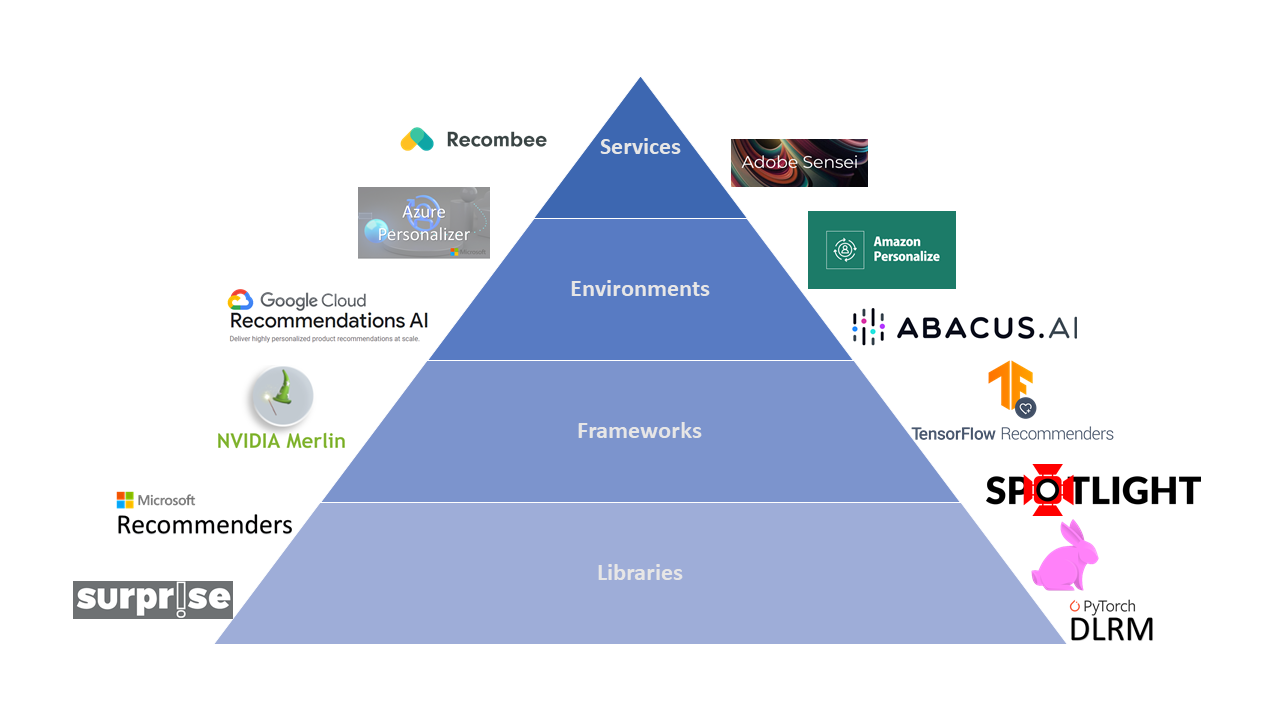
Recombee - Recommendation as a service API
Recombee is a Recommender as a Service with easy integration and Admin UI. It can be used in many domains, for example in media (VoD, news …), e-commerce, job boards, aggregators or classifieds. Basically, it can be used in any domain with a catalog of items that can be interacted by users. The users can interact with the items in many ways: for example view them, rate them, bookmark them, purchase them, etc. Both items and users can have various properties (metadata) that are also used by the recommendation models.
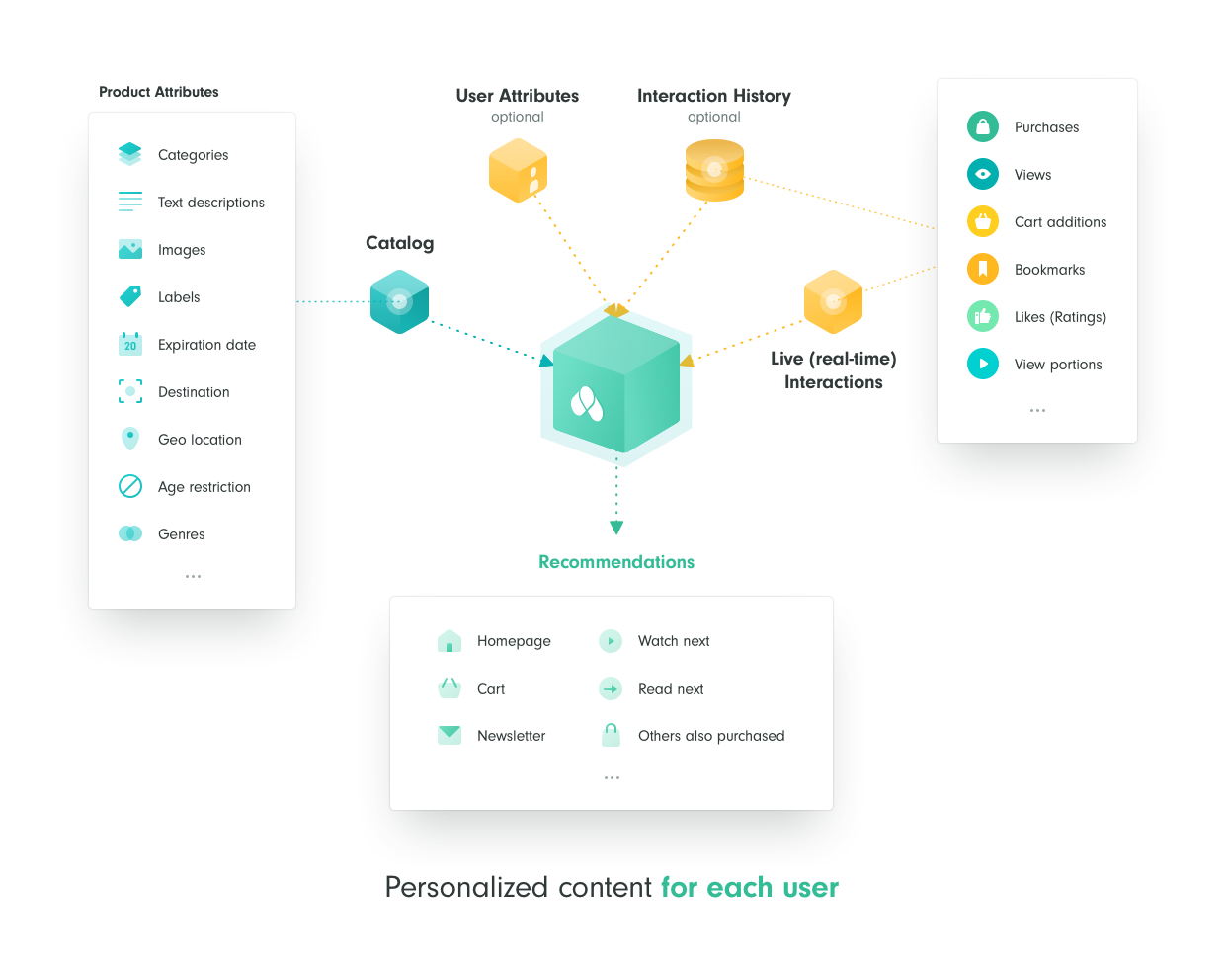
Here is the official tutorial series to get started.
Amazon Personalize is a fully managed machine learning service that goes beyond rigid static rule based recommendation systems and trains, tunes, and deploys custom ML models to deliver highly customized recommendations to customers across industries such as retail and media and entertainment.
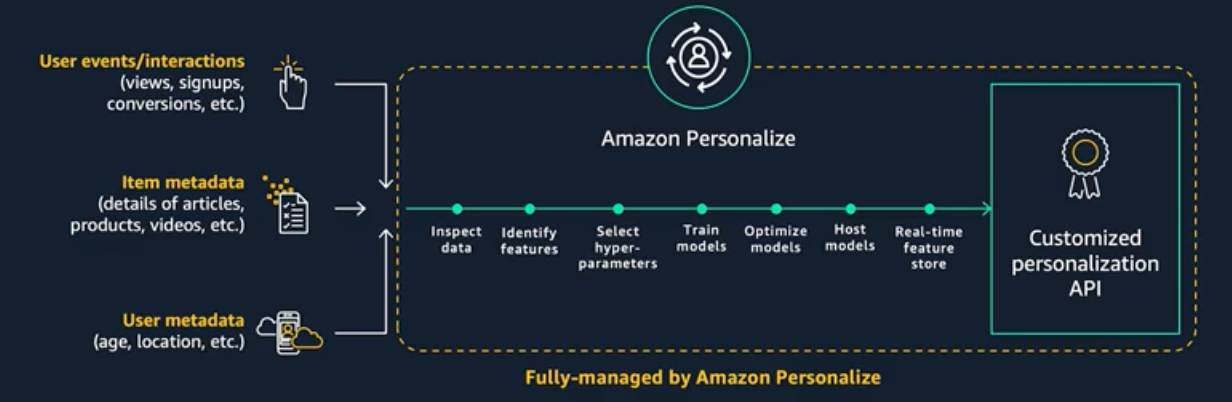
It covers 6 use-cases:

Popular Use-cases
Following are the hands-on tutorials:
- Data Science on AWS Workshop - Personalize Recommendationsp
- https://aws.amazon.com/blogs/machine-learning/creating-a-recommendation-engine-using-amazon-personalize/
- https://aws.amazon.com/blogs/machine-learning/omnichannel-personalization-with-amazon-personalize/
- https://aws.amazon.com/blogs/machine-learning/using-a-b-testing-to-measure-the-efficacy-of-recommendations-generated-by-amazon-personalize/
Also checkout these resources:
- https://www.youtube.com/playlist?list=PLN7ADELDRRhiQB9QkFiZolioeJZb3wqPE
Azure Personalizer - An API based service with Reinforcement learning capability
Azure Personalizer is a cloud-based API service that helps developers create rich, personalized experiences for each user of your app. It learns from customer's real-time behavior, and uses reinforcement learning to select the best item (action) based on collective behavior and reward scores across all users. Actions are the content items, such as news articles, specific movies, or products. It takes a list of items (e.g. list of drop-down choices) and their context (e.g. Report Name, User Name, Time Zone) as input and returns the ranked list of items for the given context. While doing that, it also allows feedback submission regarding the relevance and efficiency of the ranking results returned by the service. The feedback (reward score) can be automatically calculated and submitted to the service based on the given personalization use case.
