Author: Alexsoft
In a hyper-connected world, where advanced analytics and smart devices constantly re-assess and monitor risks, the traditional once-a-year insurance policy looks increasingly irrelevant and static. Insurance will become a breathing and living thing that shrinks and scales with time to accommodate the changing risks in the clients’ daily lives. As technology continues to expand, real-time data from connected devices and predictive analysis from AIs and machine learning will enhance personalized insurance to benefit the client and insurer.
To satisfy the expectations of clients, insurers may need to go beyond the personalization of marketing communication and start personalizing product bundles for individuals.
What is personalized insurance?
Personalized insurance is the process of reaching insurance customers with targeted pricing, offers, and messages at the right time. Personalization spans across various types of insurance services, from health to property insurance.
Some insurers are already defining themselves as trusted advisors aiding people in navigating, anticipating, and eliminating risks rather than just paying the compensation when things go wrong.
For example, these companies use customer data from wearable and smart devices to monitor the user’s lifestyle. If the user’s data indicate the emergence of a serious medical condition, they can send the customer content designed to change their detrimental lifestyle or recommend immediate treatment. When the customer stays fit, healthy and does not carry out risky activities, their insurance cost will be decreased.
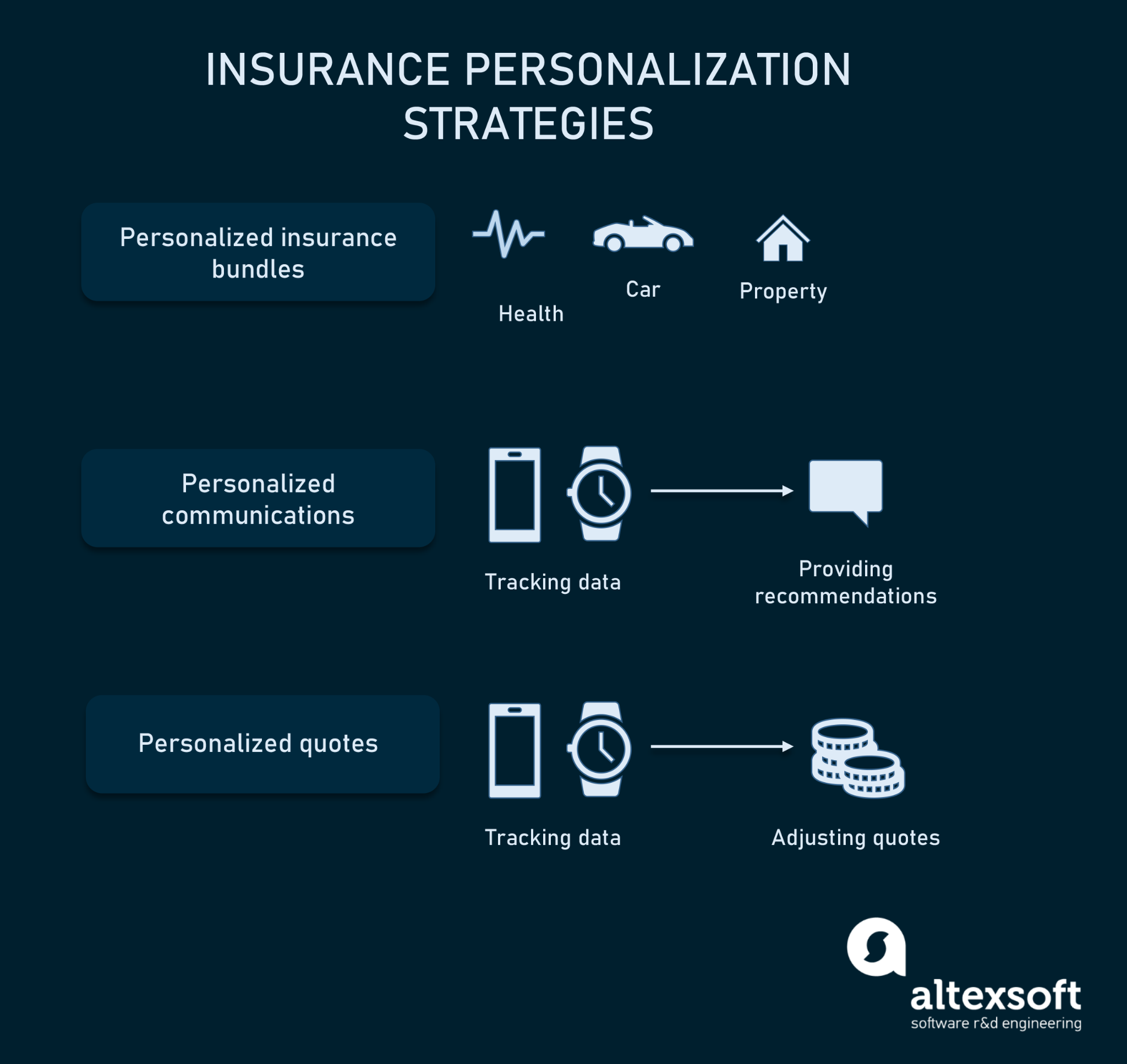
Insurers can provide personalization to customers at different levels:
- Personalized product bundles. The insurer offers a wide range of products such as health, car, life, and property insurance. So, clients can choose the specific products they want and group them in a bundle.
- Personalized communications. Insurers use data collected from smart devices to notify customers about harmful activities and lifestyles. They also send recommendations on lifestyle changes. Some insurers take a step further to provide clients with incentives for a healthy lifestyle.
- Personalized insurance quote. Customers are able to adjust the price of their insurance premiums by turning off the ones they don’t need at any time. Some insurers enable automatic quote adjustments depending on customer’s behavior (e.g., driving habits) or lifestyle choices (e.g., exercising).
