
Overview
News recommendation system has a high degree of real-time because there will be a large number of news and hot spots at any time. Incremental updating, online learning, local updating and even reinforcement learning can make the recommender system quickly respond to the user‘s new behavior, and the premise of these updating strategies is that the sample itself has enough real-time information. In news recommendation system, the typical training sample is the user’s click behavior data.
Why is the real-time nature of the recommendation system important?
Intuitively, when users use personalized news applications, users expect to find articles that match their interests faster; when using short video services, they expect to "flash" content that they are interested in faster; when doing online shopping, I also hope to find the products that I like, faster. All recommendations highlight the word "fast", which is an intuitive manifestation of the "real-time" role of the recommendation system.
From a professional point of view, the real-time performance of the recommendation system is also crucial, which is mainly reflected in the following two aspects:
- The faster the update speed of the recommendation system is, the more it can reflect the user's recent user habits, and the more time-sensitive it can make recommendations to the user.
- The faster the recommendation system is updated, the easier it is for the model to find the latest popular data patterns, and the more it can make the model react to find the latest fashion trends.
The real-time nature of the "feature" of the recommendation system
Suppose a user has watched a 10-minute "badminton teaching" video in its entirety. Then there is no doubt that the user is interested in the subject of "badminton". The system hopes to continue to recommend "badminton" related videos when the user turns the page next time. However, due to the lack of real-time features of the system, the user’s viewing history cannot be fed back to the recommendation system in real time. As a result, the recommendation system learned that the user had watched the video "Badminton Teaching". It was already half an hour later. Has left the app. This is an example of recommendation failure caused by poor real-time performance of the recommendation system.
It is true that the next time the user opens the application, the recommendation system can use the last user behavior history to recommend "badminton" related videos, but the recommendation system undoubtedly loses what is most likely to increase user viscosity and increase user retention. opportunity.
The real-time nature of the "model" of the recommender system
No matter how strong the real-time feature is, the scope of influence is limited to the current user. Compared with the real-time nature of "features", the real-time nature of the recommendation system model is often considered from a more global perspective . The real-time nature of the feature attempts to describe a person with more accurate features, so that the recommendation system can give a recommendation result that is more in line with the person. The real-time nature of the model hopes to capture new data patterns at the global level faster and discover new trends and relevance.
Take, for example, a large number of promotional activities on Double Eleven on an e-commerce website. The real-time nature of the feature will quickly discover the products that the user may be interested in based on the user's recent behavior, but will never find the latest preferences of similar users, the latest correlation information between the products, and the trend information of new activities.
To discover such global data changes, the model needs to be updated faster. The most important factor affecting the real-time performance of the model is the training method of the model.
- Full update - The most common way of model training is full update. The model will use all training samples in a certain period of time for retraining, and then replace the "outdated" model with the new trained model. However, the full update requires a large amount of training samples, so the training time required is longer; and the full update is often performed on offline big data platforms, such as spark+tensorflow, so the data delay is also longer, which leads to the full update It is the worst "real-time" model update method. In fact, for a model that has been trained, it is enough to learn only the newly added incremental samples, which is called incremental update.
- Incremental update (Incremental Learning) - Incremental update only feeds newly added samples to the model for incremental learning . Technically, deep learning models often use stochastic gradient descent (SGD) and its variants for learning. The model's learning of incremental samples is equivalent to continuing to input incremental samples for gradient descent on the basis of the original samples. Therefore, based on the deep learning model, it is not difficult to change from full update to incremental update. But everything in engineering is a tradeoff, there is never a perfect solution, and incremental updates are no exception. Since only incremental samples are used for learning, the model also converges to the best point of the new sample after multiple epochs, and it is difficult to converge to the global best point of all the original samples + incremental samples. Therefore, in the actual recommendation system, the incremental update and the global update are often combined . After several rounds of incremental update, the global update is performed in a time window with a small business volume, and the model is corrected after the incremental update process. Accumulated errors in. Make trade-offs and trade-offs between "real-time performance" and "global optimization".