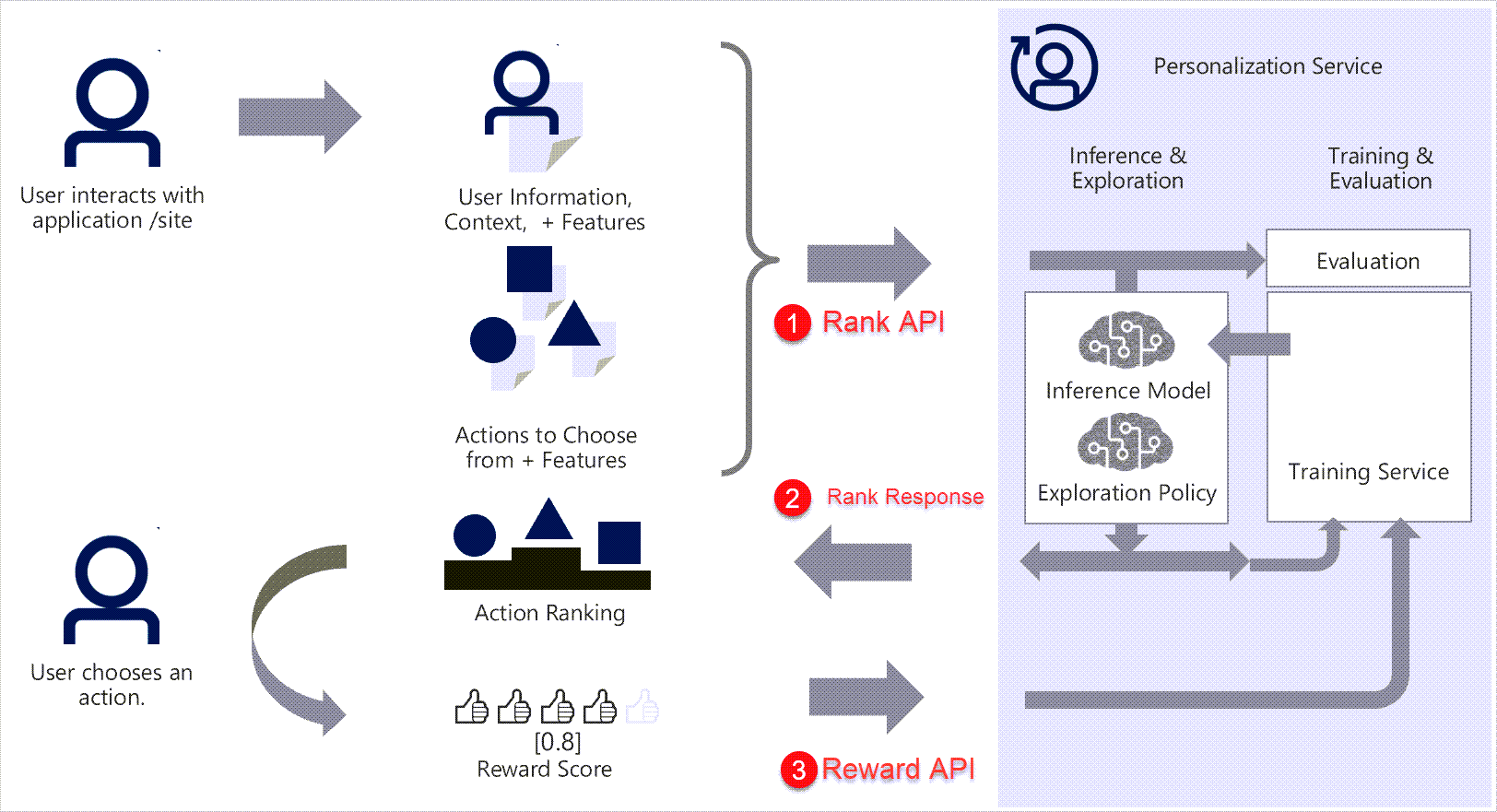
You can use the Personalizer service to determine what product to suggest to shoppers or to figure out the optimal position for an advertisement. After the content is shown to the user, your application monitors the user's reaction and reports a reward score back to the Personalizer service. This ensures continuous improvement of the machine learning model, and Personalizer's ability to select the best content item based on the contextual information it receives.
Following are some of the interesting use cases of Azure Personalizer:
- Blog Recommender [Video tutorial, GitHub]
- Food Personalizer [Video tutorial, Slideshare, Code Blog]
- Coffee Personalizer [GitHub, Video tutorial]
- News Recommendation
- Movie Recommendation
- Product Recommendation
- Intent clarification & disambiguation: help your users have a better experience when their intent is not clear by providing an option that is personalized.
- Default suggestions for menus & options: have the bot suggest the most likely item in a personalized way as a first step, instead of presenting an impersonal menu or list of alternatives.
- Bot traits & tone: for bots that can vary tone, verbosity, and writing style, consider varying these traits.
- Notification & alert content: decide what text to use for alerts in order to engage users more.
- Notification & alert timing: have personalized learning of when to send notifications to users to engage them more.
