
The usage and importance of recommender systems are increasing at a fast pace. And deep learning is gaining traction as the preferred choice for model architecture. Giants like Google and Facebook are already using recommenders to earn billions of dollars.
Recently, Facebook shared its approach to maintain its 12 trillion parameter recommender. Building these large systems is challenging because it requires huge computation and memory resources. And we will soon enter into 100 trillion range. And SMEs will not be left behind due to open-source environment of software architectures and the decreasing cost of hardware, especially on the cloud infrastructure.
As per one estimate, a model with 100 trillion parameters would require at least 200TB just to store the model, even at 16-bit floating-point accuracy. So we need architectures that can support efficient and distributed training of recommendation models.
Memory-intensive vs Computation-intensive: The increasing parameter comes mostly from the embedding layer which maps each entrance of an ID type feature (such as an user ID and a session ID) into a fixed length low-dimensional embedding vector. Consider the billion scale of entrances for the ID type features in a production recommender system and the wide utilization of feature crosses, the embedding layer usually domains the parameter space, which makes this component extremely memory-intensive. On the other hand, these low-dimensional embedding vectors are concatenated with diversified Non-ID type features (e.g., image, audio, video, social network, etc.) to feed a group of increasingly sophisticated neural networks (e.g., convolution, LSTM, multi-head attention) for prediction(s). Furthermore, in practice, multiple objectives can also be combined and optimized simultaneously for multiple tasks. These mechanisms make the rest neural network increasingly computation-intensive.
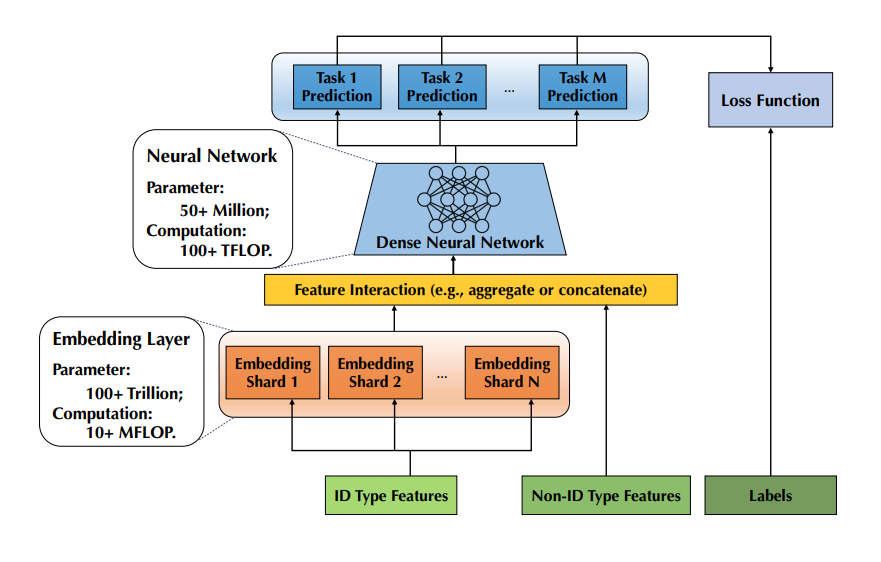
An example of a recommender models with 100+ trillions of parameter in the embedding layer and 50+ TFLOP computation in the neural network.
Alibaba's XDL, Baidu's PaddleRec, and Kwai's Persia are some open-source frameworks for this large-scale distributed training of recommender systems.
Parameter Server Framework
Existing distributed systems for deep learning based recommender models are usually built on top of the parameter server (PS) framework, where one can add elastic distributed storage to hold the increasingly large amount of parameters of the embedding layer. On the other hand, the computation workload does not scale linearly with the increasing parameter scale of the embedding layer—in fact, with an efficient implementation, a lookup operation over a larger embedding table would introduce almost no additional computations.
.](/recohut/assets/images/content-blog-raw-blog-distributed-training-of-recommender-systems-untitled-1-64afd6c4cb479b89e18f624461bb9641.png)
Left: deep learning based recommender model training workflow over a heterogeneous cluster. Right: Gantt charts to compare fully synchronous, fully asynchronous, raw hybrid and optimized hybrid modes of distributed training of the deep learning recommender model. Source.
PERSIA
PERSIA (Parallel rEcommendation tRaining System with hybrId Acceleration) is a PyTorch-based system for training deep learning recommendation models on commodity hardware. It supports models containing more than 100 trillion parameters.
It uses a hybrid training algorithm to tackle the embedding layer and dense neural network modules differently—the embedding layer is trained in an asynchronous fashion to improve the throughput of training samples, while the rest neural network is trained in a synchronous fashion to preserve the statistical efficiency.
