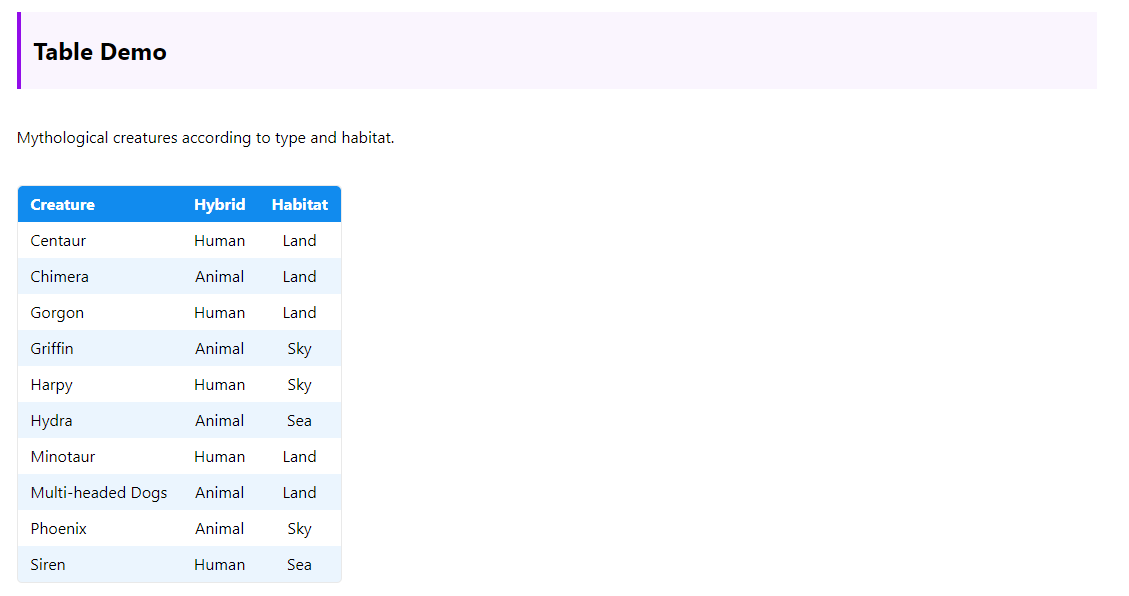
- Handling single request & response by extracting a city’s weather from a weather site using Scrapy
- Handling multiple request & response by extracting book details from a dummy online book store using Scrapy
- Scrape the cover images of all the books from the website books.toscrape.com using Scrapy
- Logging into Facebook using Selenium
- Extract PM2.5 data from openaq.org using Selenium
- Extract PM2.5 data from openaq.org using Selenium Scrapy
Scrapy vs. Selenium
Selenium is an automation tool for testing web applications. It uses a webdriver as an interface to control webpages through programming languages. So, this gives Selenium the capability to handle dynamic webpages effectively. Selenium is capable of extracting data on its own. It is true, but it has its caveats. Selenium cannot handle large data, but Scrapy can handle large data with ease. Also, Selenium is much slower when compared to Scrapy. So, the smart choice would be to use Selenium with Scrapy to scrape dynamic webpages containing large data, consuming less time. Combining Selenium with Scrapy is a simpler process. All that needs to be done is let Selenium render the webpage and once it is done, pass the webpage’s source to create a Scrapy Selector object. And from here on, Scrapy can crawl the page with ease and effectively extract a large amount of data.
# SKELETON FOR COMBINING SELENIUM WITH SCRAPY
from scrapy import Selector
# Other Selenium and Scrapy imports
...
driver = webdriver.Chrome()
# Selenium tasks and actions to render the webpage with required content
selenium_response_text = driver.page_source
new_selector = Selector(text=selenium_response_text)
# Scrapy tasks to extract data from Selector
Project tree
.
├── airQuality
│ ├── countries_list.json
│ ├── get_countries.py
│ ├── get_pm_data.py
│ ├── get_urls.py
│ ├── openaq_data.json
│ ├── openaq_scraper.py
│ ├── README.md
│ └── urls.json
├── airQualityScrapy
│ ├── LICENSE
│ ├── openaq
│ │ ├── countries_list.json
│ │ ├── openaq
│ │ │ ├── __init__.py
│ │ │ ├── items.py
│ │ │ ├── middlewares.py
│ │ │ ├── pipelines.py
│ │ │ ├── settings.py
│ │ │ └── spiders
│ │ ├── output.json
│ │ ├── README.md
│ │ ├── scrapy.cfg
│ │ └── urls.json
│ ├── performance_comparison
│ │ ├── performance_comparison
│ │ │ ├── __init__.py
│ │ │ ├── items.py
│ │ │ ├── middlewares.py
│ │ │ ├── pipelines.py
│ │ │ ├── settings.py
│ │ │ └── spiders
│ │ ├── README.md
│ │ ├── scrapy.cfg
│ │ ├── scrapy_output.json
│ │ └── selenium_scraper
│ │ ├── bts_scraper.py
│ │ ├── selenium_output.json
│ │ └── urls.json
│ └── README.md
├── books
│ ├── books
│ │ ├── __init__.py
│ │ ├── items.py
│ │ ├── middlewares.py
│ │ ├── pipelines.py
│ │ ├── settings.py
│ │ └── spiders
│ │ ├── book_spider.py
│ │ ├── crawl_spider.py
│ │ └── __init__.py
│ ├── crawl_spider_output.json
│ ├── README.md
│ └── scrapy.cfg
├── booksCoverImage
│ ├── booksCoverImage
│ │ ├── __init__.py
│ │ ├── items.py
│ │ ├── middlewares.py
│ │ ├── pipelines.py
│ │ ├── settings.py
│ │ └── spiders
│ │ ├── image_crawl_spider.py
│ │ └── __init__.py
│ ├── output.json
│ ├── path
│ │ └── to
│ │ └── store
│ ├── README.md
│ └── scrapy.cfg
├── etc
│ └── Selenium
│ ├── chromedriver.exe
│ ├── chromedriver_v87.exe
│ └── install.sh
├── facebook
│ └── login.py
├── gazpacho1
│ ├── data
│ │ ├── media.html
│ │ ├── ocr.html
│ │ ├── page.html
│ │ ├── static
│ │ │ └── stheno.mp4
│ │ └── table.html
│ ├── media
│ │ ├── euryale.png
│ │ ├── medusa.mp3
│ │ ├── medusa.png
│ │ ├── stheno.mp4
│ │ └── test.png
│ ├── scrap_login.py
│ ├── scrap_media.py
│ ├── scrap_ocr.py
│ ├── scrap_page.py
│ └── scrap_table.py
├── houzzdotcom
│ ├── houzzdotcom
│ │ ├── __init__.py
│ │ ├── items.py
│ │ ├── middlewares.py
│ │ ├── pipelines.py
│ │ ├── settings.py
│ │ └── spiders
│ │ ├── crawl_spider.py
│ │ └── __init__.py
│ └── scrapy.cfg
├── media
│ └── test.png
├── README.md
├── scrapyPractice
│ ├── scrapy.cfg
│ └── scrapyPractice
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ └── __init__.py
└── weather
├── output.json
├── README.md
├── scrapy.cfg
└── weather
├── __init__.py
├── items.py
├── middlewares.py
├── pipelines.py
├── settings.py
└── spiders
├── __init__.py
└── weather_spider.py
35 directories, 98 files
For code, drop me a message on mail or LinkedIn.