- Dropdown Options - Different users of an application with manager privileges would see a list of reports that they can run. Before Personalizer was implemented, the list of dozens of reports was displayed in alphabetical order, requiring most of the managers to scroll through the lengthy list to find the report they needed. This created a poor user experience for daily users of the reporting system, making for a good use case for Personalizer. The tooling learned from the user behavior and began to rank frequently run reports on the top of the dropdown list. Frequently run reports would be different for different users, and would change over time for each manager as they get assigned to different projects. This is exactly the situation where Personalizer’s reward score-based learning models come into play.
- Projects in Timesheet - Every employee in the company logs a daily timesheet listing all of the projects the user is assigned to. It also lists other projects, such as overhead. Depending upon the employee project allocations, his or her timesheet table could have few to a couple of dozen active projects listed. Even though the employee is assigned to several projects, particularly at lead and manager levels, they don’t log time in more than 2 to 3 projects for a few weeks to months.
- Reward Score Calculation
Google Recommendation - Recommender Service from Google

It uses multi-objective, real-time recommendations models and provides 4 use-cases for fasttrack train-&-deploy process - Personalized recommendations, personalized search, related items and real-time feed recommendations.
Here is the hands-on video tutorial:
https://youtu.be/7hTKL73f2yA
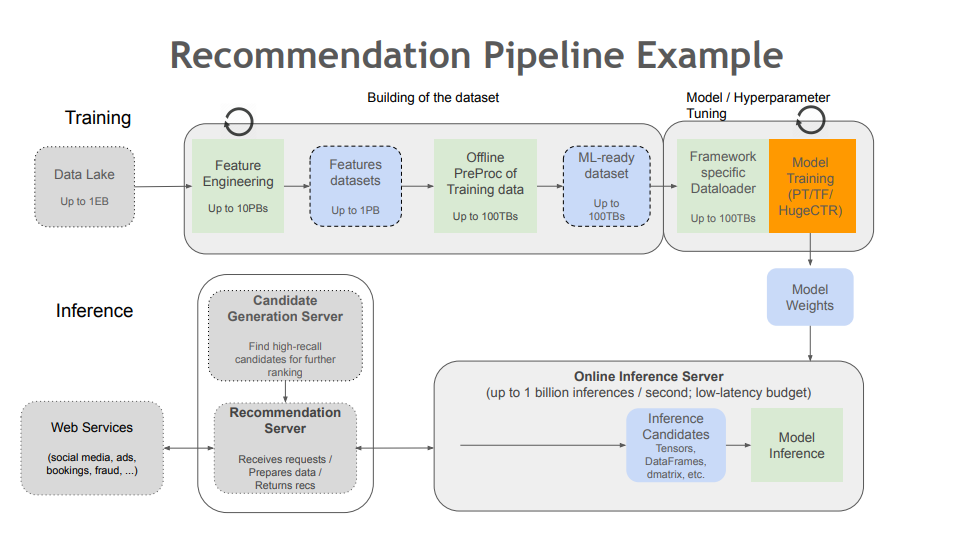
Merlin empowers data scientists, machine learning engineers, and researchers to build high-performing recommenders at scale. Merlin includes tools that democratize building deep learning recommenders by addressing common ETL, training, and inference challenges. Each stage of the Merlin pipeline is optimized to support hundreds of terabytes of data, all accessible through easy-to-use APIs. With Merlin, better predictions than traditional methods and increased click-through rates are within reach.
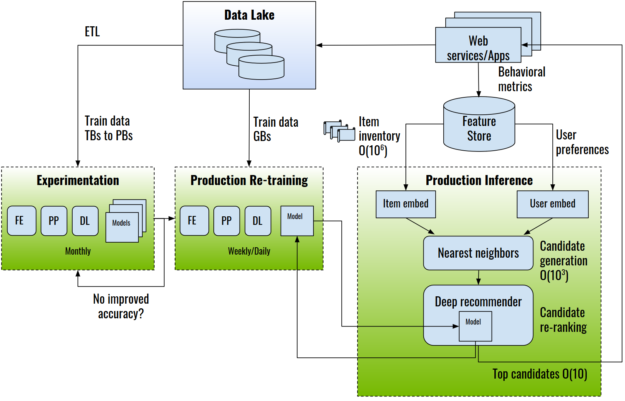
End-to-end recommender system architecture. FE: feature engineering; PP: preprocessing; ETL: extract-transform-load.