It also uses a distributed system to manage the hybrid computation resources (CPUs and GPUs) to optimize the co-existence of asynchronicity and synchronicity in the training algorithm.


Persia includes a data loader module, a embedding PS (Parameter Server) module, a group of embedding workers over CPU nodes, and a group of NN workers over GPU instances. Each module can be dynamically scaled for different model scales and desired training throughput:
- A data loader that fetches training data from distributed storages such as Hadoop, Kafka, etc;
- A embedding parameter server (embedding PS for short) manages the storage and update of the parameters in the embedding layer $\mathrm{w}^{emb}$;
- A group of embedding workers that runs Algorithm 1 for getting the embedding parameters from the embedding PS; aggregating embedding vectors (potentially) and putting embedding gradients back to embedding PS;
- A group of NN workers that runs the forward-/backward- propagation of the neural network $\mathrm{NN_{w^{nn}}(·)}$.
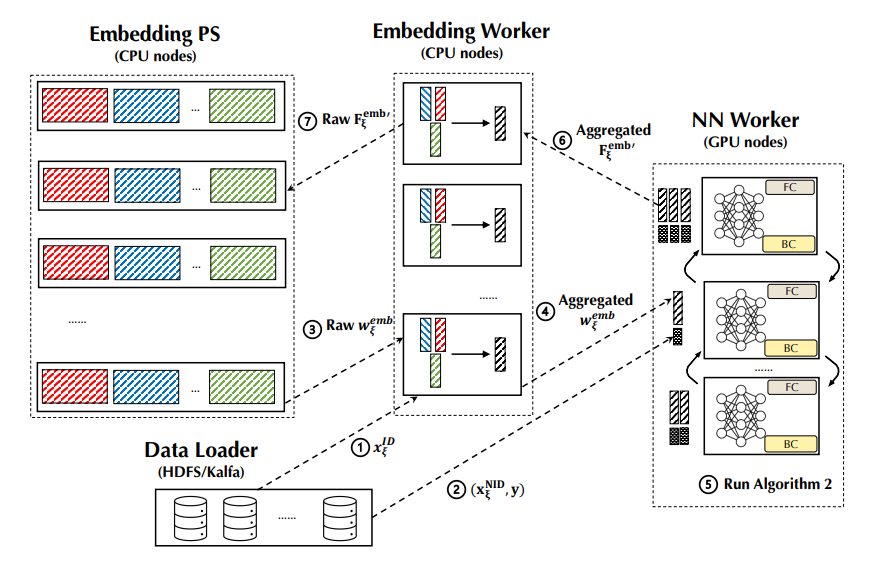
The architecture of Persia.
Logically, the training procedure is conducted by Persia in a data dispatching based paradigm as below:
- The data loader will dispatch the ID type feature $\mathrm{x^{ID}}$ to an embedding worker—the embedding worker will generate an unique sample ID 𝜉 for this sample, buffer this sample ID with the ID type feature $\mathrm{x_\xi^{ID}}$ locally, and returns this ID 𝜉 back the data loader; the data loader will associate this sample’s Non-ID type features and labels with this unique ID.
- Next, the data loader will dispatch the Non-ID type feature and label(s) $\mathrm{(x\xi^{NID},y\xi)}$ to a NN worker.
- Once a NN worker receives this incomplete training sample, it will issue a request to pull the ID type features’ $\mathrm{(x\xi^{ID})}$ embedding $\mathrm{w\xi^{emb}}$ from some embedding worker according to the sample ID 𝜉—this would trigger the forward propagation in Algorithm 1, where the embedding worker will use the buffered ID type feature $\mathrm{x\xi^{ID}}$ to get the corresponding $\mathrm{w\xi^{emb}}$ from the embedding PS.
- Then the embedding worker performs some potential aggregation of original embedding vectors. When this computation finishes, the aggregated embedding vector $\mathrm{w_\xi^{emb}}$ will be transmitted to the NN worker that issues the pull request.
- Once the NN worker gets a group of complete inputs for the dense module, it will create a mini-batch and conduct the training computation of the NN according to Algorithm 2. Note that the parameter of the NN always locates in the device RAM of the NN worker, where the NN workers synchronize the gradients by the AllReduce Paradigm.
- When the iteration of Algorithm 2 is finished, the NN worker will send the gradients of the embedding ($\mathrm{F_\xi^{emb'}}$) back to the embedding worker (also along with the sample ID 𝜉).
- The embedding worker will query the buffered ID type feature $\mathrm{x\xi^{ID}}$ according to the sample ID 𝜉; compute gradients $\mathrm{F\xi^{emb'}}$ of the embedding parameters and send the gradients to the embedding PS, so that the embedding PS can finally compute the updates according the embedding parameter’s gradients by its SGD optimizer and update the embedding parameters.