Why is it important?
Collecting and analyzing user data is vital in personalizing products based on individual behavior and preferences. In addition, insurers should use this data to enhance external relationships with their customers and guide their internal processes. This will eventually lead to delightful customer experiences and efficient operations.
Personalized insurance is important for many reasons:
Customers expect personalized treatment. Every customer wants to feel special, and the personalization of your services and products will do just that. It will make them stay loyal to you. Moreover, customers are open for personalization. According to the Accenture study, 95 percent of new customers are ready to share their data in exchange for personalized insurance services. And about 58 percent of conservative users would be willing to do so.
Driving more effective sales and increasing revenue. Personalization benefits your sales and income in two ways. First, lots of people are ready to share their data with you in exchange for incentives and reduced premiums. Secondly, having access to clients’ data gives you the ability to target people who are already interested in your product, thereby increasing sales and revenue at a lower cost. You will be able to reach your customers at the right time and with the product they need.
Streamlining operations and working with customers more accurately. Having an insight into customer preferences and behavior is crucial if you want to provide personalized services. Data obtained from social media activity, fitness trackers, GPS, and other tech can help you serve customers better.
Success stories
Lemonade
Use of AI and chatbots to personalize communications.
Lemonade is a US insurance company that uses Maya – an AI-powered bot, to collect and analyze customer data. Maya acts as a virtual assistant that gets information, provides quotes, and handles payments. It also has the ability to provide customized answers to user’s questions and even help them make changes to existing policies. Lemonade uses Natural Action Synthesis and Natural Language Processing to ensure that Maya gets smarter the more it chats. This is possible because their machine learning model is retrained almost daily.