TFRS - Open-source Recommender library built on top of Tensorflow
Built with TensorFlow 2.x, TFRS makes it possible to:

Following is a series of official tutorial notebooks:-
TensorFlow Recommenders: Quickstart
Elliot - An end-to-end framework good for recommender system experiments
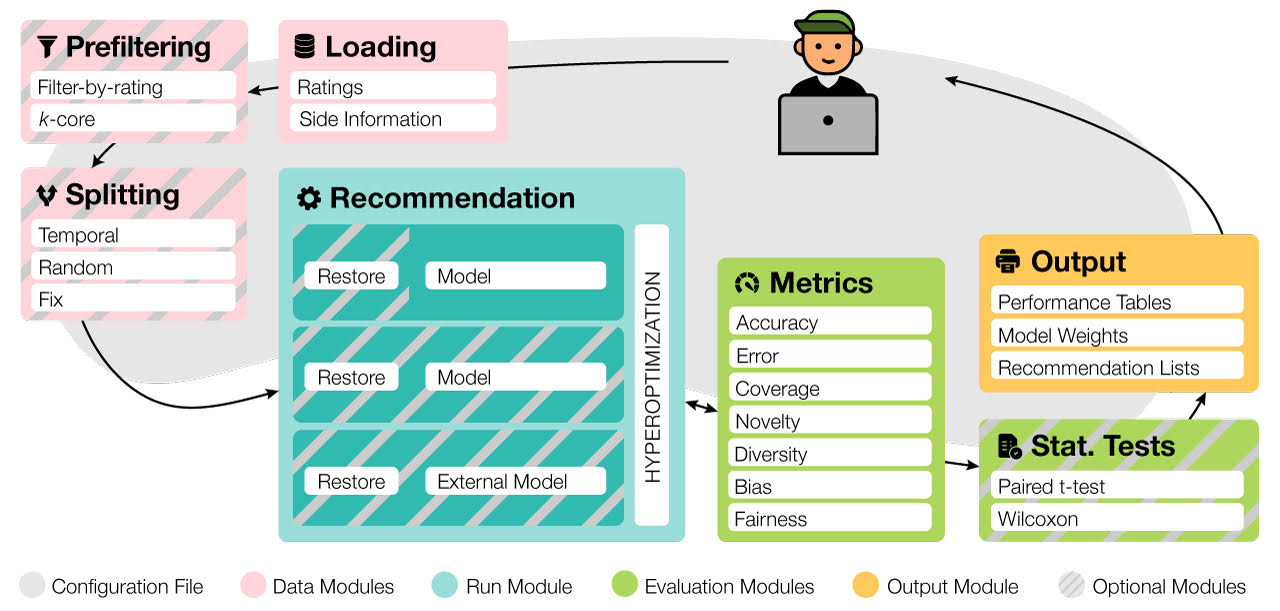
Elliot is a comprehensive recommendation framework that aims to run and reproduce an entire experimental pipeline by processing a simple configuration file. The framework loads, filters, and splits the data considering a vast set of strategies (13 splitting methods and 8 filtering approaches, from temporal training-test splitting to nested K-folds Cross-Validation). Elliot optimizes hyperparameters (51 strategies) for several recommendation algorithms (50), selects the best models, compares them with the baselines providing intra-model statistics, computes metrics (36) spanning from accuracy to beyond-accuracy, bias, and fairness, and conducts statistical analysis (Wilcoxon and Paired t-test). The aim is to provide the researchers with a tool to ease (and make them reproducible) all the experimental evaluation phases, from data reading to results collection.
RecBole - Another framework good for recommender system model experiments
RecBole is developed based on Python and PyTorch for reproducing and developing recommendation algorithms in a unified, comprehensive and efficient framework for research purpose. It can be installed from pip, Conda and source, and easy to use. It includes 65 recommendation algorithms, covering four major categories: General Recommendation, Sequential Recommendation, Context-aware Recommendation, and Knowledge-based Recommendation, which can support the basic research in recommender systems.

Features:
- General and extensible data structureWe deign general and extensible data structures to unify the formatting and usage of various recommendation datasets.
- Comprehensive benchmark models and datasetsWe implement 65 commonly used recommendation algorithms, and provide the formatted copies of 28 recommendation datasets.
- Efficient GPU-accelerated executionWe design many tailored strategies in the GPU environment to enhance the efficiency of our library.
- Extensive and standard evaluation protocolsWe support a series of commonly used evaluation protocols or settings for testing and comparing recommendation algorithms.
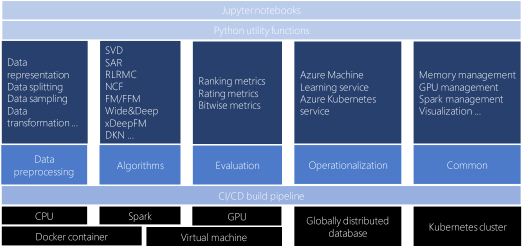
The Microsoft Recommenders repository is an open source collection of python utilities and Jupyter notebooks to help accelerate the process of designing, evaluating, and deploying recommender systems. The repository was initially formed by data scientists at Microsoft to consolidate common tools and best practices developed from working on recommender systems in various industry settings. The goal of the tools and notebooks is to show examples of how to effectively build, compare, and then deploy the best recommender solution for a given scenario. Contributions from the community have brought in new algorithm implementations and code examples covering multiple aspects of working with recommendation algorithms.
Surprise - An open-source library with easy api and powerful models
Surprise is a Python scikit for building and analyzing recommender systems that deal with explicit rating data.
Surprise was designed with the following purposes in mind:
- Give users perfect control over their experiments. To this end, a strong emphasis is laid on documentation, which we have tried to make as clear and precise as possible by pointing out every detail of the algorithms.
- Alleviate the pain of Dataset handling. Users can use both built-in datasets (Movielens, Jester), and their own custom datasets.
- Provide various ready-to-use prediction algorithms such as baseline algorithms, neighborhood methods, matrix factorization-based ( SVD, PMF, SVD++, NMF), and many others. Also, various similarity measures (cosine, MSD, pearson…) are built-in.
- Make it easy to implement new algorithm ideas.