- Online learning - "Online learning" is a further improvement of "incremental update", "incremental update" is to perform incremental update when a batch of new samples is obtained, and online learning is to update the model in real time every time a new sample is obtained. Online learning can also be implemented technically through SGD. But if you use the general SGD method, online learning will cause a very serious problem, that is, the sparsity of the model is very poor, opening too many "fragmented" unimportant features. We pay attention to the "sparseness" of the model in a sense that is also an engineering consideration. For example, in a model with an input vector of several million dimensions, if the sparsity of the model is good, the effect of the model can be maintained without affecting the model. , Only make the corresponding weight of the input vector of a very small part of the dimension non-zero, that is to say, when the model is online, the volume of the model is very small, which is undoubtedly beneficial to the entire model serving process. Both the memory space required to store the model and the speed of online inference will benefit from the sparsity of the model. If the SGD method is used to update the model, it is easier to generate a large number of features with small weights than the batch method, which increases the difficulty of model deployment and update. So in order to take into account the training effect and model sparsity in the online learning process, there are a lot of related researches. The most famous ones include Microsoft's RDA, Google's FOBOS and the most famous FTRL, etc.
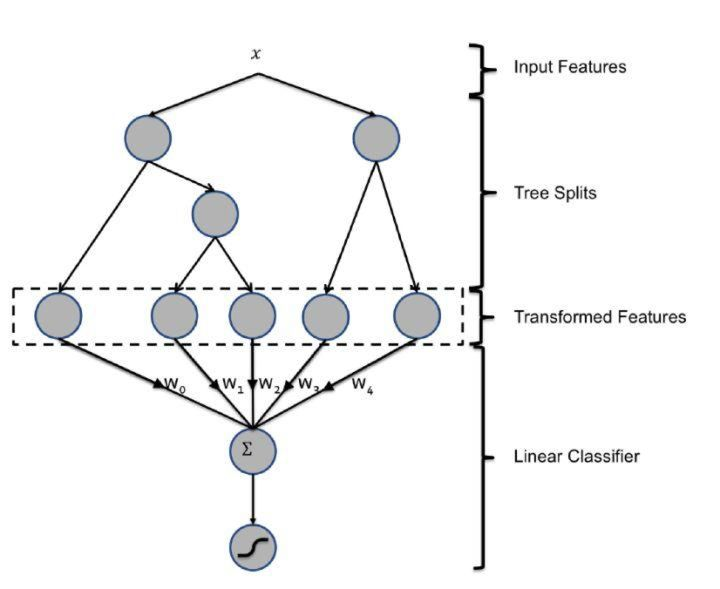
- Partial model update - Another improvement direction to improve the real-time performance of the model is to perform a partial update of the model. The general idea is to reduce the update frequency of the part with low training efficiency and increase the update frequency of the part with high training efficiency . This approach is representative of the GBDT+LR model of Facebook.
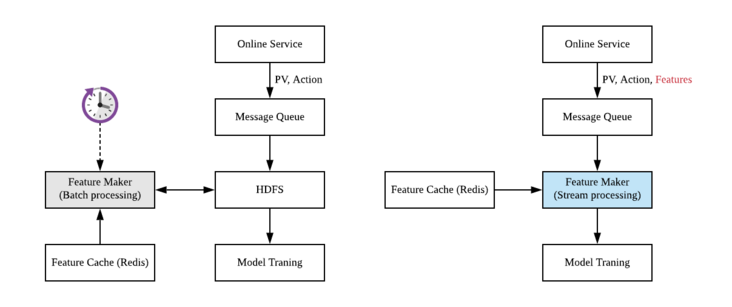
Data pipeline of a typical news recommendation system
When a user is exposed with a list of news articles, a page view events are sent to the backend server and when that user clicks on the news of interest, the action events are also sent to the backend server. After receiving these 2 event streams (page view and clicks), the backend server will send these user behaviour events to the message queue. And message queue finally stores these messages into the distributed file system, such as HDFS.