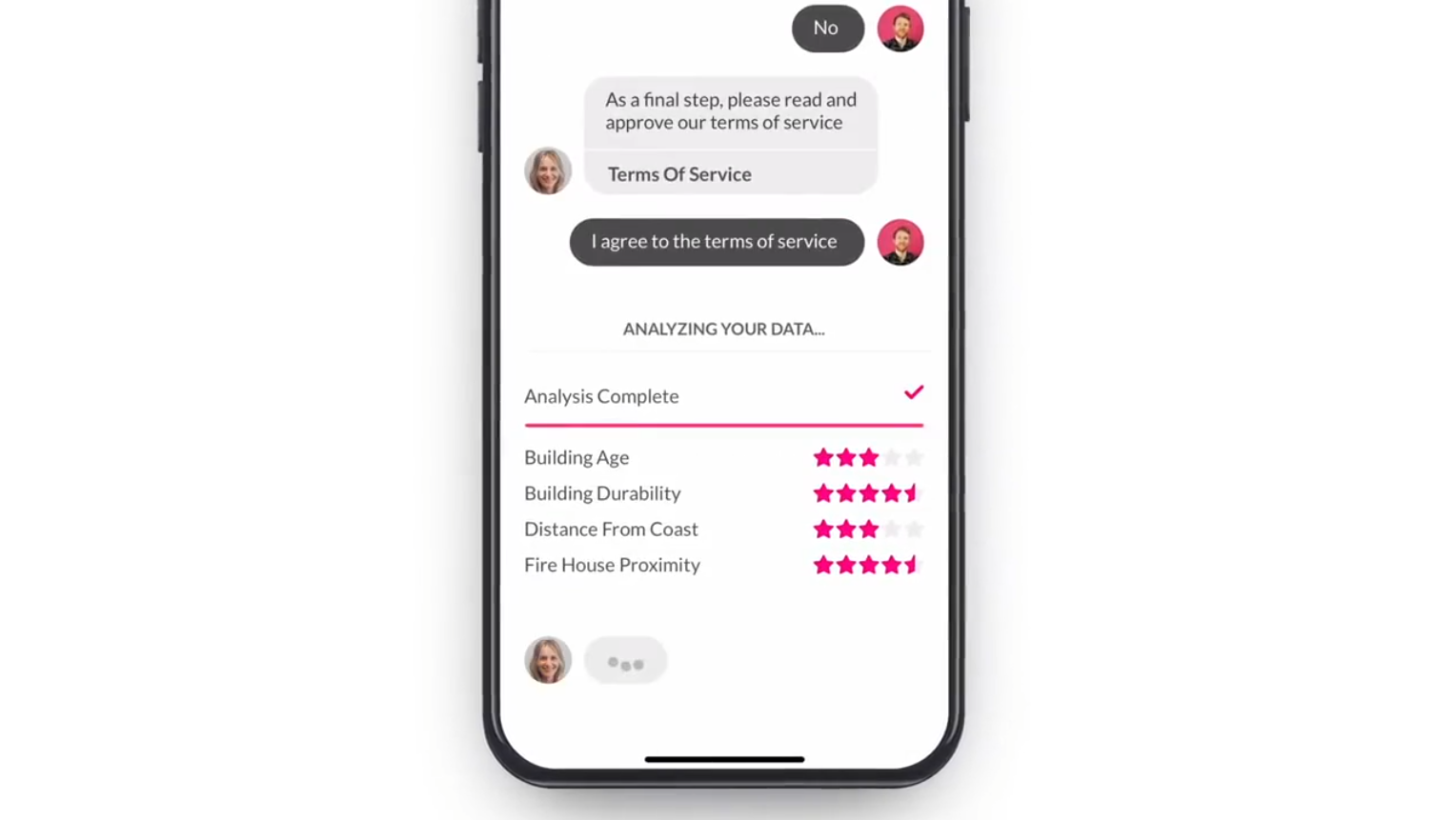
On top of that, the company uses big data analytics to quantify losses and predict risks by placing the client into a risk group and quoting a relevant premium. Customers are grouped according to their risk behaviors. The groups are created using algorithms that collect extensive customer data, such as health conditions.
Cover
Cover is a US-based insurance metasearch company that notifies its clients of price drops for their premiums. Their technology works by scanning the market, looking for discounted and lowered prices of insurance premiums for their clients. Cover blends automation, mobile technology, and expert advice to provide customers with high-quality insurance protection at the best prices.
Cover compares with policy data and prices from over 30 different insurers. From the start, the customers need to provide answers to some questions, which will be used to match the client with a policy that suits their needs.
Oscar
Oscar is a health insurer that provides its clients with a concierge team of medical professionals who give health advice and help them know if they see the best specialist for their specific health condition. They also help with finding the best doctors that accept Oscar insurance and manage and treat chronic conditions. Also, they set aside a separate concierge team in cases of emergencies that helps with the patient’s discharge and follow-up care.