- Provide tools to evaluate, analyse and compare the algorithms’ performance. Cross-validation procedures can be run very easily using powerful CV iterators (inspired by scikit-learn excellent tools), as well as exhaustive search over a set of parameters.
Spotlight - Another open-source library
Spotlight uses PyTorch to build both deep and shallow recommender models. By providing both a slew of building blocks for loss functions (various pointwise and pairwise ranking losses), representations (shallow factorization representations, deep sequence models), and utilities for fetching (or generating) recommendation datasets, it aims to be a tool for rapid exploration and prototyping of new recommender models.

Here is a series of hands-on tutorials to get started.
Vowpal Wabbit - library with reinforcement learning features
Vowpal Wabbit is an open source machine learning library, extensively used by industry, and is the first public terascale learning system. It provides fast, scalable machine learning and has unique capabilities such as learning to search, active learning, contextual memory, and extreme multiclass learning. It has a focus on reinforcement learning and provides production ready implementations of Contextual Bandit algorithms. It was developed originally at Yahoo! Research, and currently at Microsoft Research. Vowpal Wabbit sees significant innovation as a research to production vehicle for Microsoft Research.

For most applications, collaborative filtering yields satisfactory results for item recommendations; there are however several issues that arise that might make it difficult to scale up a recommender system.
- The number of features can grow quite large, and given the usual sparsity of consumption datasets, collaborative filtering needs every single feature and datapoint available.
- For new data points, the whole model has to be re-trained
Vowpal Wabbit’s matrix factorization capabilities can be used to build a recommender that is similar in spirit to collaborative filtering but that avoids the pitfalls that we mentioned before.
Following are the three introductory hands-on tutorials on building recommender systems with vowpal wabbit:
- Vowpal Wabbit Deep Dive - A Content-based Recommender System using Microsoft Recommender Library
- Simulating Content Personalization with Contextual Bandits
- Vowpal Wabbit, The Magic Recommender System!
DLRM - An open-source scalable model from Facebook's AI team, build on top of PyTorch
DLRM advances on other models by combining principles from both collaborative filtering and predictive analytics-based approaches, which enables it to work efficiently with production-scale data and provide state-of-art results.
