
Classical recommender systems typically provides familier items, which not only bores customer after some time, but create a critical bias problem also, generally known as filter bubble or echo chamber problem.
To address this issue, instead of recommending best matching product all the time, we intentionally recommend a random product. For example, if a user subscribed to Netflix one month ago and watching action movies all the time. If we recommend another action movie, there is a high probability that user will click but keeping in mind the long-term user satisfaction and to address the filter bubble bias, we would recommend a comedy movie. Surprisingly, this strategy works!!
The most common metric is diversity factor but diversity only measures dispersion among recommended items. The better alternative is unexpectedness factor. It measures deviations of recommended items from user expectations and thus captures the concept of user surprise and allows recommender systems to break from the filter bubble. The goal is to provide novel, surprising and satisfying recommendations.
Including session-based information into the design of an unexpected recommender system is beneficial. For example, it is more reasonable to recommend the next episode of a TV series to the user who has just finished the first episode, instead of recommending new types of videos to that person. On the other hand, if the user has been binge-watching the same TV series in one night, it is better to recommend something different to him or her.
Model
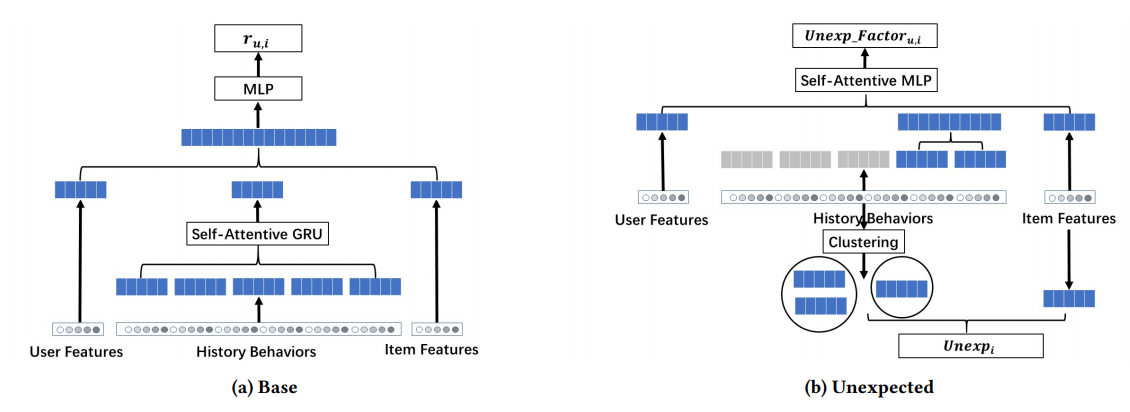
Overview of the proposed PURS model. The base model estimates the click-through rate of certain user-item pairs, while the unexpected model captures the unexpectedness of the new recommendation as well as user perception towards unexpectedness.
Offline Experiment Results
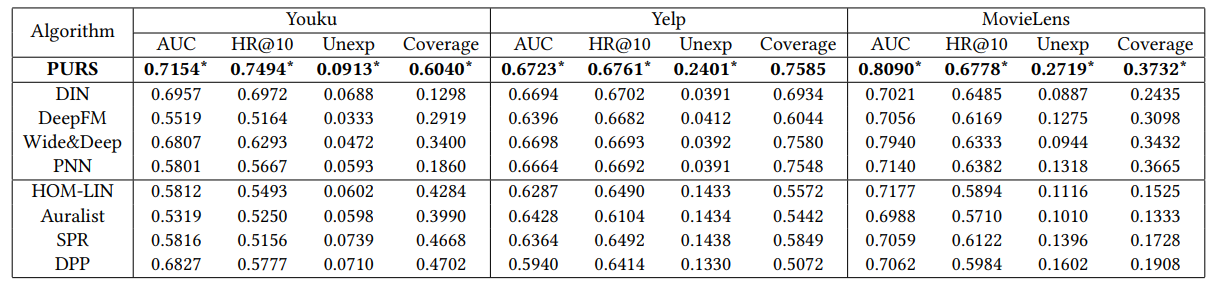
Online A/B Test Results
Authors conducted the online A/B test at Alibaba-Youku, a major video recommendation platform from 2019-11 to 2019-12. During the testing period, they compared the proposed PURS model with the latest production model in the company. They measured the performance using standard business metrics: VV (Video View, average video viewed by each user), TS (Time Spent, average time that each user spends on the platform), ID (Impression Depth, average impression through one session) and CTR (Click-Through-Rate, the percentage of user clicking on the recommended video). They also measure the novelty of the recommended videos using the unexpectedness and coverage measures.

Represents statistical significance at the 0.95 level.
Code Walkthrough
Note: PURS is implemented in Tensorflow 1.x
Unexpected attention (model.py)
def unexp_attention(self, querys, keys, keys_id):
"""
Same Attention as in the DIN model
queries: [Batchsize, 1, embedding_size]
keys: [Batchsize, max_seq_len, embedding_size] max_seq_len is the number of keys(e.g. number of clicked creativeid for each sample)
keys_id: [Batchsize, max_seq_len]
"""
querys = tf.expand_dims(querys, 1)
keys_length = tf.shape(keys)[1] # padded_dim
embedding_size = querys.get_shape().as_list()[-1]
keys = tf.reshape(keys, shape=[-1, keys_length, embedding_size])
querys = tf.reshape(tf.tile(querys, [1, keys_length, 1]), shape=[-1, keys_length, embedding_size])
net = tf.concat([keys, keys - querys, querys, keys*querys], axis=-1)
for units in [32,16]:
net = tf.layers.dense(net, units=units, activation=tf.nn.relu)
att_wgt = tf.layers.dense(net, units=1, activation=tf.sigmoid) # shape(batch_size, max_seq_len, 1)
outputs = tf.reshape(att_wgt, shape=[-1, 1, keys_length], name="weight") #shape(batch_size, 1, max_seq_len)
scores = outputs
scores = scores / (embedding_size ** 0.5) # scale
scores = tf.nn.softmax(scores)
outputs = tf.matmul(scores, keys) #(batch_size, 1, embedding_size)
outputs = tf.reduce_sum(outputs, 1, name="unexp_embedding") #(batch_size, embedding_size)
return outputs
Unexpected metric calculation (train.py)
def unexpectedness(sess, model, test_set):
unexp_list = []
for _, uij in DataInput(test_set, batch_size):
score, label, user, item, unexp = model.test(sess, uij)
for index in range(len(score)):
unexp_list.append(unexp[index])
return np.mean(unexp_list)