Video Action Recognition
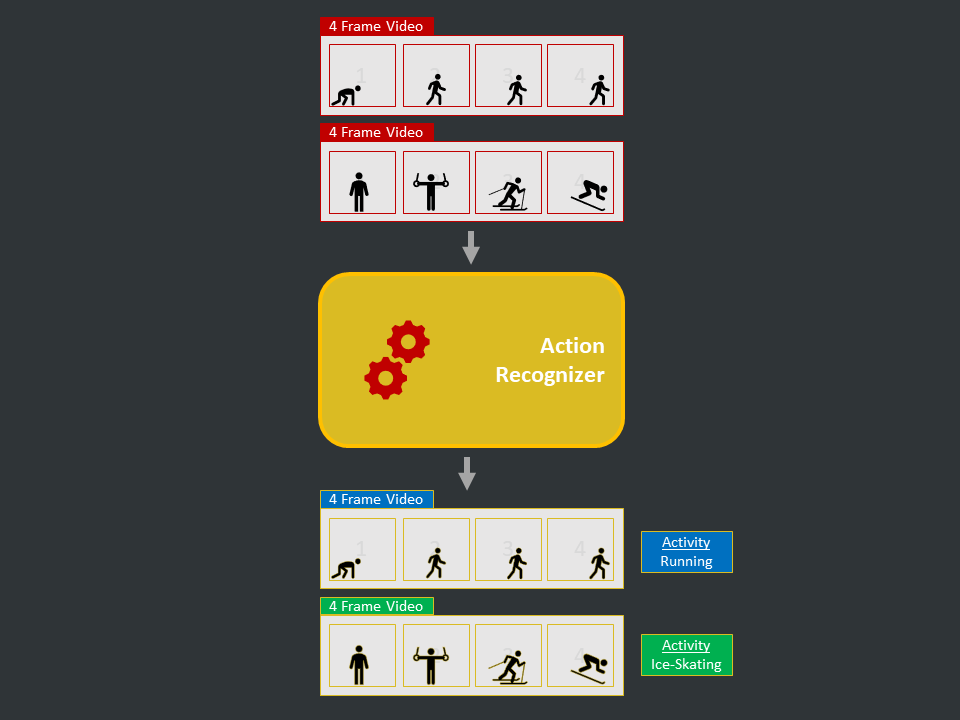
Introduction
- Definition: This is the task of identifying human activities/actions (e.g. eating, playing) in videos. In other words, this task classifies segments of videos into a set of pre-defined categories.
- Applications: Automated surveillance, elderly behavior monitoring, human-computer interaction, content-based video retrieval, and video summarization.
- Scope: Human Action only
- Tools: OpenCV
Models
3D-ResNet
Can Spatiotemporal 3D CNNs Retrace the History of 2D CNNs and ImageNet?
the authors explore how existing state-of-the-art 2D architectures (such as ResNet, ResNeXt, DenseNet, etc.) can be extended to video classification via 3D kernels.
R(2+1)D
This model was pre-trained on 65 million social media videos and fine-tuned on Kinetics400.
Process flow
Step 1: Collect videos
Capture via camera, scrap from the internet or use public datasets
Step 2: Create Labels
Use open-source tools like VGA Video Annotator for video annotation
Step 3: Data Acquisition
Setup the database connection and fetch the data into python environment
Step 4: Data Exploration
Explore the data, validate it and create preprocessing strategy
Step 5: Data Preparation
Clean the data and make it ready for modeling
Step 6: Model Building
Create the model architecture in python and perform a sanity check
Step 7: Model Training
Start the training process and track the progress and experiments
Step 8: Model Validation
Validate the final set of models and select/assemble the final model
Step 9: UAT Testing
Wrap the model inference engine in API for client testing
Step 10: Deployment
Deploy the model on cloud or edge as per the requirement
Step 11: Documentation
Prepare the documentation and transfer all assets to the client
Use Cases
Kinetics 3D CNN Human Activity Recognition
This dataset consists of 400 human activity recognition classes, at least 400 video clips per class (downloaded via YouTube) and a total of 300,000 videos. Check out this notion.
Action Recognition using R(2+1)D Model
VGA Annotator was used for creating the video annotation for training. Check out this notion.