In the DLRM model, categorical features are processed using embeddings, while continuous features are processed with a bottom multilayer perceptron (MLP). Then, second-order interactions of different features are computed explicitly. Finally, the results are processed with a top MLP and fed into a sigmoid function in order to give a probability of a click.
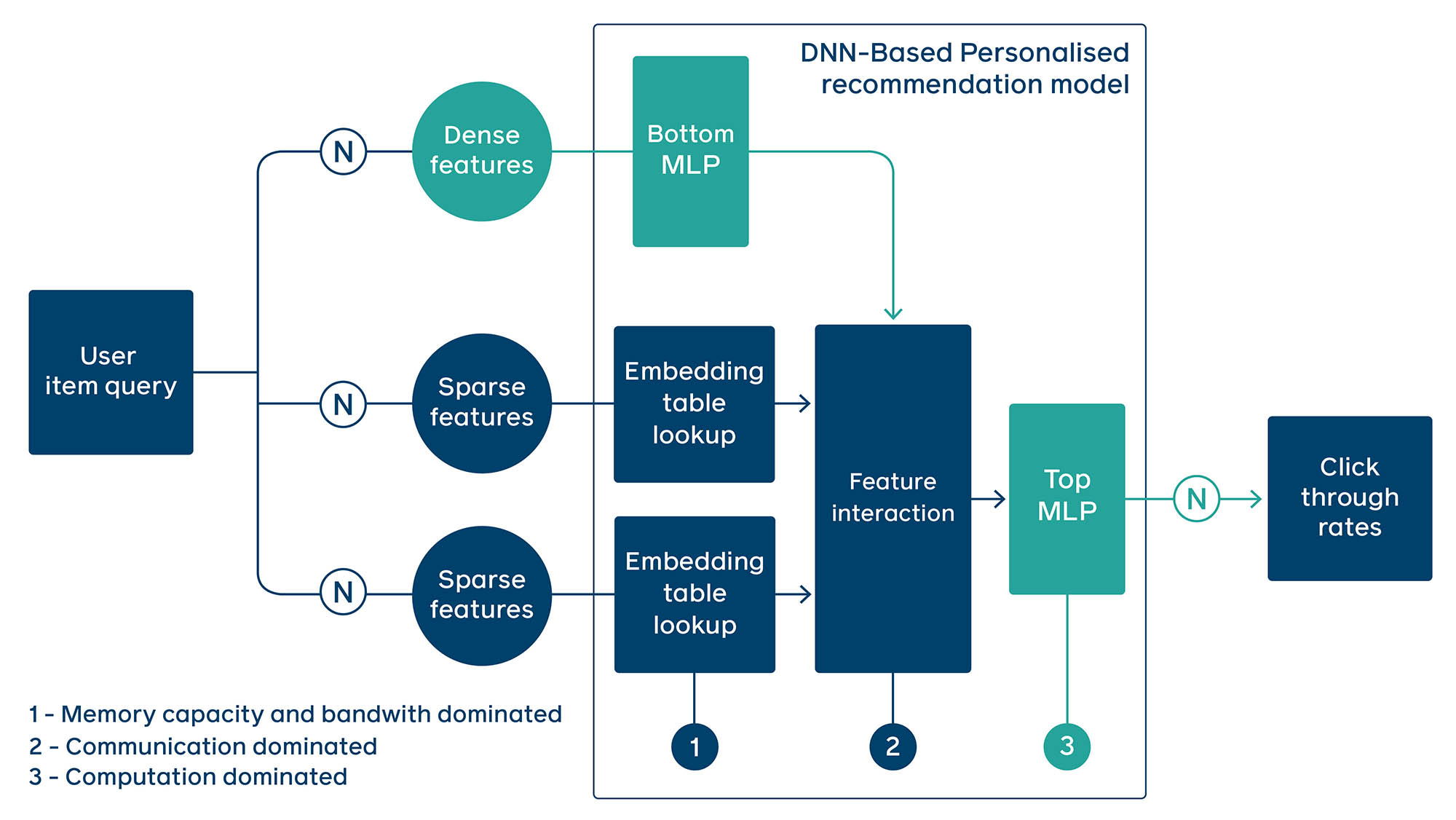
Following are the hands-on tutorials:
- https://nbviewer.jupyter.org/github/gotorehanahmad/Recommendation-Systems/blob/master/dlrm/dlrm_main.ipynb
- Training Facebook's DLRM on the digix dataset
References
- https://elliot.readthedocs.io/en/latest/
- https://vowpalwabbit.org/index.html
- https://abacus.ai/user_eng
- https://azure.microsoft.com/en-in/services/cognitive-services/personalizer/
- https://aws.amazon.com/personalize/
- https://github.com/facebookresearch/dlrm
- https://www.tensorflow.org/recommenders
- https://magento.com/products/product-recommendations
- https://cloud.google.com/recommendations
- https://www.recombee.com/
- https://recbole.io/
- https://github.com/microsoft/recommenders
- http://surpriselib.com/
- https://github.com/maciejkula/spotlight
- https://vowpalwabbit.org/tutorials/contextual_bandits.html
- https://github.com/VowpalWabbit/vowpal_wabbit/wiki
- https://vowpalwabbit.org/tutorials/cb_simulation.html
- https://vowpalwabbit.org/rlos/2021/projects.html
- https://vowpalwabbit.org/rlos/2020/projects.html
- https://getstream.io/blog/recommendations-activity-streams-vowpal-wabbit/
- https://samuel-guedj.medium.com/vowpal-wabbit-the-magic-58b7f1d8e39c
- https://vowpalwabbit.org/neurips2019/
- https://github.com/VowpalWabbit/neurips2019
- https://getstream.io/blog/introduction-contextual-bandits/
- https://www.youtube.com/watch?v=CeOcNK1xSSA&t=72s
- https://vowpalwabbit.org/blog/rlos-fest-2021.html
- https://github.com/VowpalWabbit/workshop
- https://github.com/VowpalWabbit/workshop/tree/master/aiNextCon2019
- Blog post by Nasir Mirza. Azure Cognitive Services Personalizer: Part One. Oct, 2019.
- Blog post by Nasir Mirza. Azure Cognitive Services Personalizer: Part Two. Oct, 2019.
- Blog post by Nasir Mirza. Azure Cognitive Services Personalizer: Part Three. Dec, 2019.
- Microsoft Azure Personalizer Official Documentation. Oct, 2020.
- Personalizer demo.
- Official Page.
- Blog Post by Jake Wong. Get hands on with the Azure Personalizer API. Aug, 2019.
- Medium Post.
- Blog Post.
- Git Repo.
- https://youtu.be/7hTKL73f2yA
- Deep-Learning Based Recommendation Systems — Learning AI
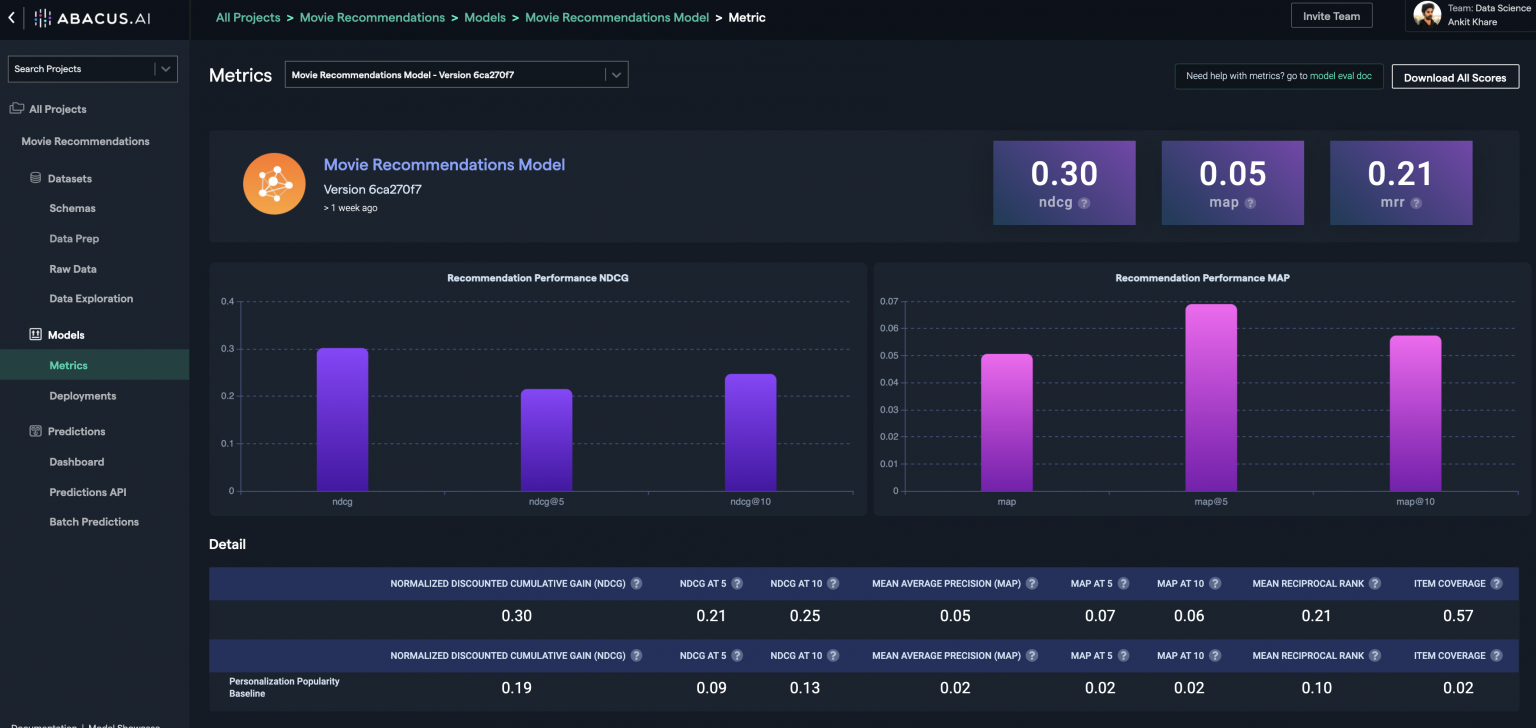
- Evaluating Deep Learning Models with Abacus.AI – Recommendation Systems
- https://aws.amazon.com/blogs/machine-learning/pioneering-personalized-user-experiences-at-stockx-with-amazon-personalize/
