Choice of variables
Image Encoder
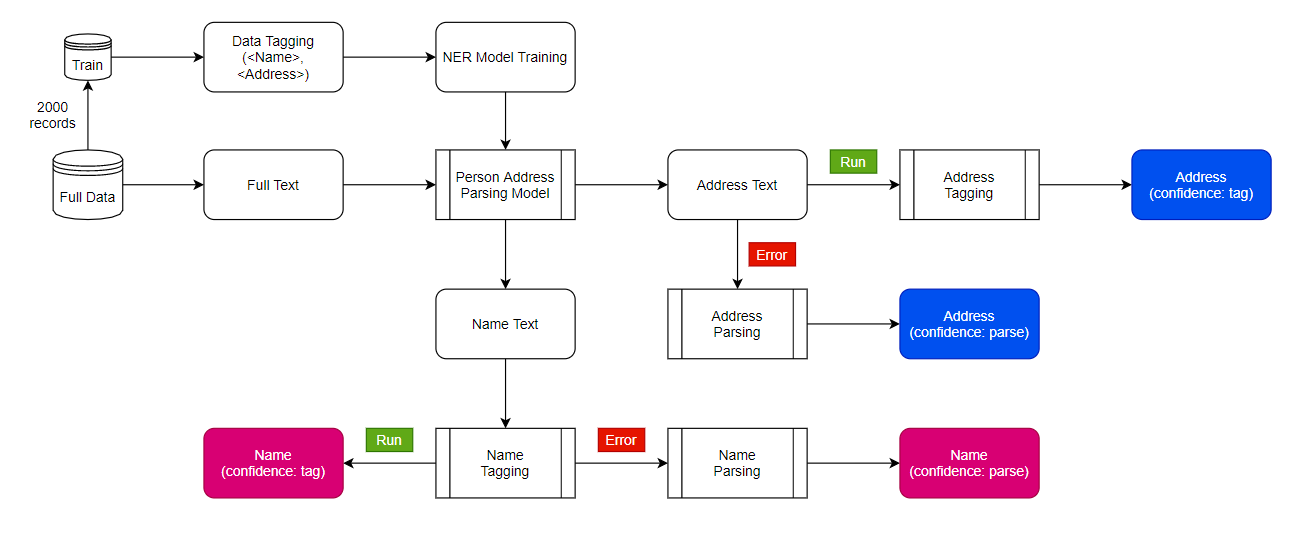
We can select any pre-trained image classification model. These models are commonly known as encoders because their job is to encode an image into a feature vector. I analyzed four encoders named 1) MobileNet, 2) EfficientNet, 3) ResNet and 4) BiT. After basic research, I decided to select BiT model because of its performance and state-of-the-art nature. I selected the BiT-M-50x3 variant of model which is of size 748 MB. More details about this architecture can be found on the official page here.
Vector Similarity System
Images are represented in a fixed-length feature vector format. For the given input vector, we need to find the TopK most similar vectors, keeping the memory efficiency and real-time retrival objective in mind. I explored the most popular techniques and listed down five of them: Annoy, Cosine distance, L1 distance, Locally Sensitive Hashing (LSH) and Image Deep Ranking. I selected Annoy because of its fast and efficient nature. More details about Annoy can be found on the official page here.
Dataset
I listed down 3 datasets from Kaggle that were best fitting the criteria of this use case: 1) Fashion Product Images (Small), 2) Food-11 image dataset and 3) Caltech 256 Image Dataset. I selected Fashion dataset and Foods dataset.
Literature review
- Determining Image similarity with Quasi-Euclidean Metric arxiv
- CatSIM: A Categorical Image Similarity Metric arxiv
- Central Similarity Quantization for Efficient Image and Video Retrieval arxiv
- Improved Deep Hashing with Soft Pairwise Similarity for Multi-label Image Retrieval arxiv
- Model-based Behavioral Cloning with Future Image Similarity Learning arxiv
- Why do These Match? Explaining the Behavior of Image Similarity Models arxiv
- Learning Non-Metric Visual Similarity for Image Retrieval arxiv
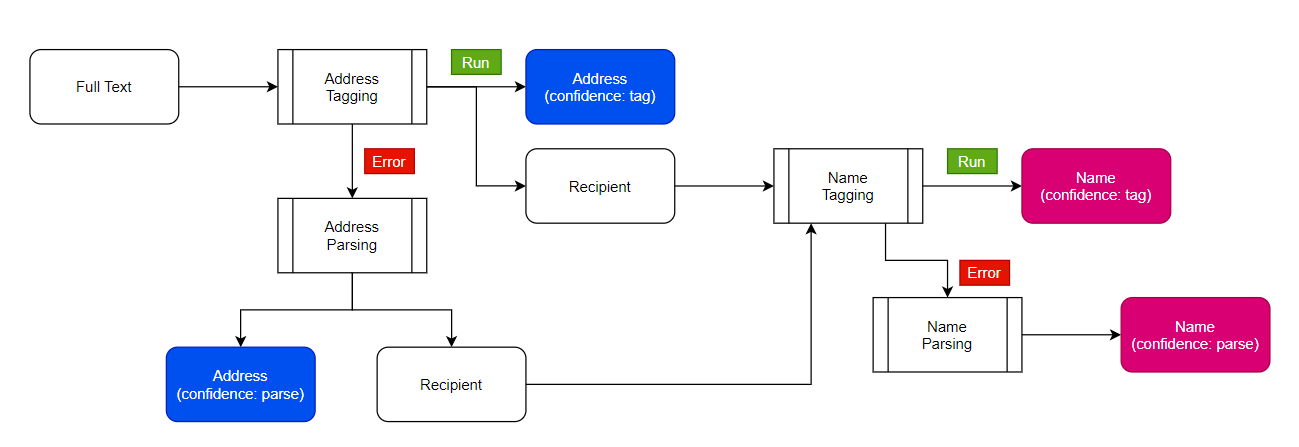