Oscar’s mobile app acts as an intermediary between the user and the health system. The platform facilitates the customer’s interaction with their healthcare professionals. Clients can receive their lab reports, medical records, physician recommendations, and virtual care from the app. Oscar has also improved its high-touch services, including telemedicine and an “Ask your concierge” feature that connects users with a health insurance advice team.
Alllstate
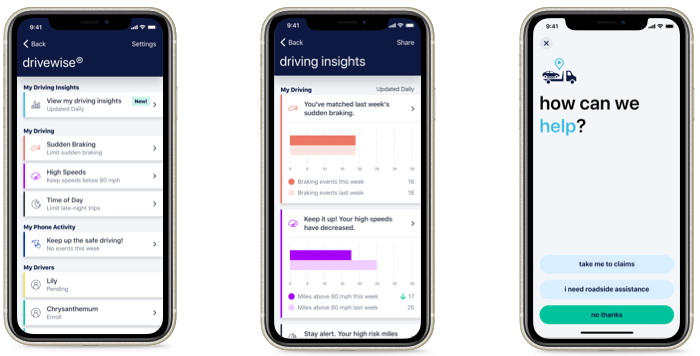
Allstate is an auto insurance company that offers personalized car insurance to its customers using telematics programs called Drivewise and Milewise. Drivewise is offered through a mobile app that monitors the customers driving behavior and provides feedback after each drive. Customers also receive incentives for safe driving. From the app interface, clients can check their rewards and driving behavior for the last 100 trips. The customer’s premium is then calculated based on factors like speeding, abrupt braking, and time of the trip. One of the nice things about Drivewise is that even those who do not have an Allstate care insurance policy can participate in this program. Their Milewise program, as the name suggests, lets customers pay insurance based on the miles covered. So, the app monitors the distance covered by the car, and low-mileage drivers can save on insurance.
How to approach personalization?
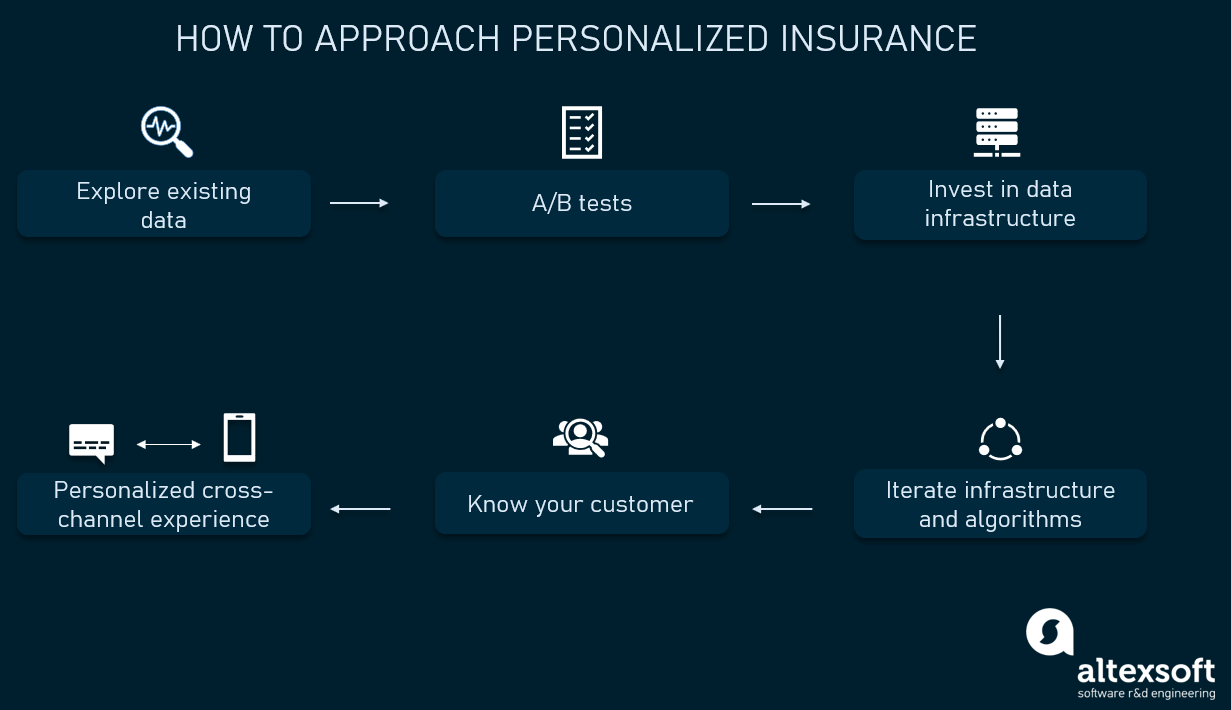
Before fully investing in personalization, you need to carefully plan your approach. This will ensure you have all the pieces for success, and it will help you follow through with your plan.