For model training, we need a training sample. The most common sampling technique is negative sampling. In this, we generate 'n' negative samples for each positive event that we receive. Users will only generate behavior for some exposed news samples, which are positive samples, and the remaining exposure samples without behavior are negative samples. After generating positive and negative samples, the model can be trained.
The recommendation system with low real-time requirements can use batch processing technology (APACHE spark is a typical tool) to generate samples, as shown in the left figure. Set a timing task, and read the user behavior log and exposure log in the time window from HDFS every other period of time, such as one hour, to perform join operation, generate training samples, and then write the training samples back to HDFS, Then start the training update of the model.
Problems
One obvious problem with batch processing is latency. The typical cycle of running batch tasks regularly is one hour, which means that there is a delay of at least one hour from sample generation to model training. Sometimes, if the batch platform is overloaded and the tasks need to be queued, the delay will be greater.
Another problem is the boundary problem. If page view (PV) data is generated at the end of the log time window selected by the batch task, the corresponding action data may fall into the next time window of the batch task, resulting in join failure and false negative samples.
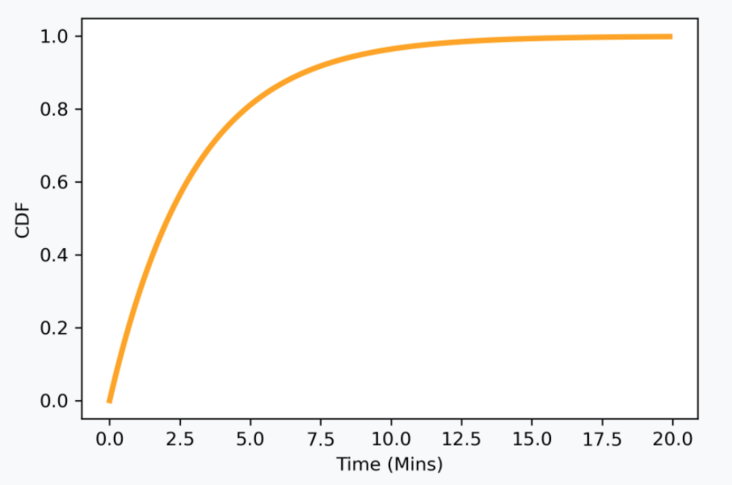
A related problem to this is the time synchronization problem. When a news item is exposed to the user, the user may click immediately after the PV data stream is generated, or the user may act after a few minutes, more than ten minutes, or even several hours. This means that after the PV data stream arrives, it needs to wait for a period of time to join with the action data stream. If the waiting time is too long, some samples (positive samples) that should have user behavior will be wrongly marked as negative samples because the user behavior has no time to return. Too long waiting time will damage and increase the system delay. Offline analysis of the delay distribution between the actual action data stream and PV data stream is a very typical exponential distribution.
Apache Flink to the rescue
How Apache Flink solves the latency problem?
In order to enhance the real-time performance, we use Apache Flink framework to rewrite the sample generation logic with stream processing technology. As shown in the right figure above, after the user exposure and behavior logs generated by online services are written into the message queue, instead of waiting for them to drop to HDFS, we directly consume these message flows with Flink. At the same time, Flink reads the necessary feature information from the redis cache and generates the sample message stream directly. The sample message flow is written back to the Kafka queue, and downstream tensorflow can directly consume the message flow for model training.
How Apache Flink solved the boundary and synchronization problem?
As per the exponential distribution (analyzed on a private dataset of a news recommender app), most of the user behavior has reflow within a few minutes. And if few minutes is an acceptable delay, a simple solution is to set a time window with a compromise size. Flink provides window join to implement this logic.