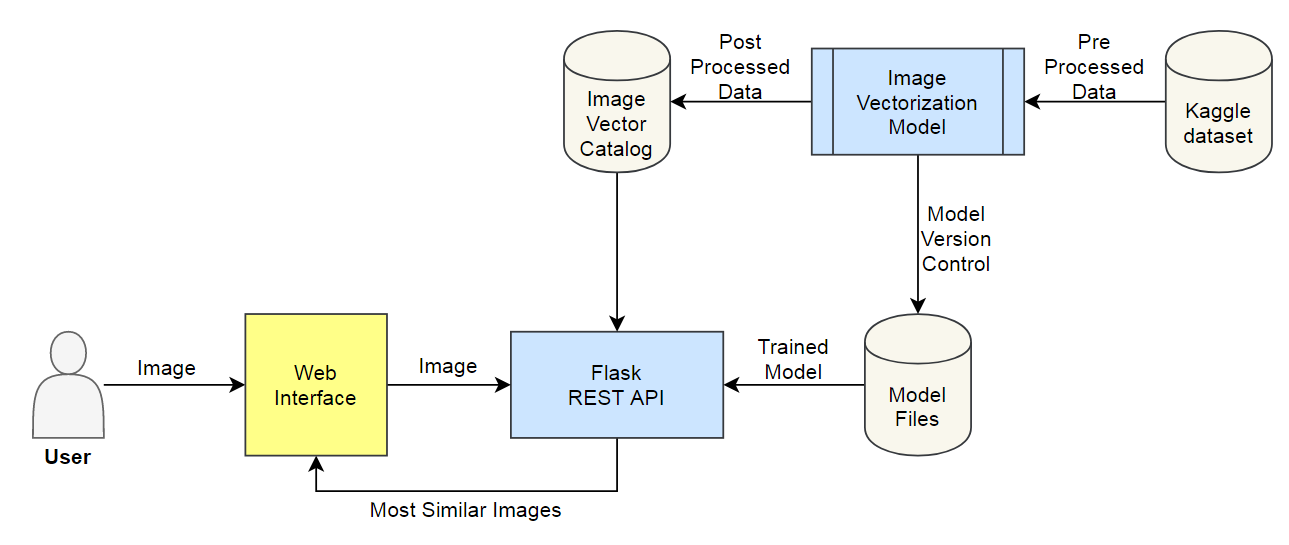
Process Flow
Step 1: Data Acquisition
Download the raw image dataset into a directory. Categorize these images into their respective category directories. Make sure that images are of the same type, JPEG recommended. We will also process the metadata and store it in a serialized file, CSV recommended.
Step 2: Encoder Fine-tuning
Download the pre-trained image model and add two additional layers on top of that: the first layer is a feature vector layer and the second layer is the classification layer. We will only train these 2 layers on our data and after training, we will select the feature vector layer as the output of our fine-tuned encoder. After fine-tuning the model, we will save the feature extractor for later use.
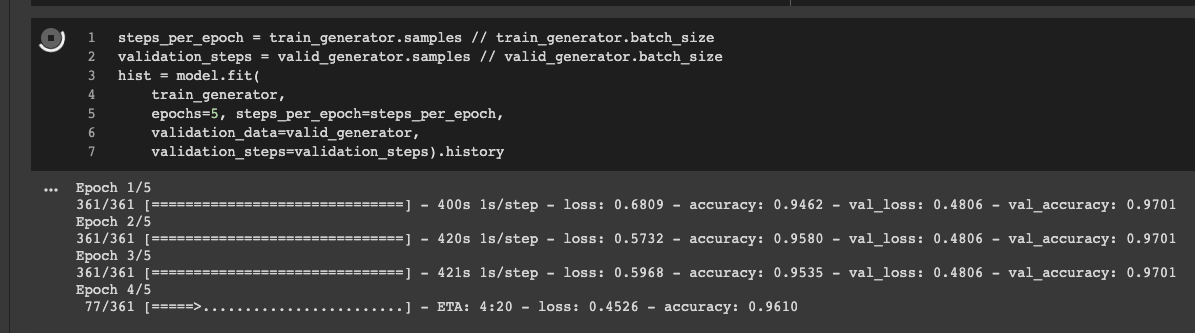
Fig: a screenshot of encoder fine-tuning process
Step 3: Image Vectorization
Now, we will use the encoder (prepared in step 2) to encode the images (prepared in step 1). We will save feature vector of each image as an array in a directory. After processing, we will save these embeddings for later use.
Step 4: Metadata and Indexing
We will assign a unique id to each image and create dictionaries to locate information of this image: 1) Image id to Image name dictionary, 2) Image id to image feature vector dictionary, and 3) (optional) Image id to metadata product id dictionary. We will also create an image id to image feature vector indexing. Then we will save these dictionaries and index object for later use.
Step 5: API Call
We will receive an image from user, encode it with our image encoder, find TopK similar vectors using Indexing object, and retrieve the image (and metadata) using dictionaries. We send these images (and metadata) back to the user.
Deployment
The API was deployed on AWS cloud infrastructure using AWS Elastic Beanstalk service.