Explore existing data
Having customer data is the minimum requirement to provide personalized services. First, you need to envision the type of personalization you want to offer. Then, make sure you have data collection channels that provide you with relevant data needed for your tasks. For instance, some of your documents may contain the required information, and you have to digitize, structure those, or extract specific details for that. So, you should audit your current information and data collection mechanisms to estimate whether you’ll need any additional effort to gather this data. For instance, you may want to use intelligent document processing.
Engage data scientists to make the proof of concept and carry out A/B tests
Your vision on personalization may not work for every business model. Or your data quality may be low to reach project feasibility. We’ve talked about that while explaining how to approach ROI calculations with machine learning projects. So, you need to present the data you have to a data science team to run several experiments and build prototypes. Once they are ready, you can roll out your new algorithms for a subset of customers to run A/B tests. Their results may show that the conventional approaches work better for you or help iterate on your assumptions.
Invest in data infrastructure
If the A/B tests show that personalization will work for your business model, that is where automation comes into play. You can start investing in data infrastructure and analytical pipelines to automate data collection and analysis mechanisms.
You’ll need a data engineering team for that. These specialists set up connections with data sources, such as mobile, IoT, and telematics devices, enable automatic data preparation, configure storages, and integrate your infrastructure with business intelligence software that helps explore and visualize data.
Continuously learn your customers’ preferences and needs
The data you collect is only as good as the insights gained from it. That is why it is vital to have a comprehensive analytic solution. A high-quality analytic software will transform the data into your most valuable asset. This data will be used to improve product development, make more accurate decisions, and provide personalized services to your customers.
Iterate on your infrastructure and algorithms
Personalization isn’t a one-time project. Whether you apply machine learning or build personalization based on rule-based systems, you still have to revisit your technology, continuously gather new data, and adapt your workflows.
Ensure a personalized cross-channel experience
Since the data collected from IoT devices and other tech is vital for personalization, it is important to make the customer experience seamless across different communication channels. Therefore, the customer should always be provided with the same level of personalization regardless of the touchpoint.
Challenges
Personalization is financially intensive. The ability of insurers to personalize insurance differs only marginally between marketing communications and products. Most of them, especially startups, do not have the funds to implement advanced technologies like machine learning needed for personalized insurance. However, insurers do not need to start with all the levels of personalization. They can often start by customizing their customer service, gathering data and insights, and then gradually developing towards more complex systems.
Complex process involving multiple parties. Also, it is difficult to balance personalization with financial targets, especially when establishing a price for risk. In-depth personalization of insurance must use data analytics from different sources to ensure that personalized offers reflect the client’s needs as well as the profitability and risks implications for the company.
Customer data is heavily regulated. Customer data from different sources are subject to industry regulations and privacy concerns. It is often a difficult task to obtain approval from regulators to use this data. Also, customers are becoming more aware of how companies are using their data and approve strict regulations. That is why laws such as General Data Protection Regulation (GDPR) and California Consumer Privacy Act (CCPA) have been passed, which gives customers more control over their data. Insurers can address this barrier by explaining to people how their systems work and how personal data is used. Read more on explainable machine learning in our dedicated article. Besides being open, insurers can provide clients with incentives and other services for free in exchange for access to personal data.