame(columns=['query_id','specs_id']) interactions['query_id']= queries.index.tolist() input_vecs = enc.transform(specs_frame.append(historical_data, sort=False).iloc[-len(historical_data):]) interactions['specs_id']= np.argsort(-cosine_similarity(input_vecs, specs.values))[:,0] module_url ="https://tfhub.dev/google/universal-sentence-encoder/4" embed_model = hub.load(module_url) defembed(input): return embed_model(input) query_vecs = embed(queries['query'].tolist()).numpy() _query =input('Please enter query: ')or'i want the most basic suv possible' _query_vec = embed([_query]).numpy() _match_qid = np.argsort(-cosine_similarity(_query_vec, query_vecs))[0,:][:1] _match_sid = interactions.loc[interactions['query_id']==_match_qid[0],'specs_id'].values[0] input_vec = enc.transform([specs_frame.append(historical_data.iloc[0], sort=False).iloc[-1]]) idx = np.argsort(-cosine_similarity([specs.iloc[_match_sid].values], specs.values))[0,:][:5] results =[] for x in idx: results.append(enc.inverse_transform([specs.iloc[x]])) _temp = np.array(results).reshape(5,-1) _temp = pd.DataFrame(_temp, columns=specs_frame.columns) print(_temp)
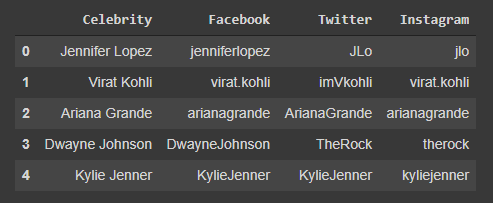
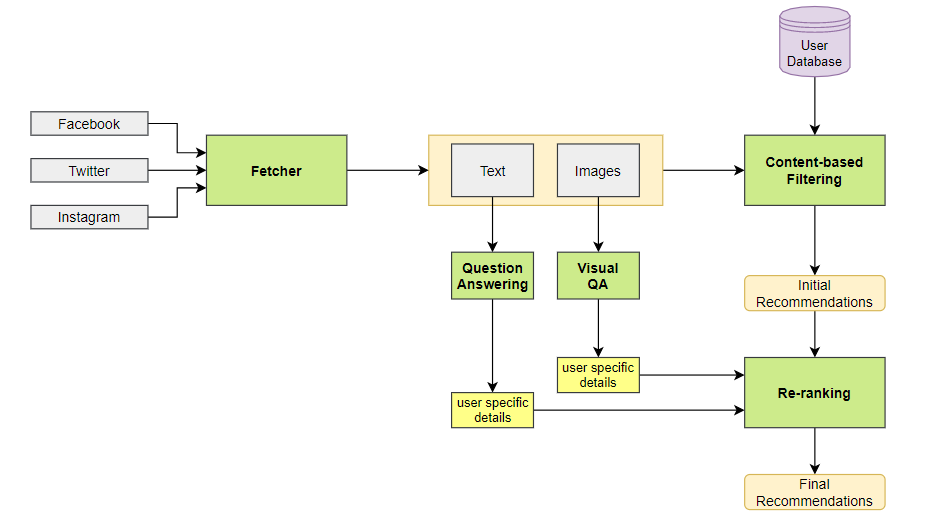
API with 3 input fields - Facebook username, Twitter handle & Instagram username
The system will automatically scrap the user's publicly available text and images from these 3 social media platforms and provide a list of recommendations from most to least preferred product