- https://aws.amazon.com/blogs/machine-learning/category/artificial-intelligence/amazon-personalize/
- https://d1.awsstatic.com/events/reinvent/2019/REPEAT_1_Build_a_content-recommendation_engine_with_Amazon_Personalize_AIM304-R1.pdf
- https://aws.amazon.com/blogs/aws/amazon-personalize-real-time-personalization-and-recommendation-for-everyone/
- https://d1.awsstatic.com/events/reinvent/2019/REPEAT_1_Accelerate_experimentation_with_personalization_models_AIM424-R1.pdf
- https://d1.awsstatic.com/events/reinvent/2019/REPEAT_1_Personalized_user_engagement_with_machine_learning_AIM346-R1.pdf
- https://github.com/aws-samples/amazon-personalize-samples
- https://github.com/aws-samples/amazon-personalize-automated-retraining
- https://github.com/aws-samples/amazon-personalize-ingestion-pipeline
- https://github.com/aws-samples/amazon-personalize-monitor
- https://github.com/aws-samples/amazon-personalize-data-conversion-pipeline
- https://github.com/james-jory/segment-personalize-workshop
- https://github.com/aws-samples/amazon-personalize-samples/tree/master/next_steps/workshops/POC_in_a_box
- https://github.com/Imagination-Media/aws-personalize-magento2
- https://github.com/awslabs/amazon-personalize-optimizer-using-amazon-pinpoint-events
- https://github.com/aws-samples/amazon-personalize-with-aws-glue-sample-dataset
- https://github.com/awsdocs/amazon-personalize-developer-guide
- https://github.com/chrisking/NetflixPersonalize
- https://github.com/aws-samples/retail-demo-store
- https://github.com/aws-samples/personalize-data-science-sdk-workflow
- https://github.com/apac-ml-tfc/personalize-poc
- https://github.com/dalacan/personalize-batch-recommendations
- https://github.com/harunobukameda/Amazon-Personalize-Handson
- https://www.sagemakerworkshop.com/personalize/
- https://github.com/lmorri/vodpocinabox
- https://github.com/awslabs/unicornflix
- https://www.youtube.com/watch?v=r9J3UZmddC4&t=966s
- https://www.youtube.com/watch?v=kTufCK76Yus&t=1436s
- https://www.youtube.com/watch?v=hY_XzglTkak&t=66s
- https://business.adobe.com/lv/summit/2020/adobe-sensei-powers-magento-product-recommendations.html
- https://magento.com/products/product-recommendations
- https://docs.magento.com/user-guide/marketing/product-recommendations.html
- https://vod.webqem.com/detail/videos/magento-commerce/video/6195503645001/magento-commerce---product-recommendations?autoStart=true&page=1
- https://blog.adobe.com/en/publish/2020/11/23/new-ai-capabilities-for-magento-commerce-improve-retail.html#gs.yw6mtq
- https://developers.google.com/recommender/docs/reference/rest
- https://www.youtube.com/watch?v=nY5U0uQZRyU&t=6s

.](/recohut/assets/images/content-blog-raw-blog-distributed-training-of-recommender-systems-untitled-1-64afd6c4cb479b89e18f624461bb9641.png)